
大模型的進化方向:Words to Worlds | 對話商湯林達華
原生多模態架構起作用了
金磊 發自 凹非寺
量子位 | 公眾號 QbitAI
李飛飛團隊最新的空間智能模型Cambrian-S,首次被一個國產開源AI超越了。
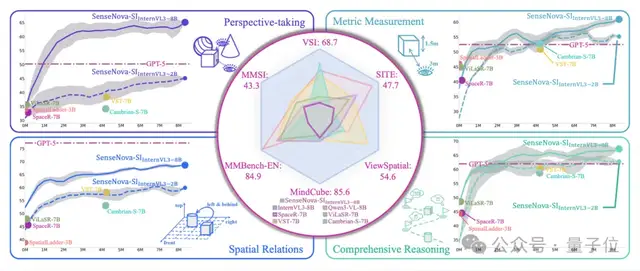
從這張展示空間感知能力的雷達圖中,一個名為SenseNova-SI的模型,它在多個維度上的能力評分均已將Cambrian-S給包圍。
而且從具體的數據來看,不論是開源或閉源,不論是2B或8B大小,SenseNova-SI在各大空間智能基準測試中都拿下了SOTA的成績:
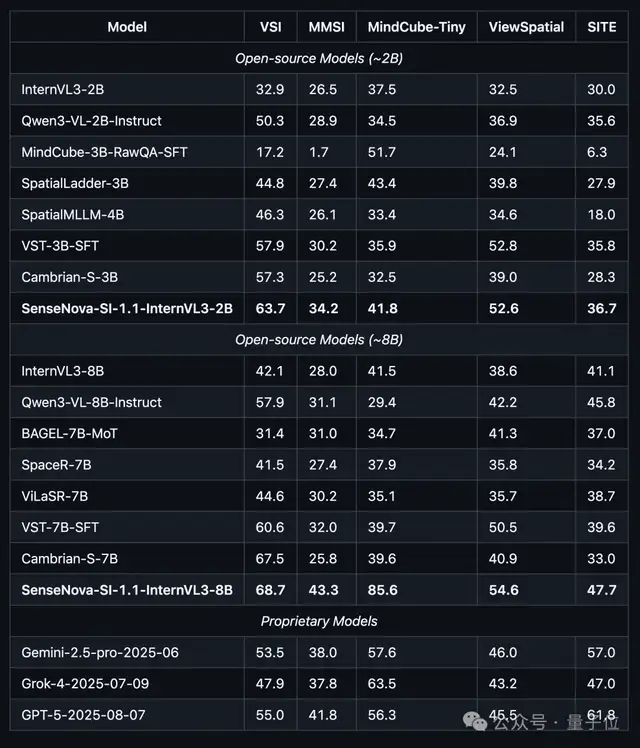
而這個SenseNova-SI背后的操刀者,正是商湯科技。
在量子位與商湯科技聯合創始人、首席科學家林達華深入交流過程中,他并沒有掩飾對這一進展的肯定:
在空間智能這個賽道上,基于長期的視覺積累,我們已經走到了世界前列。
但與此同時,林達華也是隨即話鋒一轉,表示他并不愿意把這個故事簡單地講成“贏了李飛飛”或者“贏了OpenAI”。
更深層的,林達華更像是在釋放一種信號,一個關于AI技術范式正在發生劇烈震蕩的信號——
單純依賴參數規模的AI范式逐漸面臨瓶頸。我們站在了新的十字路口。
因為在Scaling Law的邊際效應開始遞減、很多人還在內卷大語言模型時,林達華和他的團隊選擇的卻是一條很少有人走的路:Back to research(回歸實驗室)。
具體而言,是從最底層開始死磕原生多模態和空間智能,以此來完成一場從Words(語言)到Worlds(世界)的遷徙。
而在林達華看來,在這場遷徙中,中國科技公司已經搶到了一張船票。
我們該回歸實驗室了
回望過去三年,從2022年11月ChatGPT橫空出世,到GPT-4的震撼登場,AI行業經歷了一場狂飆式的野蠻生長。
那是一個把Scaling Law奉為圭臬的時代,只要算力足夠大、GPU足夠多、數據堆得足夠高,模型的能力似乎就能無限增長。
但到了2024年下半年,風向變了。
人們發現,雖然榜單上的分數還在漲,從GPT-4到GPT-5.2,再到Gemini的各種升級版,分數的躍遷越來越快,但帶給人們的驚艷感卻在邊際遞減。
林達華一針見血地指出:
原來的舊路徑,也就是單純依靠Scale的主流范式,雖然把模型推到了一個很高的高度,但也逐漸觸碰到了天花板。
分數提升越來越快,但模型對物理世界的解釋力、對復雜邏輯的泛化能力,并沒有實現質的飛躍。
與此同時,OpenAI前首席科學家Ilya Sutskever的一聲疾呼“Back to Research”,在硅谷和全球AI圈里引發了不小的震動。

