
Jeff Dean被迫發論文自證:解雇黑人員工純屬學術原因
其實挖礦污染更嚴重
蕭簫 發自 凹非寺
量子位 報道 | 公眾號 QbitAI
還記得去年12月,Jeff Dean在網上成為“千夫所指”嗎?
當時谷歌一名員工Timnit Gebru準備發表一篇AI倫理論文,結果雙方內部評審上存在著嚴重分歧,Jeff Dean就把她開除了。

這篇論文指出了大語言模型訓練時,造成的碳排放量和能源消耗量過于巨大,還談到了谷歌BERT在AI倫理上的負面影響。
不到幾天,已有1400名谷歌員工和1900名AI學術圈人士對谷歌的行為表示譴責,一向口碑不錯的Jeff Dean,也因此成了眾矢之的。
現在,Jeff Dean終于“有理有據”了——
他親自下場,對Gebru的論文進行了指正,表明她統計碳排放量和能源消耗的方法“不合理”,并將結果寫成了一篇新的論文。

近日,谷歌聯合加州大學伯克利分校,撰寫了一篇新論文,仔細研究了AI模型對環境的影響,并得出結果表明:
AI模型,不會顯著增加碳排放。
論文指出,Gebru的論文對AI模型產生的碳排放量估算不合理。

“如果數據中心、處理器和模型選擇得當,甚至能將碳排放量降低為原來的百分之一。”
“此前評估方法不嚴謹”
Jeff Dean的這篇論文,同樣選擇了NLP模型進行研究。
這項研究,將模型的碳排放量定義成多變量函數,(每個變量都對結果有影響)這些變量包括:
算法選擇、實現算法的程序、運行程序所需的處理器數量、處理器的速度和功率、數據中心供電和冷卻的效率以及供能來源(如可再生能源、天然氣或煤炭)。
也就是說,碳排放與很多因素都有關系。

而此前的研究,對模型的評估方法有誤,尤其是對基于NAS的模型訓練方法理解有誤。
以基于NAS方法的Transformer為例,研究者們經過重新評估后,發現碳排放量可以降為原來的八十八分之一。
研究者們還表示,采用新公式估計機器學習模型的碳排放量的話,凈排放量可以降低10倍。
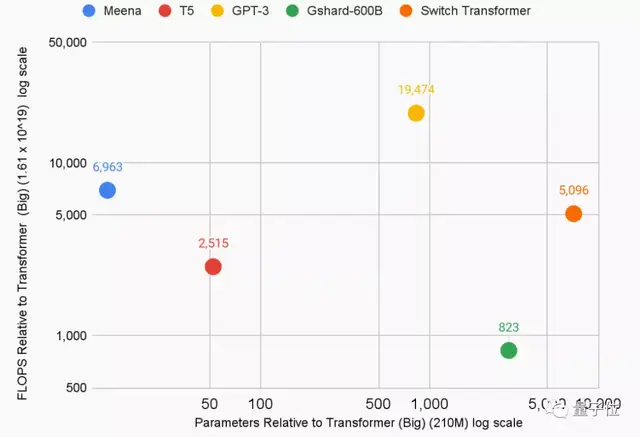
采用新公式,研究者們重新估計了5個大語言模型的能源使用量和二氧化碳排放量:
- T5,谷歌預訓練語言模型,86MW,47噸
- Meena,谷歌的26億參數對話機器人,232MW,96噸
- GShard,谷歌語言翻譯框架,24MW,4.3噸
- Switch Transformer,谷歌路由算法,179MW,59噸
- GPT-3,OpenAI大語言模型,1287MW,552噸
不過,即使谷歌的碳排放量,真是Jeff Dean這篇論文統計的結果,這些模型訓練導致的二氧化碳排放總量也已經超過200噸。
甚至OpenAI的一個GPT-3模型,就已經達到了這個數值。
這相當于43輛車、或是24個家庭在一年內的碳排放量。
論文還表示,谷歌會繼續不斷提高模型質量、改進方法,來降低訓練對環境造成的影響。
例如,谷歌對Transformer改進后的Evolved Transformer模型,每秒所用的浮點計算降低了1.6倍,訓練時間也減少了1.1~1.3倍。
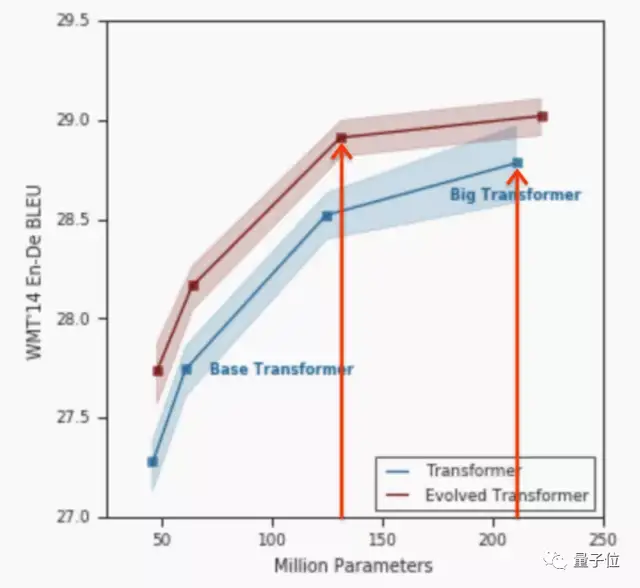
除此之外,稀疏激活(讓信息編碼中更多元素為0或趨近于0)也同樣能降低模型能耗,甚至最多能降低55倍的能源消耗、減少約130倍的凈碳排放量。
這篇論文,還引用了發表在Science上的一篇論文:
即使算力已經被增加到原來的550%,但全球數據中心的能源消耗僅比2010年增長了6%。
論文最后給出的建議如下:
需要大量計算資源的機器學習模型,在實際應用中,應該明確“能源消耗”和“二氧化碳排放量”的具體數值,這兩者都應該成為評估模型的關鍵指標。
所以,Jeff Dean忽然參與到碳排放量研究中,到底是怎么回事?
與谷歌利益相沖突
事實上,這篇論文是對此前Timnit Gebru合著的一篇論文的“指正”。

