
為什么ChatGPT沒有誕生在中國?三只「攔路虎」|CCF C3
算力人力和試錯成本
ChatGPT爆火之后,算力問題也被推到了風口浪尖。
根據(jù)OpenAI CEO的說法,每調(diào)用一次ChatGPT就會消耗幾美分。那么如果全球每人都搜索一下,為什么OpenAI不會破產(chǎn)?
全國的A100顯卡就那么幾萬卡,如果大家都去煉大模型,算力不夠用怎么辦?
……
CCF CTO Club發(fā)起的最新一期CCF C3活動就來到并行科技,話題聚焦于“算力網(wǎng)絡賦能人工智能”,以ChatGPT這一熱門話題為引子,展開了一場多維度的主題分享和討論。

據(jù)統(tǒng)計,線上約有9500人圍觀了此次活動。
所以,具體都講了些什么?
訓練千億大模型,至少面臨三大挑戰(zhàn)
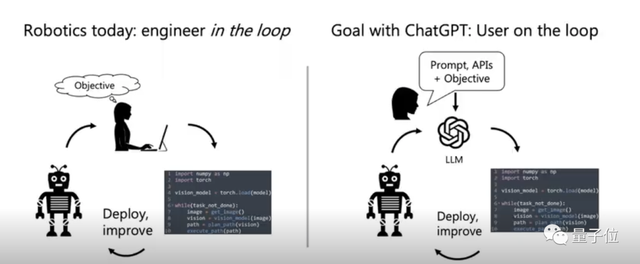
活動最先開始的主題分享環(huán)節(jié),北京大學人工智能研究院助理教授(博導)楊耀東講了一個非常有趣的東西,即微軟最新公布的一個研究項目。

該項目直接將ChatGPT的輸出接到一個機械臂以及一個微機上。然后通過人與ChatGPT交互,來控制機械臂完成特定任務,比如用一堆方塊拼成一個微軟的logo。

楊耀東告訴大家,這項研究非常有意義。
如下圖所示,以往我們要完成類似任務,需要人去編程。
現(xiàn)在有了ChatGPT之后,我們要做的就不再是設計程序,而是設計一個prompt或者是一個instruct,讓ChatGPT通過這個prompt或instruct去編程,進而完成對機械臂的控制。
ChatGPT還有這種妙處?著實讓人感到驚喜。
那么問題來了:
這么一個好東西,為什么沒有先在中國誕生?是我們完全沒有關注這件事情嗎?
北京智譜華章科技有限公司的CEO張鵬,在ChatGPT爆火后經(jīng)常被問到這個問題。

