
華為攻克AI推理「想太多」問題!新方法讓大模型推理提速60%,準確率還高了
S-GRPO團隊 投稿
量子位 | 公眾號 QbitAI
AI回答問題太慢太長且無用,有沒有能讓大模型提前停止思考的方法?
華為提出了首個在Qwen3上還有效的高效推理方法——S-GRPO,突破了思維鏈「冗余思考」瓶頸。
通過 “串行分組 + 衰減獎勵” 的設計,在保證推理準確性的前提下,讓模型學會提前終止思考,推理提速60%,生成更精確有用的答案。
S-GRPO適合作為當前Post Training(訓練后優化)范式中的最后一步,在確保模型預先存在的推理能力不受損害的情況下,使能模型在思維鏈的早期階段即可生成質量更高的推理路徑,并在思考充分后隱式地提前退出。

S-GRPO對單條完整推理路徑進行分段截斷
OpenAI o1, Deepseek-R1等推理模型依賴Test-Time Scaling law解決復雜的任務。
然而,過長的思維鏈序列的生成也顯著增加了計算負載和推理延遲,這提高了這些模型在實際應用中的部署門檻,且引入了很多冗余的思考。
S-GRPO的全稱為序列分組衰減獎勵策略優化(Serial-Group Decaying-Reward Policy Optimization),旨在提升大語言模型(LLM)的推理效率和準確性,解決冗余思考問題。
核心理念
傳統的推理優化方法,如GRPO(Group Reward Policy Optimization),采用并行生成多條完整推理路徑的方式(如下圖左側所示),并通過0/1獎勵機制對每條路徑的最終答案進行評價。
然而,這種方法未能充分利用推理過程中的中間信息,也未能有效提升推理效率。

S-GRPO的創新之處在于引入了“早退推理”的概念(如上圖右側所示)。
它通過對單條完整推理路徑進行分段截斷,生成多個“早退推理”分支(Serial Group),并通過一種指數衰減的獎勵機制對這些分支的答案進行評價。
具體來說:
- 早退推理路徑(Serial Group)
- 模型在推理過程中,可以在任意中間步驟停止推理并直接生成答案。這些不同位置的早退路徑被用于訓練模型,以評估在不同推理深度下的推理質量。
- 衰減獎勵策略(Decaying Reward Strategy)
- 對于每個早退路徑,如果答案正確,則根據其推理深度分配獎勵,越早退出推理的正確答案,獎勵越高(例如,獎勵值按照 的規則遞減);如果答案錯誤,則獎勵為0。這種機制不僅鼓勵模型盡早得出正確答案,還確保了推理的準確性。
方法
S-GRPO的訓練框架分為三個主要階段,如下圖所示:

- 完整推理展開(Full Thought Rollout)
模型首先生成一條完整的推理路徑(

),即從初始思考步驟(
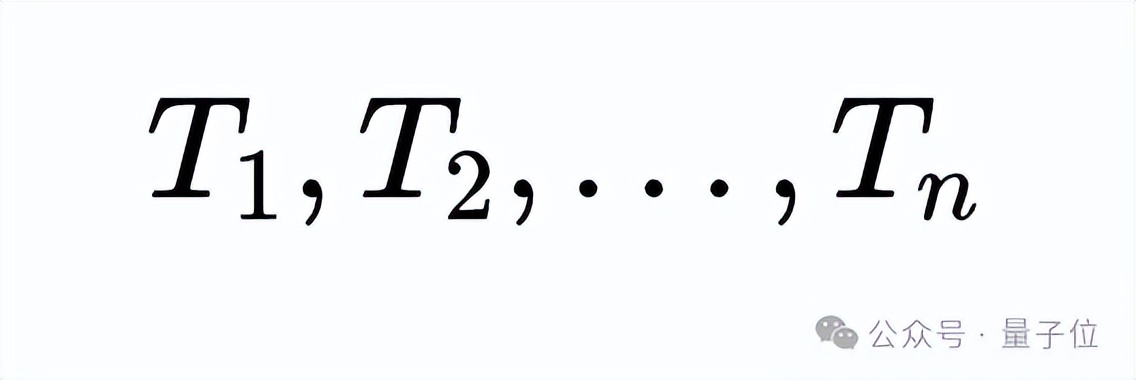
)到最終的推理結束標志(

) 和答案(

)。這一階段為后續的早退路徑生成提供了基礎。
- 早退推理展開(Early-exit Thought Rollout)
在完整推理路徑的基礎上,模型通過隨機截斷生成多個早退路徑(

)。
每條早退路徑在截斷點插入提示語“Time is limited, stop thinking and start answering. n</think>nn”,明確指示模型停止推理并生成答案(

)。
這些早退路徑形成了一個“序列分組”(Serial Group),用于訓練模型在不同推理深度下的表現。
- 獎勵計算與參數更新(Reward Computation and Parameter Update)
對于每條早退路徑,模型根據衰減獎勵策略計算獎勵值(