Gebru那篇論文的標題,名為「On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?」(隨機鸚鵡的危險:語言模型會太大嗎?)
論文提出,自然語言模型存在“四大風險”:
- 環境和經濟成本巨大
- 海量數據與模型的不可解釋性
- 存在研究機會成本
- 語言AI可能欺騙人類
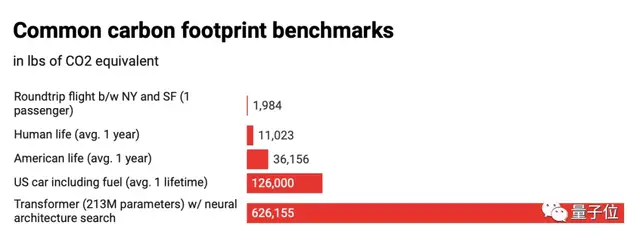
論文表明,使用神經網絡結構搜索方法(NAS)的語言模型,會產生相當于284噸的二氧化碳,相當于5輛汽車在其壽命內的碳排放量。
論文還以谷歌的NLP模型BERT為例,指出它會在AI倫理上會產生一系列負面影響:
它排放的1823磅二氧化碳量,相當于紐約到舊金山航班往返的碳排放量。
這篇論文被認為顯然不符合谷歌的商業利益。
谷歌此前開發過許多AI模型,包括云翻譯和NLP語言對話模型等,而谷歌云業務,還在2021年Q1收入增長了46%,達到40.4億美元。
論文被送到谷歌相關部門審核,但過了兩個月,卻一直沒有得到反饋。
2020年12月,Gebru忽然被解雇。
Jeff Dean表示,Gebru的論文存在著一些漏洞,只提到了BERT,卻沒有考慮到后來的模型能提高效率、以及此前的研究已經解決了部分倫理問題。

而開除原因,則是因為“她要求提供這篇論文的審核人員名單,否則將離職。”
Jeff Dean表示,谷歌無法滿足她的要求。
這件事一直發酵到現在,Jeff Dean也正式給出了論文,“學術地”回應了這件事情。
和挖礦相比如何?
據Venturebeat報道,此前研究表明,用于訓練NLP和其他AI模型的計算機數量,在6年內增長了30萬倍,比摩爾定律還要快。
MIT的一項研究人員認為,這表明深度學習正在接近它的“計算極限”。
不過,商業巨頭們也不是完全沒有行動。
OpenAI的前老板馬斯克,最近還懸賞了1億美元,來開展碳清除技術比賽,比賽將持續到2025年。

這場主辦方是XPRIZE的比賽,鼓勵研究碳清除技術,來消除大氣和海洋中的二氧化碳,以對付全球氣候變暖的事實。
但這項技術,目前還不具備商業可行性。
據路透社表示,光是去除一噸碳,就需要花費超過300美元的成本,而全世界一年排放的溫室氣體,相當于約500億噸二氧化碳。
那么,產生的這些碳排放量,和挖礦相比如何呢?
據Nature上的一項研究顯示,到2024年,中國的比特幣挖礦產業可能產生多達1.305億噸的碳排放量,相當于全球每年飛行產生的碳排放量的14%。

具體到年份的話,到2024年,全球挖礦產生的能量將達到每年350.11TWh(1太瓦時=10^9×千瓦時)。

而據Venturebeat的報道,訓練機器學習模型耗費的能量,每年估計也將達到200TWh。
對比一下的話,一個美國家庭平均每年消耗的能量僅僅是0.00001TWh。
看來,挖礦造成的環境污染,確實要比機器學習模型更嚴重……
論文地址:
https://arxiv.org/abs/2104.10350
參考鏈接:
[1]https://venturebeat.com/2021/04/29/google-led-paper-pushes-back-against-claims-of-ai-inefficiency/
[2]https://www.reuters.com/article/musk-offering-prize-carbon-removal-0422-idCNKBS2CA025
[3]https://www.nature.com/articles/s41467-021-22256-3
- 首個GPT-4驅動的人形機器人!無需編程+零樣本學習,還可根據口頭反饋調整行為2023-12-13
- IDC霍錦潔:AI PC將顛覆性變革PC產業2023-12-08
- AI視覺字謎爆火!夢露轉180°秒變愛因斯坦,英偉達高級AI科學家:近期最酷的擴散模型2023-12-03
- 蘋果大模型最大動作:開源M芯專用ML框架,能跑70億大模型2023-12-07










