零一萬物API開放平臺出場!通用Chat多模態通通開放,還有200K超長上下文版本
千萬token免費送!
克雷西 衡宇 發自 凹非寺
量子位 | 公眾號 QbitAI
3月,國內外模型公司動作頻頻。國產大模型獨角獸“五小虎”之一零一萬物也有諸多新動作。
這不,前腳剛發布高性能向量數據庫,零一萬物又立馬正式發布了自己的API開放平臺,
共為開發者提供三個版本的模型:
- Yi-34B-Chat-0205:支持通用聊天、問答、對話、寫作、翻譯等功能。
- Yi-34B-Chat-200K:200K上下文,多文檔閱讀理解、超長知識庫構建小能手。
- Yi-VL-Plus:多模態模型,支持文本、視覺多模態輸入,中文圖表體驗超過GPT-4V。

去年11月,零一萬物就正式開源發布了首款預訓練大模型Yi-34B,當時的模型已經能處理200K上下文窗口,約等同于20萬字文本。這次開放API平臺,在Yi-34B的基礎上,有什么新亮點?
要說有什么獨特之處,我愿以五個“更”來概括。
分別是覆蓋更大的參數量、更強的多模態、更專業的代碼/數學推理模型、更快的推理速度、更低的推理成本。
并且!
Yi大模型API開放平臺兼容OpenAI的API,可以隨心快速絲滑切換。
更多詳情,一起來看——
200K上下文窗口+多模態能力
此次API開放,最亮眼的地方一共有兩點。
首先是200K的超長上下文窗口,可以一口氣處理約30萬個中英文字符,相對于讀完整本《哈利·波特與魔法石》小說。
在大海撈針測試中,Yi-34B-Chat-200K取得了幾乎全綠的成績,準確率高達99.8%。

實際測試中,篇幅近兩百頁、總字數19萬的《三體》第一部,Yi很快就能讀完并給出總結。

而且細節關注到位,能從故事中提取出主要角色信息和他們的事跡,然后直接用表格的形式呈現在我們面前。
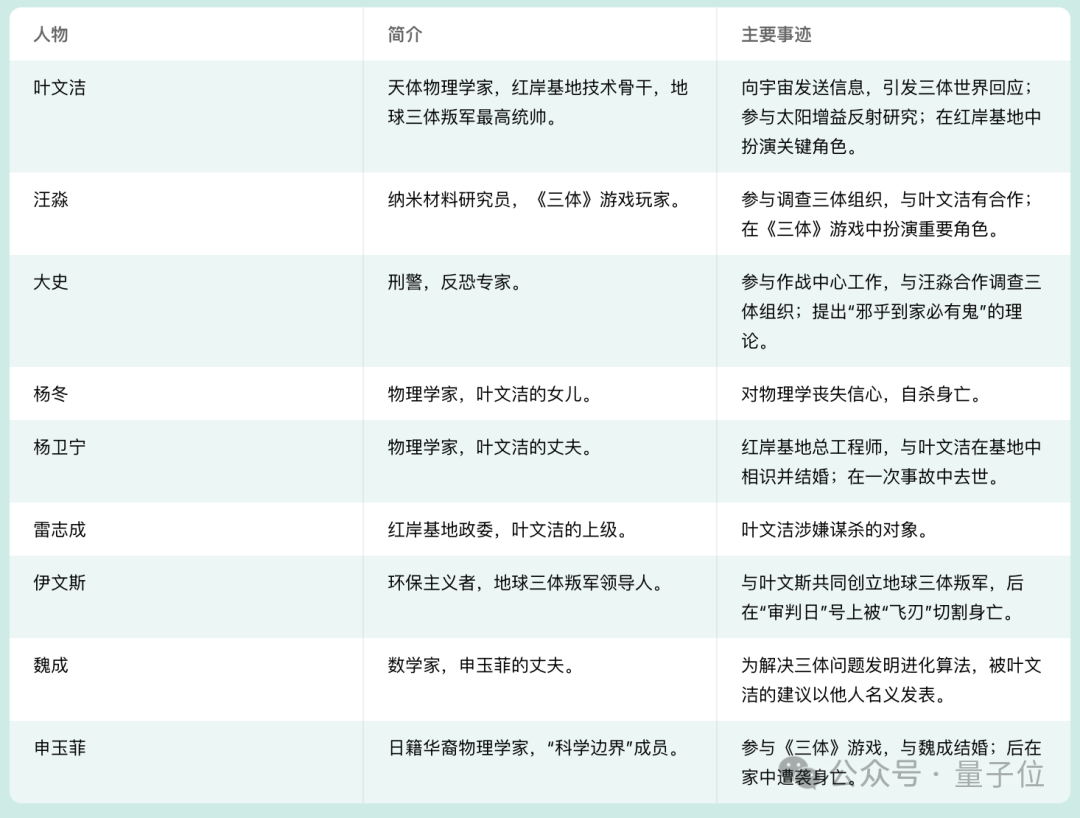
我們又補充追問了十個細節問題,答案分散在整部小說的各個位置,結果Yi全部答對。

