
知識類型視角切入,全面評測圖像編輯模型推理能力:所有模型在「程序性推理」方面表現不佳
KRIS-Bench團隊 投稿
量子位 | 公眾號 QbitAI
人類在學習新知識時,總是遵循從“記憶事實”到“理解概念”再到“掌握技能”的認知路徑。
AI是否也建立了“先記住單詞,再理解原理,最后練習應用”的這種知識結構呢?
測評一下就知道了!
東南大學聯合馬克斯·普朗克信息研究所、上海交通大學、階躍星辰、加州大學伯克利分校與加州大學默塞德分校的研究團隊,共同提出了KRIS-Bench(Knowledge-based Reasoning in Image-editing Systems Benchmark)。
首創地從知識類型的視角,對圖像編輯模型的推理能力進行系統化、精細化的評測。

借鑒布魯姆認知分類與教育心理學中的分層教學理念,KRIS-Bench讓AI在事實性知識(Factual Knowledge)、概念性知識(Conceptual Knowledge)與程序性知識(Procedural Knowledge)三大層面上,逐步接受更深入、更復雜的編輯挑戰。
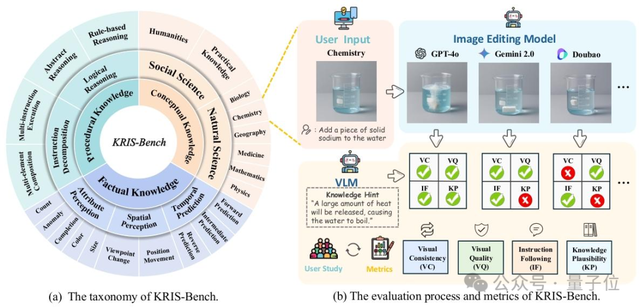
基于認知分層的三大知識范疇
- 事實性知識(Factual Knowledge):如顏色、數量、空間與時間這些可直接感知的信息;
- 概念性知識(Conceptual Knowledge):涉及物理、化學、生物等學科常識,需要對世界進一步的理解;
- 程序性知識(Procedural Knowledge):多步操作與規則推理,考察模型的任務分解與推理能力。
KRIS-Bench在每個類別下又細化出7大推理維度、22種典型編輯任務,從“物體計數變化”到“化學反應預測”、“多元素合成”等,覆蓋了從初級到高級的全譜系難度。
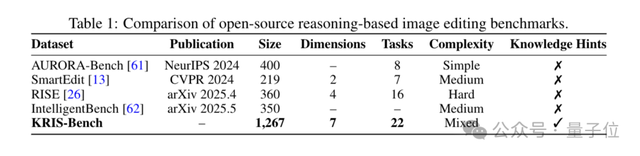
- 樣本總量:1,267對圖像–指令,全部由專家團隊手工打磨、反復校對;
- 數據來源:包含真實照片、開源基準、模型生成、3D渲染等多樣分布,防止模型投機取巧。

四維度自動化評估指標
借助多模態大模型與人工校準,KRIS-Bench首創從四個維度對編輯輸出打分:
- 視覺一致性(Visual Consistency):非目標區域是否保持原貌;
- 視覺質量(Visual Quality):生成圖像的自然度與無失真度;
- 指令跟隨(Instruction Following):指令要點執行的完整性與準確性;
- 知識合理性(Knowledge Plausibility):結果是否符合真實世界的常識與規律。
深度知識任務還附帶手工知識提示,以幫助評判模型是否真正“理解”了背后的原理。
10款模型全面測試
KRIS-Bench評估了3款閉源(GPT-Image-1、Gemini 2.0 Flash、Doubao)和7款開源(OmniGen、Emu2、BAGEL、Step1X-Edit、AnyEdit、MagicBrush、InstructPix2Pix)模型。

- 閉源旗艦GPT-Image-1遙遙領先,開源黑馬BAGEL-Think通過引入推理過程提高了在知識合理性上的性能表現,但離閉源模型仍有一定的距離。
- 即使對于最簡單的事實性知識,許多模型在例如數量變化,大小改變上的表現依舊差強人意。
- 所有模型在“程序性推理”、“自然科學”及“多步驟合成”任務上普遍失分,顯示出深層推理能力的嚴重不足。

借助KRIS-Bench,團隊正推動圖像編輯模型脫離單純的“像素搬運”,向具備人類般認知能力的“視覺智者”邁進。
未來,團隊期待編輯不再是“換換顏色”“挪挪位置”這么簡單,而是在內部植入物理、化學、社會常識與因果推理,真正讓 AI 明白“為什么會這樣”和“接下來會怎樣”。
感興趣的朋友可以戳下方鏈接獲取更多細節
項目地址:https://yongliang-wu.github.io/kris_bench_project_page/
論文地址:https://arxiv.org/abs/2505.16707
代碼地址:https://github.com/mercurystraw/Kris_Bench
— 完 —
- 又一高管棄庫克而去!蘋果UI設計負責人轉投Meta2025-12-04
- 萬卡集群要上天?中國硬核企業打造太空超算!2025-11-29
- 學生3年投稿6次被拒,于是吳恩達親手搓了個評審Agent2025-11-25
- 波士頓動力前CTO加盟DeepMind,Gemini要做機器人界的安卓2025-11-25




