
用兩個簡單模塊實現分割理解雙重SOTA!華科大白翔團隊等推出多模態新框架
已被ICCV 2025錄用
LIRA團隊 投稿量子位 | 公眾號 QbitAI
多模態大模型需要干的活,已經從最初的文生圖,擴展到了像素級任務(圖像分割)。
不過,無論是OMG-LLaVA,還是提出了embedding-as-mask范式的LISA(CVPR 2024),都還存在分割結果不夠精確,以及理解過程中出現幻覺兩大痛點。
這主要源于現有模型在物體屬性理解上的不足,以及細粒度感知能力的局限。
為緩解上述問題,華中科技大學團隊和金山辦公團隊聯合提出了兩個核心模塊:
語義增強特征提取器(SEFE)和交錯局部視覺耦合(ILVC)。
前者融合語義特征與像素級特征,提升物體屬性推理能力,從而獲得更精確的分割結果。
后者基于分割掩碼提取局部特征后,自回歸生成局部描述,為模型提供細粒度監督,從而有效減少理解幻覺。
最終,研究團隊構建了在分割和理解兩項任務上均取得SOTA的多模態大模型LIRA。

與InternVL2相比,LIRA在保持理解性能的同時,額外支持圖像分割任務;與OMG-LLaVA相比,LIRA在圖像分割任務上平均提升8.5%,在MMBench上提升33.2%。
目前,LIRA項目已被ICCV 2025錄用。
現有方法仍常常無法準確分割目標
通過將分割模塊和多模態大模型結合,多模態大模型的能力已從視覺理解拓展至像素級分割。
LISA(CVPR 2024)首次提出“embedding-as-mask”范式,通過引入 token解鎖了分割能力。
OMG-LLaVA 則采用通用分割模型作為視覺編碼器,并將圖像特征與感知先驗融合,從而在分割與理解任務上實現更優的協同表現。