另一大亮點,是Yi-VL-Plus強大的多模態能力。
多模態版本中,在保持LLM通用知識、推理等能力的前提下,圖片內中文、符號識別能力大幅增強,體驗超過了GPT-4V。
而且圖片輸入分辨率也提高到了1024×1024分辨率,并專門針對圖表、截屏等生產力場景進行了優化。
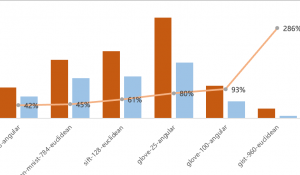
比如下面這張圖來自一篇文獻綜述,列舉了課題相關論文中被引量最高的10篇。

Yi-VL-Plus準確地找到了目標文獻,并準確識別出了文章標題,遇到“嗪”這種不常見的專業文字也沒掉鏈子。
再看看GPT-4V這邊,則是主打一個已讀亂回,給出的文章標題不知道來自何處。

而除了識讀圖表和文字,Yi-VL-Plus還支持學習專業知識并立即用于圖像的解讀。
比如早期體驗過的開發者教給模型一些心理學知識后,Yi-VL-Plus就能根據孩子的鉛筆畫展開一些基本的分析。
并且,模型給出的分析獲得了專業人士的認可,給出了“較準確”的評價。

△開發者星云愛店CTO大董提供的測試資料,文圖數據均脫敏
總之,憑借強大的長文本和多模態處理能力,無論是在to B還是to C場景,Yi都能構建出高效的大模型應用。
舉個例子??,在to C場景中,可以用基礎或多模態版本構建智能對話助手,進行深層次的對話問答。
而在B端,可以把Yi整合到現有產品,搭建出Copilot類的應用,抑或是利用超長文本能力建立知識庫,打造出客服等特定場景的智能助手。
在前期的開發者邀測中,擁有阿里、美團等多家大廠工作經歷的知乎大佬@蘇洋就利用Yi的API搭建出了一個翻譯器應用。

據作者本人介紹,他是看到GitHub上的一份開源的機器學習書籍之后萌生了翻譯的想法,然后開始搭建這個應用的。
而之所以選擇Yi作為承擔這一工作的大模型,就是看中了它超出的上下文窗口,能夠將作者每一章的全文都扔到模型里,而不用切分章節或做一些遞歸式的章節摘要等麻煩事。
另一方面,Yi和OpenAI的兼容性,也讓作者直接利用LLM平臺的OpenAI兼容API模塊,就快速完成了模型的接入。
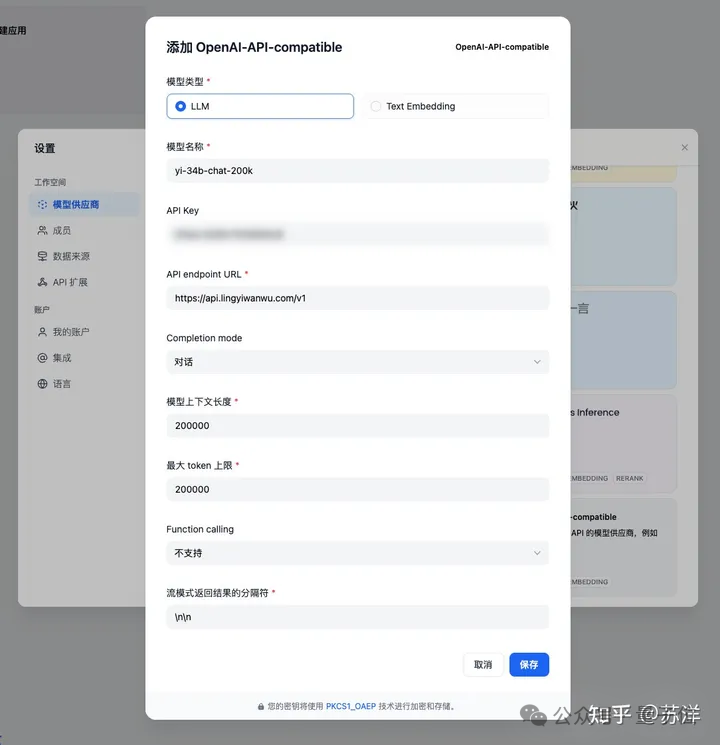
接入完模型之后就是幾乎可以一鍵完成的模型搭建了,這里需要做的只是點選應用的類型,然后起個名字,并適當調節一些參數。