這與林達華的思考不謀而合:
我們之前的路是大力出奇跡,現在的路,必須是回歸科研的本質。
為何會如此?簡單來說,因為純語言模型的紅利快吃完了。
目前的頂尖大模型,在數學、編程上已經接近奧賽金牌水平,但在理解物理世界、處理三維空間關系上,可能連一個幾歲的小朋友都不如。
未來的AGI,絕不會只是一個陪你聊天的Chatbot,也不應僅僅活在文本的邏輯里。它必須是一個能夠理解物理世界、具有多感官能力的世界模型。
林達華強調說:
人類的智能不只有語言。
人類與世界的交互是多模態的——我們用眼睛看,用耳朵聽,用手去觸摸。AI的未來,在于從讀萬卷書(語言模型)進化到行萬里路(空間與世界交互)。
在這個新舊交替的時間節點,商湯選擇不再盲目跟隨大語言模型的參數競賽,而是掉轉船頭,向著原生多模態這快更難啃的方向進發。
現在的模型連手指都數不清
現在的多模態大模型,大多都是有局限性的。
對于這個觀點,林達華給出了一個非常直觀且略帶幽默的案例。
哪怕是強如Grok或者GPT-4的早期版本,當你丟給它一張人手的照片,問它有幾根手指時,它經常會自信地回答“5根”。
哪怕圖片里的人手因為角度或畸變顯示出6根或4根,AI的答案依舊是如此。

再比如,給模型看一張簡單的三維積木圖,問它“從上往下看是什么樣子”,大多數模型都會選錯。
它們明明看到了圖片,為什么還會胡說八道呢?
因為它并沒有真正在看。
林達華打了一個極其生動的比方:
這就好比一個盲人,在黑暗中閉眼學習了十年。他讀了萬卷書,大腦極其發達,邏輯思維嚴密。突然有一天,你讓他睜開眼看世界。
他的第一反應是什么?是他會拼命地試圖用他過去十年在書本里學到的語義概念,去硬套眼前看到的東西。
在傳統的多模態架構(拼接式架構)中,通常是一個視覺編碼器(Vision Encoder)加上一個大語言模型。
視覺編碼器把圖片翻譯成語言模型能聽懂的Token,然后扔給大語言模型去推理。
在這個過程中,大語言模型依然是那個“閉眼學習了十年”的大腦。它看到“手”這個圖像Token,大腦里立刻調出的先驗知識是“手有5根手指”,會直接覆蓋掉眼睛看到的真實像素細節。
林達華分析道:
它不是真的理解了三維空間關系,它只是在靠概率猜詞。

這種拼接式的路線,雖然能快速出成果,但缺陷是致命的:
視覺信號在進入大腦的那一刻,就被降維、被閹割了。大量的空間細節、三維結構、物理規律,在轉化為語言Token的過程中流失殆盡。
這就是為什么現在的模型數學能拿金牌,卻連手指都數不清、連積木都搭不明白的原因了。
要解決這個問題,修修補補似乎已經是無濟于事。必須從底層架構上進行一場徹底的革新。
商湯原生多模態的解法
這場革新的產物,就是商湯剛剛開源的NEO架構,以及基于此架構的SenseNova-SI模型。

在深入了解這個架構之前,我們需要先理解什么是原生多模態。
林達華的解釋是這樣的:
模式上不再是“視覺眼睛+語言大腦”的拼接。在NEO架構里,從模型最底層的Transformer Block開始,每一個細胞都能同時處理視覺和語言信號。
這聽起來很抽象,但在技術實現上卻極其硬核。
在NEO架構中,視覺Token和文本Token不再是“先后進入”或“翻譯關系”,而是“一塊進入模型的每一層。
商湯設計了專門的混合注意力機制(Mixed Attention),讓模型在進行每一次推理計算時,既能參考文本的上下文,又能實時“回頭看”圖像的原始特征。