盡管現有方法已取得顯著進展,但在復雜場景下仍常常無法準確分割目標。
下圖Figure 2中,OMG-LLaVA就未能正確分割出“最靠近白色汽車的紅色公交車”。
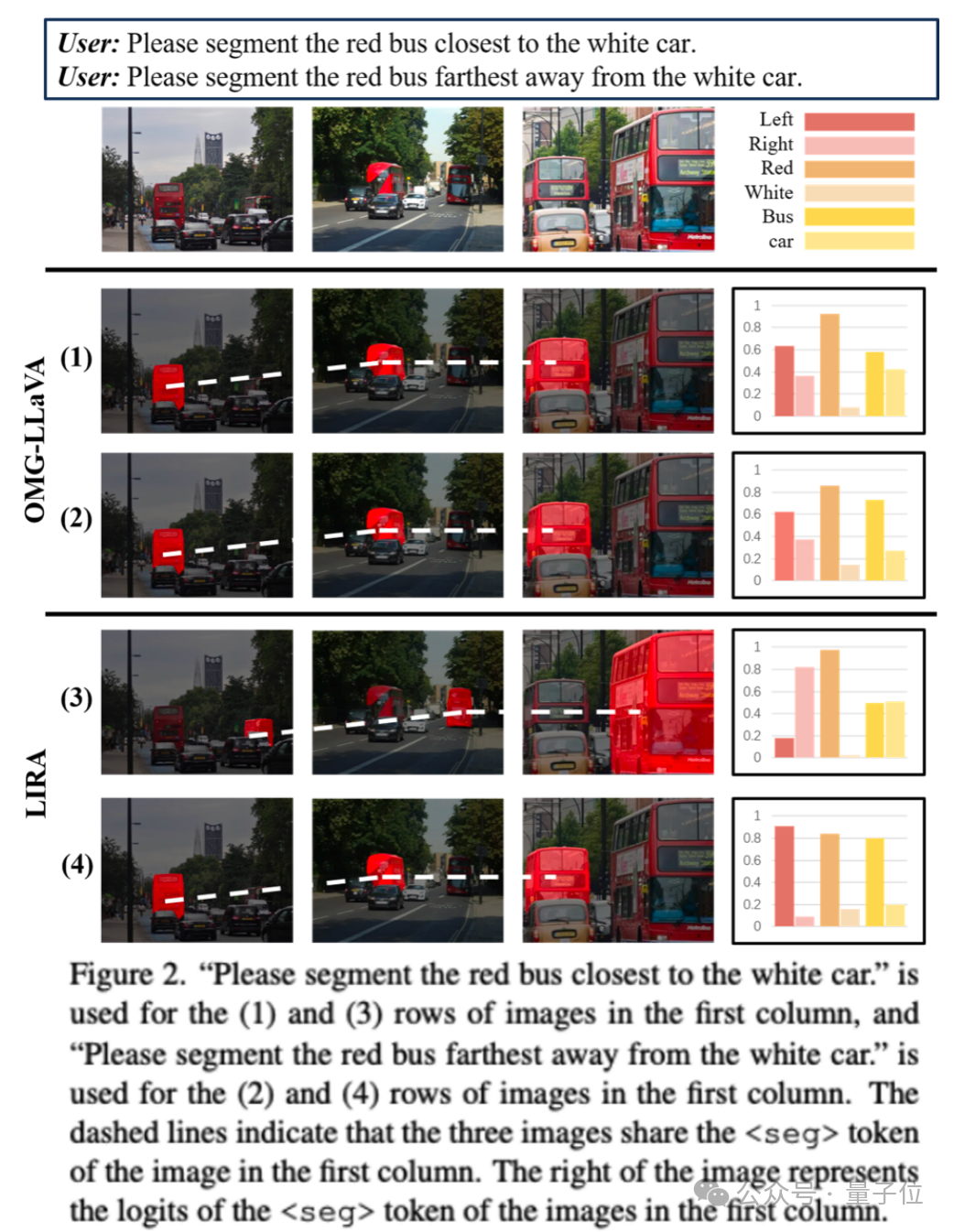
為探究分割錯誤的原因,研究團隊提取了多模態大模型在第一列圖像上生成的token embedding,并直接用于第二列和第三列圖像的分割。
有趣的是,在 (1) 行的所有圖像中,左側公交車始終被分割出來,這表明 token可能包含了與原圖像無關的語義信息。
進一步分析token的logits發現,與“left”相關的值顯著偏高,從而導致左側公交車被分割出來。
研究團隊推測,產生分割錯誤的原因是多模態大模型在token中未能有效編碼準確的位置信息,反映其視覺理解能力存在局限。
此外,現有方法通常依賴位置查詢來指示目標位置,但并不能在局部描述與對應圖像區域特征之間建立明確聯系,從而可能引發幻覺。
這引出了一個重要問題:
是否應直接將局部圖像特征輸入文本大模型,讓模型基于該區域生成描述,從而在視覺特征與語義之間建立更明確的映射?
同時支持理解和分割任務的多模態大模型LIRA
依循這個思路,研究團隊提出了同時支持理解和分割任務的多模態大模型LIRA。
如下面Figure 2所示,研究團隊進一步分析了token的logits。
結果表明,當“right”對應的logits更高時右邊的bus被分割出,“left”對應的logits更高時,左邊的bus被分割出,這可能表明 token實際上包含了被分割物體豐富的語義信息。