),并進一步計算優勢值(

)。
這些優勢值用于優化模型參數,最終使模型學會在合適的時機停止推理并生成高質量答案。
下圖直觀地展現了S-GRPO在訓練過程中如何采樣在不同位置提前退出的completions以及賦予獎勵。

對于第一個退出的位置,模型給出的中間答案錯誤,則將獎勵置為0。
對于后續給出正確答案的提前退出,則基于退出位置賦予衰減的正向獎勵值,越早退出收益越高,從而鼓勵模型探索簡潔且正確的思考。
實驗結果
為了驗證S-GRPO的表現,作者在5個挑戰性的推理benchmark上進行了測評,其中包含4個數學推理任務(GSM8K、MATH-500、AMC 2023、AIME 2024)、1個科學推理任務(GPQA Diamond)。
評估指標選用準確率和生成token數量兩維度評測。實驗選用了R1-Distill-Qwen系列模型(7B,14B)和Qwen3系列模型(8B, 14B)。

實驗結果表明S-GRPO顯著地超過了現有的baseline。
相較于vanilla的推理模型,S-GRPO平均提高了0.72到6.08個點準確率的同時降低了35.4%到61.1%的生成長度。
S-GRPO在訓練集域內(In Domain)的數學推理benchmark上(GSM8K、MATH-500、AMC 2023、AIME 2024)和訓練集域外(Out of Domain)的科學推理題目上(GPQA Diamond)都獲得了顯著的提升,充分證明了該方法的有效性和魯棒性。
相比于當前其它SOTA高效推理方法,S-GRPO最好的兼顧了正確性和效率。
相比于DEER,S-GRPO在困難問題與簡單問題上都能有效降低思考長度并維持精確度。
相比于原始GRPO,S-GRPO顯著降低了推理長度的同時有著相近的準確率。
而與其它的高效推理訓練方法相比,S-GRPO保持住了準確率,而它們均對回答的準確率性能有損害。
實驗還探究了S-GRPO在不同生成長度預算下的性能。
通過控制推理時的生成長度預算由短到長,比較S-GRPO與vaniila CoT在GSM8K和AIME 2024上準確率與實際生成長度的變化。
下圖中的實驗結果展現出在不同的預算下,S-GRPO都比vaniila CoT的準確率高且生成長度更短。

此外,實驗還表明,在長度預算少的情況下,S-GRPO相比vaniila CoT的準確率增益更顯著,實際生成長度相近;在長度預算高的情況下,S-GRPO相比vaniila CoT的實際生成長度更短,準確率略高。
S-GRPO相比vaniila CoT的兩個變化趨勢都更平緩。這表明S-GRPO只需要較低的長度預算就可以達到較高的準確率,反映出S-GRPO可以生成簡潔且正確的思考路徑。
為了驗證S-GRPO中每個設計的有效性,實驗設置了三個不同的消融實驗。
下表的實驗結果表明僅保留two-time rollouts中采樣的最短且正確的completion的設置雖然進一步縮短了推理長度,但是會損害模型的推理正確性。

消去對短輸出提供高回報的設計,即所有對正確的采樣結果都給予高回報,會導致模型推理依舊冗長,這是由于更長的推理更容易取得正確的結果,模型會收斂到探索長序列推理的方向。
移除掉Serial-Group Generation的設計后,S-GRPO退化成GRPO,模型在準確率和推理長度上取得了與w/o. Decaying(All 1)相近的表現,這說明作為S-GRPO中不可或缺的一環,Serial-Group Generation的設計本身不會損害模型在RL中的探索能力。

上圖中對比了S-GRPO與vanilla推理過程以及相同thinking budget下硬截斷迫使模型給出結論的輸出內容對比。
盡管同樣給出了正確的答案,S-GRPO僅使用了一半不到的思考budget,證明了S-GRPO有效解決了overthinking問題。
假如直接對原始推理內容在相同thinking budget處截斷,模型無法基于已有的思考內容得到正確的結論,這說明S-GRPO更精確地定位到了準確的解題思路。
這樣就有效地幫助模型向簡潔且正確的思考路徑收斂,避免了對于每個解題路徑淺嘗輒止的underthinking問題。
感興趣的朋友可到原文查看更多細節。
論文標題:S-GRPO: Early Exit via Reinforcement Learning in Reasoning Models
論文鏈接:https://arxiv.org/abs/2505.07686
— 完 —
- 又一高管棄庫克而去!蘋果UI設計負責人轉投Meta2025-12-04
- 萬卡集群要上天?中國硬核企業打造太空超算!2025-11-29
- 學生3年投稿6次被拒,于是吳恩達親手搓了個評審Agent2025-11-25
- 波士頓動力前CTO加盟DeepMind,Gemini要做機器人界的安卓2025-11-25