為了讓模型真正理解空間,林達華團隊還干了一件反直覺的事——
他們不再只用預測下一個詞(Next Token Prediction)來訓練模型,而是引入了跨視角預測。
簡單來說,就是給模型看一個物體的正面,讓它去預測這個物體側面、背面長什么樣。
林達華表示:
這就像教小孩子搭積木、看世界一樣,你在腦海里構建三維模型的過程,就是空間智能誕生的過程。
這種原生架構帶來的效果是驚人的——
數據效率提升了10倍。
例如SenseNova-SI僅用了同類模型10%的訓練數據,就達到了SOTA水平。而且,它不再是靠死記硬背,而是真正理解了三維空間關系。
正如我們前文提到的對比評測中,SenseNova-SI不僅超越了李飛飛團隊的Cambrian-S,更是在空間推理、幻覺抑制等關鍵指標上表現更優。
林達華總結道:
我們希望把一個閉眼狂奔的盲人,變成了一個真正睜眼看世界的觀察者。
落地,落地,還得看落地
技術再牛,如果不能變成生產力,終究只是實驗室里的玩具。
在量子位與林達華的交流過程中,他反復提到了一個詞:工業紅線。
我們內部有一個標準:任何技術,如果它的使用成本高于它創造的價值,那就是沒過工業紅線。
這是因為大模型行業目前最大的痛點,除了不夠聰明,就是太貴、太慢。
特別是在視頻生成領域,雖然Sora驚艷了世界,但生成幾秒鐘視頻需要消耗巨大的算力,推理時間動輒幾分鐘甚至幾小時。
這種成本和延遲,根本無法支撐大規模的商業應用。
“只有當推理成本以每年1-2個數量級的速度下降時,AI才能從Demo級的炫技,變成石油級的工業生產力。”
為了跨過這條紅線,商湯在落地應用上下足了功夫。林達華以商湯最新實時語音驅動數字人產品SekoTalk為例,展示了什么叫算法和系統協同的極致優化。
目前的視頻生成主流模型都是基于擴散模型,生成一張圖往往需要迭代幾十步甚至上百步。
但這個過程的步驟就不能減少嗎?答案是否定的。
林達華團隊利用一種名為算法蒸餾的技術,硬生生將擴散模型的推理步數,從100步壓縮到了4步。
這不是簡單的偷工減料,而是基于對模型分布的深刻理解。林達華解釋說:
模型在從白噪聲變成圖像的過程中,不同階段處理的數據分布是完全不同的。以前是用同一套參數跑100遍,現在是分階段用不同參數跑4遍,讓專業的參數干專業的事。
如此打法之下,效果依舊是驚人:64倍的速度提升。
這就意味著在不久的將來,你只需要一張消費級的顯卡(比如RTX 4090甚至更低),就能實時生成高質量的數字人視頻。

△SekoTalk生成的視頻
聊至此處,林達華也表現出了激動之情:
以前生成20秒視頻要跑一小時,現在我們能做到實時生成。這不僅是效率的提升,更是商業模式的質變。
這直接打通了AI在直播、短視頻制作等領域的規模化落地路徑。
從SenseNova-SI的底層架構創新,到SekoTalk的極致落地優化,商湯正在踐行林達華所說的雙輪驅動:
一手抓Back to Research的原始創新,一手抓擊穿工業紅線的落地價值。
One More Thing
在對話的最后,林達華也為當下想要投身AI大浪潮中的年輕人給予了一些寶貴的建議:
不要只盯著大語言模型來卷,這個賽道真的太擁擠了。
林達華誠懇地表示,年輕一代的研究者和創業者,應該把視野打開。
具身智能、AI for Science、工業制造、生命科學……這些都是非常好的領域。
智能不只有語言,AI的未來在于從讀萬卷書進化到行萬里路。
林達華最后說道,在這場從Words to Worlds的宏大遷徙中,中國擁有全世界最豐富的場景、最完整的工業體系。這片土壤,天生適合培育那些能與物理世界深度交互的AI。
在這個賽道上,中國科技公司已經搶到了一張船票;而未來的頭等艙,屬于那些敢于回歸實驗室、敢于勇闖無人區的年輕人。
SenseNova-SI地址:
https://github.com/OpenSenseNova/SenseNova-SI
NEO地址:
https://github.com/EvolvingLMMs-Lab/NEO
- QQ音樂你變了,竟能免費在AI PC上原創一首《大東北》2025-12-16
- 行啊AI PC!現在都能隔空測血壓、檢測皮膚了2025-12-18
- 不兒,這誰還能看出是AI演的視頻啊2025-12-18
- 華為新架構砍了Transformer大動脈!任意模型推理能力原地飆升2025-12-06
相關閱讀

大模型掌握人類空間思考能力!三階段訓練框架學會“邊畫邊想”,5個基準平均提升18.4%
視覺推理正經歷從“視覺轉文本”到“Thinking with Images”的范式轉變