LIRA能夠準確地將諸如“離白色汽車最近的紅色巴士”等查詢解釋為指向“右邊的巴士”,從而實現精確分割。
這個過程涉及根據用戶query和圖像信息來理解物體屬性,以實現準確的分割,研究團隊稱之為“Inferring Segmentation”。
這一定義可能與LISA Reasoning Segmentation中所使用的定義有所不同,后者依賴于外部世界知識或常識來對隱式查詢(例如,“請分割圖中富含維生素C的食物”)進行推理。

此外,研究者還提出了語義增強特征提取器(SEFE)和交錯局部視覺耦合機制(ILVC),旨在提升多模態大模型分割精度和緩解理解幻覺。
SEFE通過融合高層語義信息與細粒度像素特征,增強模型的屬性理解能力從而提高分割性能。
ILVC通過顯式綁定局部圖像區域與對應文本描述,為多模態大模型提供更細粒度的監督,從而緩解幻覺現象。

語義增強特征提取器(SEFE)
該模塊融合了來自預訓練多模態大模型的語義編碼器和分割模型的像素編碼器。
給定全局圖像,語義編碼器和像素編碼器分別提取特征,經過多層感知機(MLP)轉換為相同維度的特征:
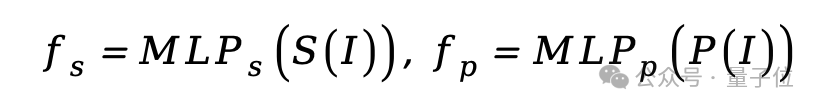
隨后,利用多頭交叉注意力融合語義特征和像素特征:
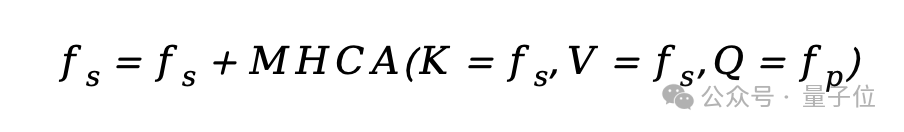
最終將融合后的特征拼接為全局特征后送入LLM中:

交錯局部視覺耦合模塊(ILVC)
在多模態大模型中,將局部特征與對應的局部描述對齊對于精確理解目標至關重要。
然而現有的方法(Figure 4(a))通常僅提取 token處的embedding,將其輸入解碼器生成分割掩碼。
