ICML最佳論文曾被ICLR拒稿,Pika聯創參與,一作已入職OpenAI
用Diffusion挑戰GPT
明敏 發自 凹非寺
量子位 | 公眾號 QbitAI
ICML 2024最佳論文出爐,結果發現其中一篇曾被ICLR 2024拒稿?

這篇論文來自斯坦福,Pika創始人之一孟晨琳(Chenlin Meng)也參與了。
它提出了一種新的離散擴散語言建模方法,通過引入分數熵損失函數,提高了離散擴散模型在語言建模任務中的性能。
實驗結果和GPT-2比較,在多數任務中都完勝。
生成效果be like:

5位審稿人給出的分數分別是:88665。
但還是被AC一錘定音,最終reject……
這不禁讓人想起Mamba。作為Transformer架構挑戰者,它開創了大模型的一個新流派。結果卻被ICLR拒稿。
當時這引發不小爭議,包括ICLR創始人之一LeCun都下場表示不滿:
很遺憾,歷屆程序委員會主席慢慢把它變成了一個與傳統評審流程差不多的會議。
只有一些小勝利:OpenReview平臺現在被大多數ML/AI會議使用,以及論文提交后立刻就能被所有人閱讀(盡管匿名)。

還有人說:
如果搜索ICML 2024接收的論文,就會發現很多都被ICLR 2024拒了。

這回又是咋回事?
又栽在實驗不完善上?
這篇論文關注了擴散模型在文本等離散數據領域表現一直不佳的問題。
團隊認為,標準擴散模型依賴于分數匹配(score matching)理論,但是這一機制推廣到離散數據領域后效果不佳。
為了填補這一空白,他們提出了一種新的損失函數分數熵(score entropy),并構建了分數熵擴散模型(SEDD)。
在主要語言建模任務上,SEDD在目前所有語言擴散模型中表現最佳,和同規模自回歸語言模型不相上下,在零樣本困惑度任務上擊敗GPT-2。
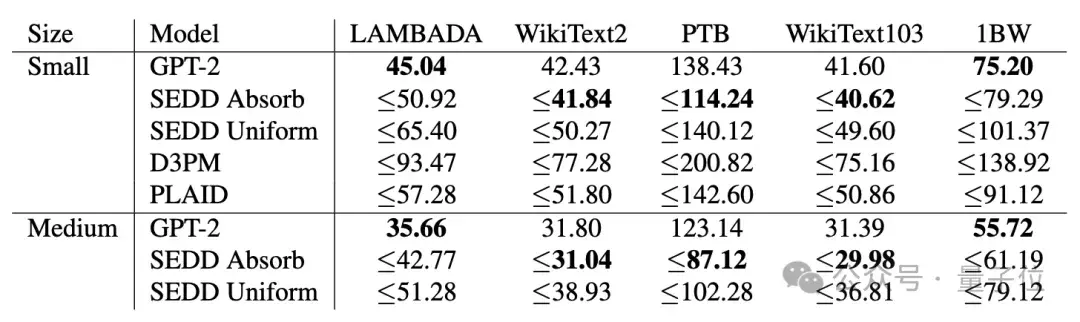
同時SEDD可生成高質量無條件樣本,可以方便在計算量和生成質量之間做權衡。通過直接參數化概率比,SEDD高度可控,可以使用提示詞微調而無需專門訓練。
5位審稿人中,有2位都給出8分高分。
大家普遍肯定了提出的論點。一位評審覺得論文推導過程寫得也很不錯,實驗結果非常令人信服。

不過也有很多小問題被提出,比如拼寫錯誤、忽略了對一些實驗細節的解釋。

從記錄中可以看到,作者針對評審提出的問題進行了詳盡的說明和修改(有的分2條才發完)。

有評審看到調整后的內容,也相應調整了分數。

不過最終AC還是拒收了這篇論文。
反駁的點就主要在于實驗部分不完整。
所有審稿人都認為,該論文只將GPT-2作為主要基線,缺少和其他擴散模型基線。一些審稿人認為,論文提交時實驗部分不完整。
盡管作者后續增加了一些實驗,但是AC仍然認為不夠完善,而且論文中提到此前擴散模型表現不及自回歸模型的說法可能不夠準確。
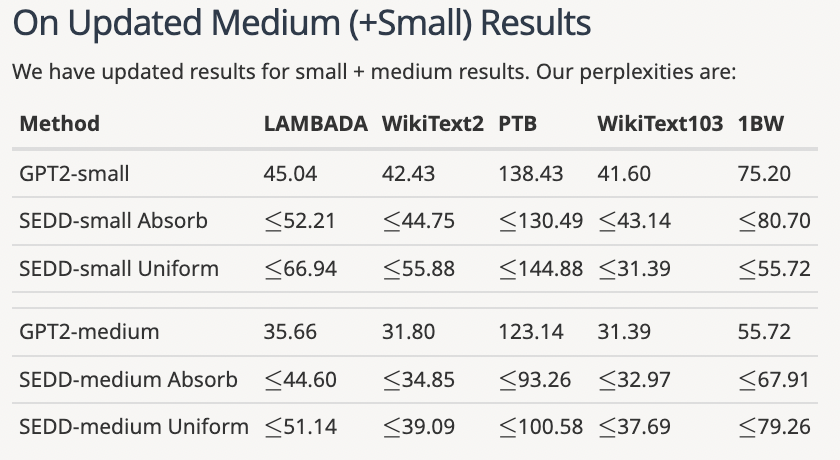
△作者后續補充內容
比如SSD-LM、TESS等模型的表現都比GPT-2表現更好,但是論文中卻沒有和這些結果做對比。
總之,AC認為論文提出了很好的idea,但是在實驗和對比上不夠完善。

有人表示,之前Mamba被拒也是類似的原因,后面完善了論文再拿best paper也很合理。

One More Thing
值得一提的是,這篇研究的作者中不光有Pika創始人之一孟晨琳。
一作最近也加入OpenAI,更近距離感受AGI了。他將在最近的ICML 2024上進一步講解這項工作。

論文地址:
https://arxiv.org/abs/2310.16834
- DeepSeek-V3.2-Exp第一時間上線華為云2025-09-29
- 你的AI助手更萬能了!天禧合作字節扣子,解鎖無限新功能2025-09-26
- 你的最快安卓芯片發布了!全面為Agent鋪路2025-09-26
- 任少卿在中科大招生了!碩博都可,推免學生下周一緊急面試2025-09-20