
英偉達(dá)CV公開課第2期:快速搭建情感識別系統(tǒng)
在計算機視覺領(lǐng)域,機器可通過采集面部表情、肢體動作等來識別人類情感。而其中,面部表情識別具有很大的應(yīng)用價值,更是備受關(guān)注。
近期,英偉達(dá)x量子位發(fā)起了系列CV公開課,在第二期課程中,NVIDIA開發(fā)者社區(qū)的何琨老師分享了如何利用TLT 3.0、Triton等工具低門檻、快速搭建和部署情感識別系統(tǒng)。
分享大綱如下:
· 情感識別任務(wù)介紹
· NVIDIA Transfer Learning Toolkit工具簡介
· NVIDIA Triton工具介紹
· 實戰(zhàn)演示:利用TLT和Triton快速搭建情感識別系統(tǒng)
· 下期直播報名
以下為分享內(nèi)容整理:
大家好,我是來自NVIDIA開發(fā)者社區(qū)的何琨,很高興與大家參與今天的直播。我主要負(fù)責(zé)與各位開發(fā)者朋友交流溝通,如果大家對我們的產(chǎn)品有什么建議、或者有哪些需求,也期待反饋給我們。
情感識別任務(wù)
今天分享的內(nèi)容是“快速搭建情感識別系統(tǒng)”,即通過對人物的面部表情進(jìn)行識別,判斷出人物當(dāng)前的情感狀態(tài)。
在深度學(xué)習(xí)里,情感識別是一個比較簡單的項目,但是仍然涉及到非常多的流程和步驟。今天我將通過這個案例,向大家分享如何利用NVIDIA的工具包快速、高效率地實現(xiàn)這一任務(wù)。
今天的任務(wù)將會用到兩個工具包:Transfer Learning Toolkit 3.0和 Triton。
分享過程中,首先會為新來的朋友介紹下這兩個工具,然后通過代碼實例,向大家展示如何利用這兩個工具,簡單、高效地實現(xiàn)AI模型的訓(xùn)練與部署。
課程后大家可以利用我們提供的代碼、親手操作一遍。(課程中所需的代碼見本文末)
Transfer Learning Toolkit
Transfer Learning Toolkit(TLT)是一個簡單的、集成化的工具,可以幫助大家簡化深度學(xué)習(xí)模型的開發(fā)流程。Develop like a pro with zero coding,利用TLT不需要太多編程的內(nèi)容就可以實現(xiàn)AI模型訓(xùn)練、優(yōu)化與導(dǎo)出。
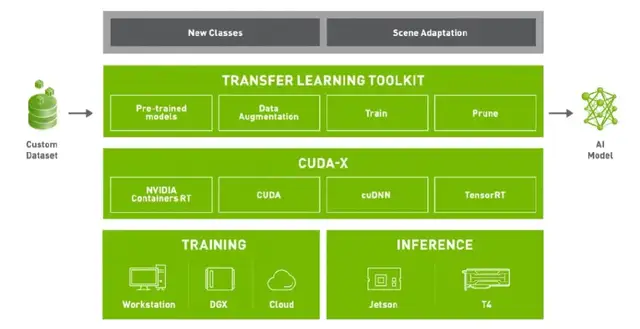
Transfer Learning Toolkit強調(diào)的Transfer Learning,即遷移式學(xué)習(xí),它的主要特點是為開發(fā)者提供了大量預(yù)訓(xùn)練模型。開發(fā)者可以結(jié)合自己的數(shù)據(jù)集,根據(jù)不同的使用場景和需求,在這些預(yù)訓(xùn)練模型的基礎(chǔ)上進(jìn)行模型訓(xùn)練、調(diào)整、剪枝,以及導(dǎo)出模型進(jìn)行部署等。而且大家可以通過簡單的幾行代碼來實現(xiàn)上述功能。