這種方法并未明確地將局部圖像區域與其對應的文本描述直接關聯。
受到人類的感知通常是先關注感興趣的區域,再進行描述的啟發,本文提出了交錯局部視覺耦合模塊幫助將局部圖像區域與對應的文本描述進行耦合(Figure 4(b))。
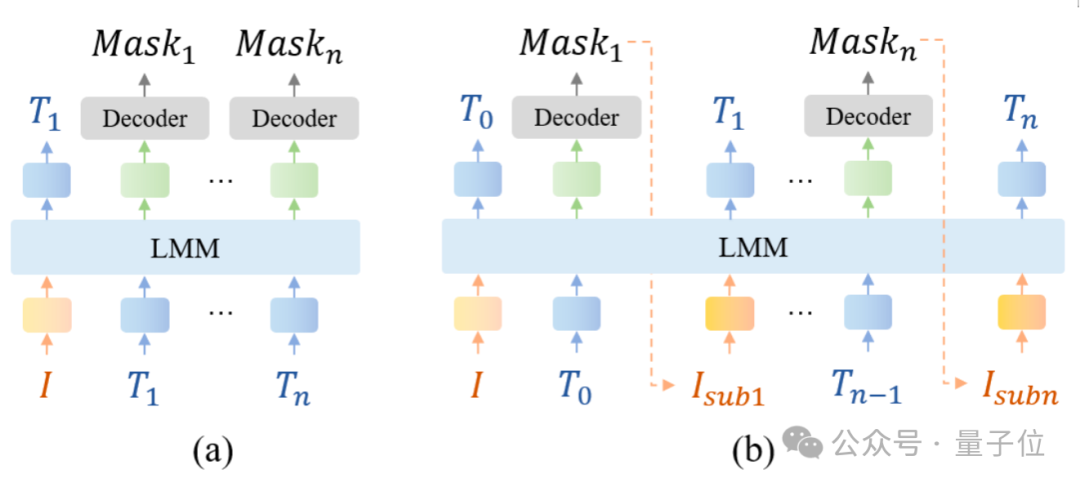
具體而言,LIRA使用token生成分割掩碼,基于該掩碼從原始圖像中裁剪出對應區域,并將裁剪區域調整為448 x 448大小后輸入SEFE提取局部特征。
隨后,將編碼后的局部特征重新輸入文本大模型,以生成該圖像區域的描述并預測后續內容。
通過這種交錯的訓練范式,ILVC模塊成功建立了局部圖像區域與文本描述的顯式聯系,為局部圖像特征引入了細粒度監督,從而緩解了幻覺。
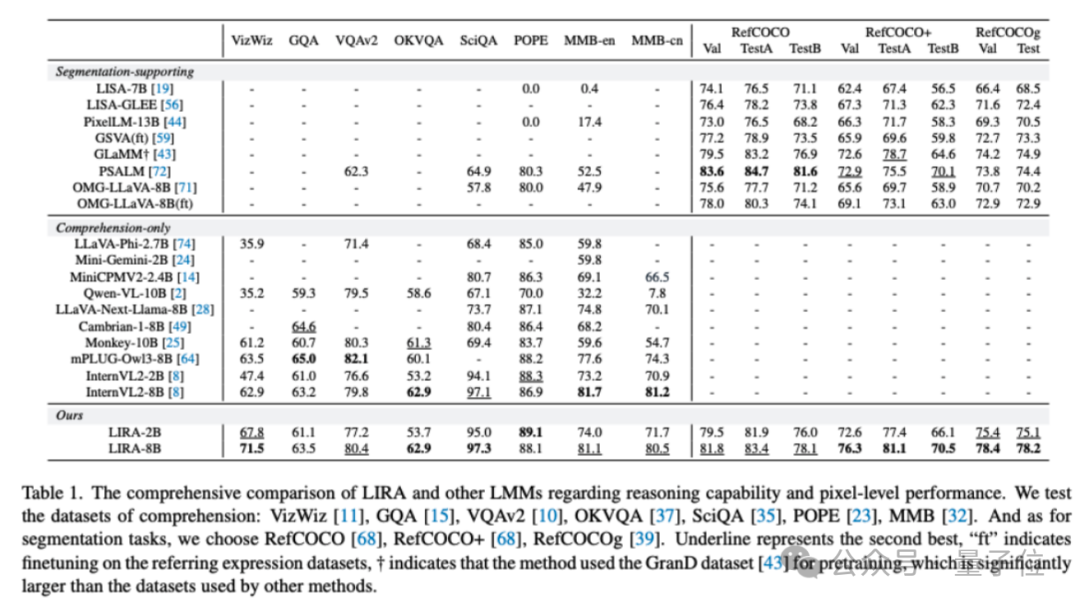
實驗結果:優于先前最佳方法
實驗結果表明,LIRA能夠同時支持理解和分割任務,并且在多個理解和分割數據集上取得了不錯的性能。
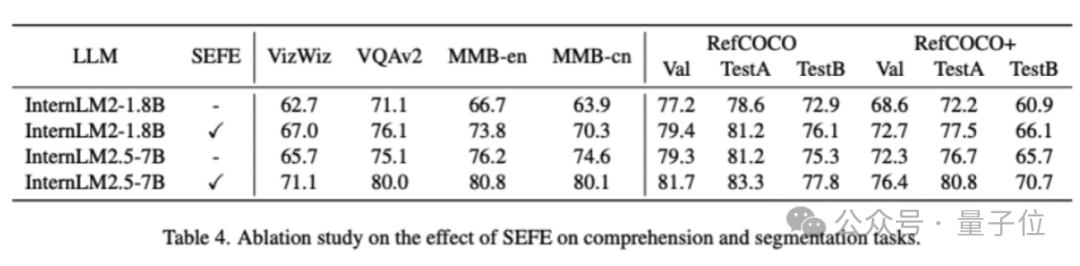
為驗證SEFE的有效性本文基于InternLM2-1.8B和InternLM2.5-7B骨干網絡進行了消融實驗。
結果顯示,采用InternLM2-1.8B時,整合SEFE在理解任務上平均提升5.7%,分割任務提升3.8%。
采用InternLM2.5-7B時,理解任務和分割任務的平均提升分別為5.1%和3.4%。
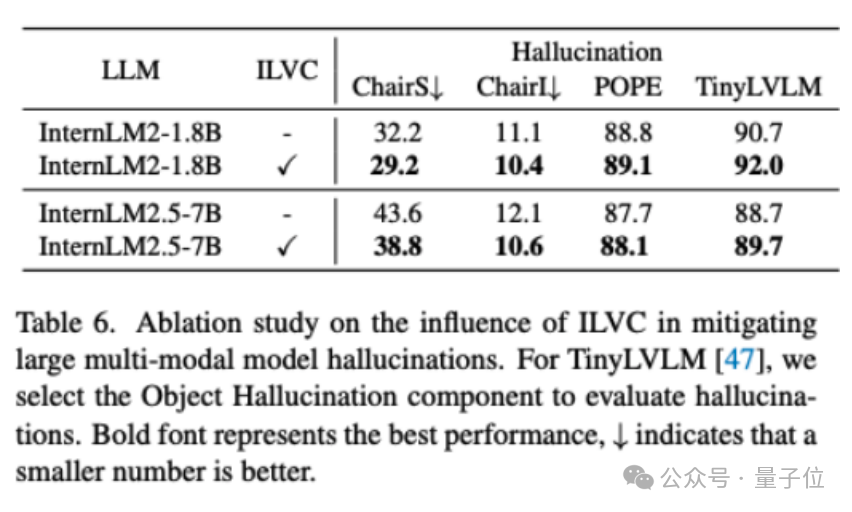
