
明朝版“今日頭條”,這個(gè)北航校友的開源AI腦洞很大
用來處理文言文的算法,竟是用現(xiàn)代漢語數(shù)據(jù)訓(xùn)練的?
賈浩楠 發(fā)自 凹非寺
量子位 報(bào)道 | 公眾號 QbitAI
下面這段明朝萬歷年間的“今日頭條”,你能看懂嗎?

這條明朝新聞所講的,其實(shí)是:
小本生意免稅條約未能落實(shí),小商販被嚴(yán)重剝削,以致百姓聚眾鬧事并火燒衙門,造成多人傷亡。王煬 搶救出公章。
還有另外一條:

這條新聞?wù)f的是:
陜西天鼓鳴。
這些明朝的“一句話”新聞,都是一個(gè)名叫HistSumm的AI算法,根據(jù)文言文提煉出來的摘要。
生成文本摘要的NLP見得多了,古漢語摘要總結(jié)還是第一次。這項(xiàng)研究來自就讀于英國謝菲爾德大學(xué)的北航校友,以及北航計(jì)算機(jī)系的團(tuán)隊(duì),和英國開放大學(xué)。
這項(xiàng)研究最神奇的是,用來處理文言文的算法,是用現(xiàn)代漢語數(shù)據(jù)訓(xùn)練的。
這個(gè)AI,會寫明朝新聞
這篇論文題目是Summarising Historical Text in Modern Languages,文中提出的核心算法名為HistSumm。
研究團(tuán)隊(duì)分別以古德語和古漢語作為目標(biāo)語言,來實(shí)現(xiàn)算法的摘要提取。
其中,古漢語部分的測試結(jié)果,選用了明朝歷史文獻(xiàn)。
《萬歷邸抄》,是明萬歷年間的“今日頭條”,抄錄自當(dāng)時(shí)的官方“邸報(bào)”。內(nèi)容包括皇帝詔諭、民生百態(tài)、軍事外交等等。

團(tuán)隊(duì)使用HistSumm,對《萬歷邸抄》中的100多段文言文進(jìn)行了摘要提煉。
比如這一段:

其中,story是原文,Expert是人類專家給出的摘要。
HistSumm在“相同詞匯對”(Identical Mapping)的映射方法下,給出的結(jié)果是:
宋應(yīng)昌撤兵自朝鮮回京。
IdMap+CONV(CONV指簡繁漢字轉(zhuǎn)換增強(qiáng)語料庫訓(xùn)練)給出的結(jié)果也是:
宋應(yīng)昌撤兵自朝鮮回京。
怎么樣,摘要是不是能直接上標(biāo)題了?
再看另一個(gè)例子:

HistSumm給出的摘要為:
高拱不忠,已死了,他妻還來乞恩,不準(zhǔn)他。
高拱不忠,不準(zhǔn)他妻來乞恩。
以上兩個(gè)結(jié)果也分別是IdMap、IdMap+CONV給出的結(jié)果。
可以看出,算法對于一段文言文主要的人物 、事件、關(guān)系都能準(zhǔn)確把握,只是偶然會遺漏一些細(xì)節(jié)。
在與最出色的跨語言學(xué)習(xí)模型XLM的結(jié)果對比中,HistSumm的表現(xiàn)都有所超越:
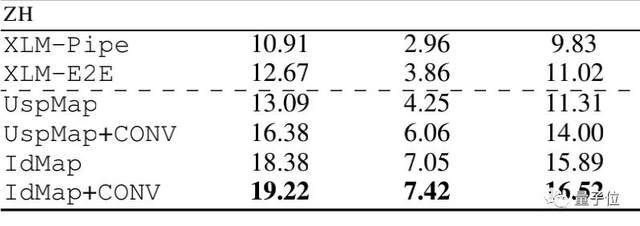
△結(jié)果分別在ROUGE1、ROUGE2、ROUGEL基準(zhǔn)下得到
實(shí)驗(yàn)方法與思路
對古漢語進(jìn)行摘要?dú)v練的HistSumm,它的訓(xùn)練數(shù)據(jù),其實(shí)大部分都是現(xiàn)代漢語。
這是因?yàn)椋晒┠P陀?xùn)練的古漢語數(shù)據(jù)集,實(shí)在太少了。
于是,研究團(tuán)隊(duì)構(gòu)建了一個(gè)跨語言遷移學(xué)習(xí)框架。
第一步,訓(xùn)練模型的現(xiàn)代和古漢語單詞嵌入
對于像中文這樣的表意語言,基于筆畫(類似于字母語言的單詞信息)訓(xùn)練的詞嵌入是實(shí)現(xiàn)最佳性能的途徑。因此團(tuán)隊(duì)利用筆畫信息來提取漢字的特征向量。
此外,還有一點(diǎn)很重要。與簡化字(在訓(xùn)練資源中占主導(dǎo))相比,繁體字通常有更豐富的筆畫,例如,“葉”字,包含’艸’(植物)和’木’(木)的語義相關(guān)成分,而它的簡化版本(’葉’)則沒有。
繁體字的這些特性,有利于基于筆畫的嵌入方式。所以為了提高模型的性能,團(tuán)隊(duì)還對繁體化的漢字進(jìn)行了額外的實(shí)驗(yàn)。
建立特征向量空間
接下來,團(tuán)隊(duì)為模型建立了兩個(gè)語義空間,空間中的特征向量既來自現(xiàn)代漢語,也有古漢語。
對于特征向量,主要采取兩種引導(dǎo)策略:完全無監(jiān)督(UspMap)的方式和相同詞匯對(IdMap)方式。
前者只依賴于輸入向量之間的拓?fù)湎嗨菩裕笳邉t額外利用古今同意的詞作為依據(jù)。
使用現(xiàn)代漢語數(shù)據(jù)集訓(xùn)練
訓(xùn)練階段,團(tuán)隊(duì)使用了現(xiàn)代漢語數(shù)據(jù)集CSTS,訓(xùn)練了一個(gè)只接受現(xiàn)代漢語輸入的總結(jié)器。
編碼器的嵌入權(quán)重,在建立特征空間時(shí),用相應(yīng)的跨語言詞向量的現(xiàn)代語分區(qū)進(jìn)行初始化。
而解碼器的嵌入權(quán)重則是隨機(jī)初始化的,可以通過反向傳播更新。
最后,就是模型的收斂。
團(tuán)隊(duì)直接將編碼器的嵌入權(quán)重替換為向量空間中的古漢語特征向量,得到一個(gè)新的模型。這個(gè)模型可以用古漢語輸入,但輸出現(xiàn)代漢語句子,并且整個(gè)過程不需要任何外部并行監(jiān)督。
簡單的總結(jié)一下,團(tuán)隊(duì)讓模型能理解古文的關(guān)鍵,是在特征向量空間中,建立互相聯(lián)系的古漢語-現(xiàn)代漢語詞匯對。然后再用現(xiàn)代漢語數(shù)據(jù)訓(xùn)練模型,之后替換掉對應(yīng)的特征向量。
北航校友科研成果
本研究的第一作者Xutan Peng,目前是英國謝菲爾德大學(xué)在讀博士生,研究方向是自然語言處。
Xutan Peng本科就讀于北京航空航天大學(xué)計(jì)算機(jī)系。
而本文的共同作者中,也有來自北航計(jì)算機(jī)系的Yi Zheng。

論文的另一作者,謝菲爾德大學(xué)的Lin Chenghua老師,本科也畢業(yè)于北航計(jì)算機(jī)系。
本文通訊作者Advaith Siddharthan博士,是英國開放大學(xué)Knowledge Media Institute的研究院。
論文地址:
https://arxiv.org/abs/2101.10759
開源代碼:
https://github.com/Pzoom522/HistSumm
- 空間智能卡脖子難題被杭州攻克!難倒GPT-5后,六小龍企業(yè)出手了2025-08-28
- 陳丹琦有了個(gè)公司郵箱,北大翁荔同款2025-08-28
- 英偉達(dá)最新芯片B30A曝光2025-08-20
- AI應(yīng)用如何落地政企?首先不要卷通用大模型2025-08-12
相關(guān)閱讀


32專家MoE大模型免費(fèi)商用!性能全面對標(biāo)Llama3,單token推理消耗僅5.28%
堅(jiān)持算法和架構(gòu)創(chuàng)新,將開源進(jìn)行到底

全球首個(gè)類Sora開源復(fù)現(xiàn)方案來了!全面公開訓(xùn)練細(xì)節(jié)和模型權(quán)重
詳細(xì)上手教程已發(fā)布在GitHub



國產(chǎn)開源模型標(biāo)桿大升級,重點(diǎn)能力比肩ChatGPT!書生·浦語2.0發(fā)布,支持免費(fèi)商用
共計(jì)6個(gè)模型全開放