TLT有幾個主要的特點:
第一,在異構(gòu)的多GPU環(huán)境下進(jìn)行模型調(diào)整與重新訓(xùn)練。只通過一兩個命令,就能夠?qū)Χ郍PU進(jìn)行合理的利用和分配。
第二,豐富的預(yù)訓(xùn)練模型庫。包含大量的常見任務(wù)模型,在視覺、語音等方面都有很多可以實際應(yīng)用的模型。大家可以在NGC上免費下載(ngc.nvidia.com)。
第三,優(yōu)化模型。一方面可以利用TLT修剪、縮小模型尺寸;另一方面,可以將模型轉(zhuǎn)化成TensorRT、DeepStream、Triton等可以直接使用的深度學(xué)習(xí)推理引擎,方便部署。
Triton工具簡介
Triton是我們今天完成課程任務(wù)需要的另一個工具。
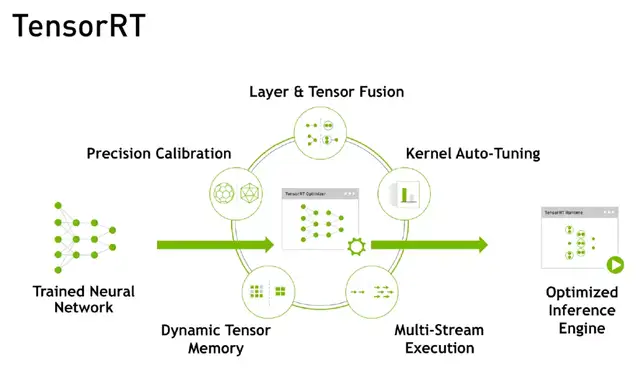
Triton的前身是TensorRT Inference Server平臺,是一個基于TensorRT的推理服務(wù)引擎。TensorRT是NVIDIA專門為GPU在深度學(xué)習(xí)推理階段的加速而開發(fā)的引擎,能夠讓GPU發(fā)揮出更強大計算能力。
TensorRT主要通過5個步驟實現(xiàn)對GPU推理過程的優(yōu)化:精度校正、動態(tài)Memory管理、多流的執(zhí)行、Kernel參數(shù)的調(diào)優(yōu)、網(wǎng)絡(luò)層融合計算。通過這一系列步驟,在速度和吞吐量上對推理模型進(jìn)行優(yōu)化。
而Triton推理服務(wù)器能夠簡化AI模型的大規(guī)模部署流程,開發(fā)者可以從本地存儲或云平臺的任何框架部署訓(xùn)練好的AI模型,或基于GPU、CPU的基礎(chǔ)設(shè)施。
Triton更像是一個即時響應(yīng)的、Web Request的工具。它的應(yīng)用場景主要是網(wǎng)頁端、遠(yuǎn)程的數(shù)據(jù)中心,當(dāng)然也支持嵌入式平臺。能夠大幅簡化模型部署流程,搭建好之后只需調(diào)用其中的接口,不需要再操心模型的訓(xùn)練及優(yōu)化。
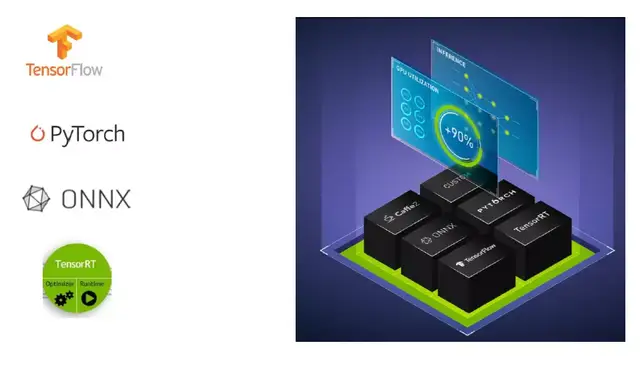
特點一:支持多種框架。Triton支持市面上幾乎所有的框架,比如常見的TensorFlow、Pytorch、ONNX等,也支持一些自定義的框架。

特點二:高性能的推理能力。Triton的推理能力不僅速度快,吞吐量也很高。可以極大加快集群的運行效率和執(zhí)行效率。