在此基礎之上,作者又用golang對模型調用程序進行了編譯,進一步提升了整個流程的自動化程度。
最終,一個全自動的翻譯工具就大功告成了。

如果不看最后的進階部分,利用Yi的API快速構建一款AI應用,簡直不要太簡單!
而除了這些應用上肉眼可見的優勢,Yi系列API在技術層面的亮點同樣可圈可點。
絲滑切換OpenAI API
在Yi優異表現的背后,無論是API還是模型本身,都必然有強大的技術作為支撐——在技術上,Yi有哪些特色?
首先,Yi與OpenAI API完全兼容。
這意味著開發者只需修改少量代碼,就能完成從OpenAI到Yi的平滑遷移,實現了替換成本的最小化。
同時,為了提升API性能,零一萬物在API側進行了專門的推理優化。不僅推理速度更快,用戶體驗的流暢性和響應速度也都相應提高。
而針對模型自身的其他亮點,我們充分利用了Yi的長文本分析能力,從它的技術報告中進行了提煉。

當然,除了專門針對API做的優化之外,基礎模型的能力同樣不可或缺。
為了實現模型能力的提升,研究團隊從保證訓練數據質量、在tokenization中運用獨特設計、微調階段積累經驗等多個角度進行了攻關,增強了模型的優勢并在API段充分發揮。
比如從訓練階段開始,研究團隊就對數據進行了精心挑選,引入了啟發式規則去除低質量文本,并利用機器學習方式識別有害內容。
同時研發人員還對訓練數據中的文本進行聚類分析,并實施嚴格的去重機制,最大程度保證訓練數據的質量。

而tokenization階段,同樣體現著研發人員的獨到設計。
Yi使用字節對編碼進行分詞和詞匯表的構建,減少了詞匯表的大小并提高了編碼效率。
同時最大程度保留原始符號,避免變換過程中造成的信息丟失。
針對數字,Yi還采用了拆分成單個token的方式來提高模型理解力;甚至對于特殊和無法識別的字符,也有專門的應對策略。

到了微調環節,Yi從技術報告總結出的關鍵經驗就更多了。
比如“數據質量高于數量”的重要思想,從訓練階段開始就貫穿始終。
此外還有迭代過程、標簽系統、結構化格式等諸多策略,這里就不再一一贅述了。

食用指南
看到這里,旁友們應該對Yi API的能力已經有一定了解了。
那么,Yi大模型API到底該如何食用?

此前,Yi大模型API已經在小范圍開放內測。
“為了邀請更多的開發者并肩作戰”,今天起,Yi大模型API名額開啟了限量開放。
而且新用戶還贈送60元(千萬token)。
誰看了不說一句真香呢??!指路這篇文章的結尾,可獲得申請直通車連接~

開放API平臺后,零一萬物下一步會又什么新動作?
零一萬物技術副總裁及模型訓練AI Alignment、開放平臺負責人俞濤對此做出了答復,稱近期將會為開發者提供更多更強模型和AI開發框架。
未來計劃具體圍繞以下三個方面展開:
第一,支持更快的推理速度,顯著降低推理成本。
第二,突破更長的上下文,目標由目前的20萬tokens拓展到100萬tokens。
第三,基于模型具備的超長上下文能力,構建向量數據庫、RAG、Agent架構在內的全新開發者AI框架。
看來,零一萬物的下一步棋,就是推理更快、窗口更長,同時提供更加豐富和靈活的開發工具,以適應不同開發者需求下的多樣化應用場景。
具體推出的節奏,零一萬物此次沒有透露。但是——
三款模型的API,大家可以用起來了!
直通車:platform.lingyiwanwu.com/
- 論文自動變漫畫PPT!Nano Banana同款用秘塔免費生成,還有一對一語音講解2025-12-09
- 高通萬衛星:混合AI與分布式協同是未來 | MEET20262025-12-11
- 智能體A2A落地華為新旗艦,鴻蒙開發者新機遇來了2025-12-06
- 14歲華人小孩,折個紙成美國天才少年2025-12-06
相關閱讀