對此,他想說,并非沒有關注,國內(nèi)如華為、達摩院、清華大學等機構(gòu)一直在做類似的事情。
比如清華大學知識工程實驗室(KEG)與智譜AI共同研發(fā)的大規(guī)模中英文預訓練語言模型GLM-130B。
它可與GPT-3基座模型對標,在同等運算速度與精度的要求下,GLM-130B對顯存資源的消耗可節(jié)省75%,自2022年8月發(fā)布以來,已收到41個國家266個研究機構(gòu)的使用需求。
在Stanford報告的世界主流大模型評測中,它更是中國唯一入選的模型,其準確性、惡意性與GPT-3持平,魯棒性和校準誤差在所有模型中表現(xiàn)最佳。
但,不得不承認,ChatGPT的實力確實非常強大。
而我們要想訓練類似一個千億大模型,至少要面臨三大挑戰(zhàn):
一、高昂的訓練成本。比如ChatGPT的算力需求就是“A100x1000塊x30天”。
二、人力投入極大。比如谷歌PaLM 530B團隊,前期準備29人,訓練過程11人,整個作者列表68人,而目前國內(nèi)可用做大模型的高精尖人才不超過百人。
三、訓練過程不穩(wěn)定,且調(diào)試困難,容易出現(xiàn)訓練不收斂現(xiàn)象。
張鵬指出,在這些問題之中,算力絕對是非常重要的因素。
他曾經(jīng)估算過,從GPT3開始到ChatGPT的誕生,中間用來訓練模型用的算力,達到了億美金以上的規(guī)模。
更別說這還只是對“成功部分”的估計,如果算上訓練失敗和試錯的成本,這個數(shù)字肯定又要翻幾番。
因此,我們要想搞千億大模型,算力問題一定不可忽視。
算力網(wǎng)絡實現(xiàn)算力全國共享
根據(jù)IDC發(fā)布的報告,中國AI算力規(guī)模增長飛速,2022年為268EFLOPS,到2026年則可達1271.4EFLOPS。
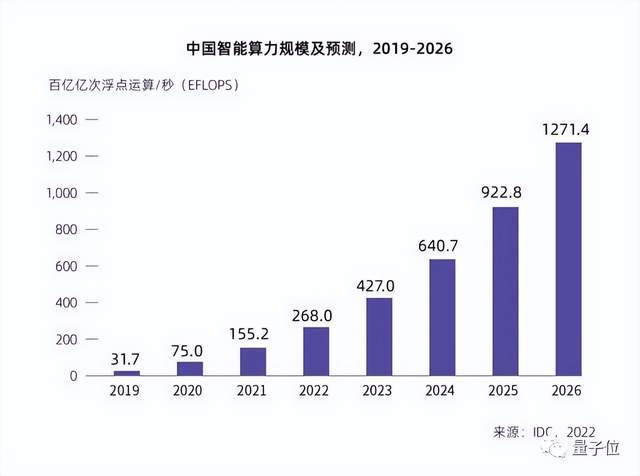
但在并行科技董事長陳健看來,ChatGPT爆火之后,這個增長速度根本不夠:大家要么仍然缺算力,要么缺合適的算力。
因此,他提出了“可用、好用以及降本”這三個概念。
他介紹道,并行科技從超算起家,一直專注于算力行業(yè),目前公司在做的全國一體化算力網(wǎng)絡,就是要將國內(nèi)優(yōu)質(zhì)的超算、智算與通用算力全部聚合起來,形成一個算力資源、應用資源、數(shù)據(jù)資源可以共享和交易的算力網(wǎng)絡。
這個網(wǎng)絡可以確保當我們需要用算力的時候,只要中國還有可用的空閑算力,我們就能用到。
當然,它的價格一定要合理。

據(jù)悉,并行科技目前與廣州超算、北京超算、濟南超算、中科院超算、浙江超算、寧夏超算等國產(chǎn)算力資源在內(nèi)的大批優(yōu)質(zhì)算力資源結(jié)合,共計接入超80000臺服務器,總計算力超1000PFlops,存儲資源超800PB。
算法優(yōu)化也是一條途徑
在主題討論環(huán)節(jié),大家一齊分享了自己對如何解決算力需求這個問題的看法。
在智譜AI CEO張鵬看來,算力是由市場驅(qū)動的,只要符合市場需求,創(chuàng)造出真正的社會價值,就有辦法解決。
而且,這個辦法一定是多元化的。
比如在硬件層面,我們可以打造更先進的芯片;在宏觀資源調(diào)度方面,如并行科技陳健所說,算力網(wǎng)絡是一個好思路。
而最終,可能將形成宏觀層有算力網(wǎng)絡,硬件層有強大芯片,中間層有軟件做算法優(yōu)化與加速這種“多向奔赴”的方式。
此外,他也認為,特異化也可能會成為解決AI算力的一種趨勢。因為就拿芯片來說,通用芯片的成本一定會比專用的高。
對此,中科院計算機網(wǎng)絡信息中心AI技術(shù)與應用發(fā)展部負責人王彥棡補充道,在人工智能領域,軟件的確是需要大家關注的重點,它是構(gòu)成行業(yè)生態(tài)的關鍵,容易出現(xiàn)“卡脖子”問題,做好未雨綢繆,才能應對不斷變化的發(fā)展時局。
陳健則在這個環(huán)節(jié)分享了當天刷到的一條朋友圈:
已經(jīng)摸到一定高度的情況下,再去比參數(shù)誰多是不明智的。要比誰用更少的參數(shù),更少的算力,也能達到同樣的效果,包括性能和體驗。
這條朋友圈來自某位行業(yè)專家。
陳健對此頗為贊同,他表示:我們做優(yōu)化的都知道,最好的優(yōu)化不是在硬件上去調(diào)整性能,而是用一個更好的算法,讓總計算量降下去,從而提高更好的體驗。
因此,陳健認為,這也是解決算力問題一個非常非常好的路徑,如果這一點上能突破,可能對算力公司來說不是好消息,但是對于我們整個社會來說是非常巨大的進步。