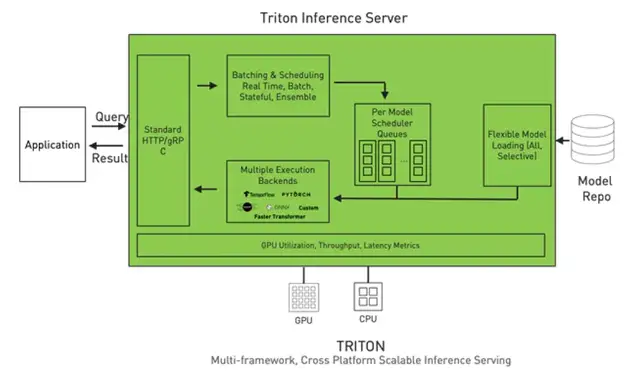
特點三:簡化模型部署流程。上圖是 Triton的架構(gòu),可以看到,Triton將深度學(xué)習(xí)處理的流程封裝在一起了,部署在我們的服務(wù)器上。開發(fā)者只需幾步即可完成部署:
第一,準(zhǔn)備模型庫。
第二,調(diào)用接口加載模型。啟動Triton Inference Server時,模型的序列、參數(shù)、執(zhí)行方案等一系列內(nèi)容即可直接加載完成。
它的優(yōu)點是,能夠?qū)⒛P蛶旌褪褂眠@個模型的流程區(qū)分開。對于一些項目團隊來說,有人擅長做算法,有人擅長做前端,但只要算法工程師將模型訓(xùn)練好,前端不需要懂得如何優(yōu)化模型算法,只需要通過Triton調(diào)用接口就可以。
其次,在多線程執(zhí)行時,Triton Server也能夠自動分配好GPU的內(nèi)存,減少安全隱患、降低能耗。
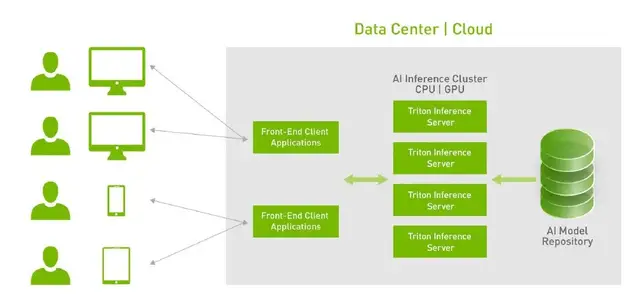
特點四:動態(tài)可擴展性。假設(shè)我們搭建好的兩臺服務(wù)器可以服務(wù)現(xiàn)有的10萬用戶,但是當(dāng)用戶量快速增加到100萬時,我們只需要再增加幾臺服務(wù)器,直接通過Docker等方式擴展到新的服務(wù)器上。
實戰(zhàn)演示:搭建情感識別系統(tǒng)
下面,我們將通過一份簡單的代碼,調(diào)用TLT和Triton工具來實現(xiàn)情感識別模型的訓(xùn)練與部署。
代碼鏈接:
1、https://ngc.nvidia.com/resources/nvidia:tlt_cv_inference_pipeline_quick_start
2、https://github.com/triton-inference-server/server
接下來,何琨老師通過代碼講解,向大家展示了如何借助TLT和Triton完成面部情感識別系統(tǒng)的訓(xùn)練與部署。大家可觀看視頻、繼續(xù)學(xué)習(xí):
直播回放:
p.s.代碼演示部分從第35分鐘開始~
相關(guān)閱讀

如果你想做大模型時代的應(yīng)用層創(chuàng)業(yè)......|量子位·視點 x 一覽科技
5月18日周四19:00,開始線上直播!



黃仁勛回應(yīng)AMD送股OpenAI:很高明的交易,OpenAI沒錢給我付賬
英偉達(dá)自己也深度參與的這場被市場稱為“循環(huán)交易”的游戲

老黃再收95后華人才俊!4億美元收購AI初創(chuàng)公司
該公司CentML專門負(fù)責(zé)優(yōu)化AI應(yīng)用程序的運行方式