在SEFE的基礎上,本文進一步驗證整合ILVC的效果。
結果表明,采用ILVC后,在數據集ChairS上,1.8B和7B規模的模型幻覺率分別降低了3.0%和4.8%。
將LIRA同時用理解數據和分割數據進行聯合訓練,性能僅較單獨用理解數據訓練略微下降0.2%,優于先前最佳方法OMG-LLaVA在五個理解數據集上近15%的性能下降。
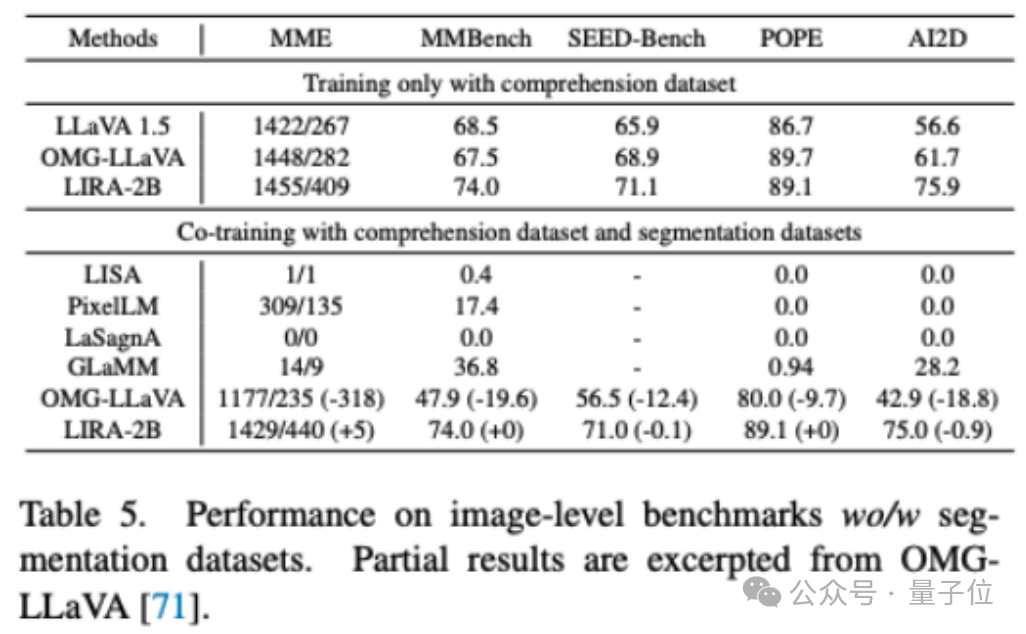
綜上,豐富的實驗結果驗證了LIRA在多個理解與分割基準上的優異表現。
此外,研究團隊還在論文中探討了token在分割任務中的作用,發現其logits能夠準確反映被分割物體的屬性,推測其可能蘊含更豐富的物體語義信息。
未來研究中,深入探索文本與視覺token之間的關聯,可能為提升多模態大模型的理解和分割能力帶來新的啟發。
總體而言,LIRA實現了理解與分割任務性能的協同提升,提出了在細粒度多模態大模型中緩解幻覺的新視角,并將分割多模態大模型中token的語義內涵納入研究視野,可能為后續相關探索提供了啟示。
arXiv:
https://arxiv.org/abs/2507.06272
GitHub:
https://github.com/echo840/LIRA
- 小冰之父李笛智能體創業,公司取名Nextie!陸奇是股東2025-12-09
- Meta公開抄阿里Qwen作業,還閉源了…2025-12-11
- 跨境電商的疑難雜癥,被1688這個AI全包了…2025-12-07
- 谷歌最強大模型付費上線,在DeepSeek開源后被吐槽太貴2025-12-05
相關閱讀