接下來,大家還就本期的主題算力網(wǎng)絡進行了更深一步的討論。
并行科技AI云事業(yè)部總經(jīng)理趙鴻冰表示,算力網(wǎng)絡接下來的發(fā)展重點是算力接入標準化。有了標準,更多算力資源才能被有效的接入到算力網(wǎng)絡中,滿足需求端的靈活使用。
歷史上,電力網(wǎng)絡的構(gòu)建曾為人類帶來福祉。現(xiàn)在我們也可以暢想一下,未來是否可以基于算力網(wǎng)絡來實現(xiàn)大模型訓練。
當然,這需要我們在算力網(wǎng)絡分布式計算技術(shù)等相關領域做進一步研究。
現(xiàn)場提問
本場活動的最后環(huán)節(jié),是留給線上線下觀眾的現(xiàn)場提問,不少人將目光聚集到了ChatGPT本身。
有人關心ChatGPT是否需要做算法方面的創(chuàng)新。
對此,楊耀東表示,對它來說,可能不需要。
他引用了ChatGPT項目負責人的一句話:
人們通常會低估一個簡單的想法實現(xiàn)好后對效能的增長;而過于高估一個全新想法能帶來的效能增長。
因此他認為,即便ChatGPT看似簡單,如果能在工程化方面做到極致,也會有非常好的應用效果。
前些日子,有研究發(fā)現(xiàn)ChatGPT背后的大模型具有9歲兒童心智。
現(xiàn)在,也有人將類似問題拋給了現(xiàn)場嘉賓:
基于ChatGPT目前在應用中的表現(xiàn),是否可以判定它已經(jīng)產(chǎn)生了智能?
對于這個問題,楊耀東也發(fā)表了看法。他認為從某種角度上來看,我們可以說ChatGPT已經(jīng)產(chǎn)生了“智能”。就比如面對雞兔同籠問題,換個數(shù)它依然能解,不會出現(xiàn)突然到某個層級不能泛化的問題。
但是它底層的模型,說到底就是一些Encode和Decoder,基于Attentio架構(gòu)的東西。它為什么能涌現(xiàn)出這么復雜的pattern?
這還是數(shù)據(jù)帶來的歸納偏置非常多以后,涌現(xiàn)出來一定意義上的智能所帶來的。
但是這個智能是不是我們科學意義上定義的智能,或者我們怎么去定義智能——這個問題本身還很難說清楚。
關于CCF C3
CCF C3活動是由中國計算機學會CCF CTO Club發(fā)起的,旨在聯(lián)結(jié)企業(yè)CTO及高級技術(shù)人才和資深學者,每次以一個技術(shù)話題為核心,走進一家技術(shù)領先企業(yè)。
往期活動承辦單位與主題如下表所示:

下一期,C3將移步上海,由小紅書承辦,時間為3月30日。
- 北大開源最強aiXcoder-7B代碼大模型!聚焦真實開發(fā)場景,專為企業(yè)私有部署設計2024-04-09
- 剛剛,圖靈獎揭曉!史上首位數(shù)學和計算機最高獎“雙料王”出現(xiàn)了2024-04-10
- 8.3K Stars!《多模態(tài)大語言模型綜述》重大升級2024-04-10
- 谷歌最強大模型免費開放了!長音頻理解功能獨一份,100萬上下文敞開用2024-04-10
相關閱讀










