
嬴徹科技拿下SemanticKITTI榜單兩項第一
SemanticKITTI是激光雷達語義分割的重要基準之一
蕭簫 發(fā)自 凹非寺
量子位 報道 | 公眾號 QbitAI
在感知算法領域,嬴徹科技近期憑借「精準語義分割3D感知技術」,在SemanticKITTI 的「語義分割」和「全景語義分割」兩項任務中奪得第一,領先于來自MIT、芝加哥大學、阿里、華為等全球各地的100多支隊伍。
語義分割是自動駕駛感知算法的關鍵技術,能識別出各種場景物體,告訴汽車“身邊有什么危險”,從而保障出行安全。
KITTI是目前發(fā)布最早、影響力最大的自動駕駛算法評測數據集。
SemanticKITTI是KITTI在語義分割方向的子數據集,是激光雷達語義分割的重要基準之一。為了推動激光雷達的語義分割研究,SemanticKITTI舉辦了3D語義分割比賽,包括「語義分割」和「全景語義分割」等任務。
任務一 「語義分割」,要求能準確識別出場景中的物體類型(如汽車、行人);任務二 「全景語義分割」,要求對場景中的所有物體都進行精確個體級辨識,即類型基礎上,為每個物體賦予1個ID(如1號車、2號車……)。
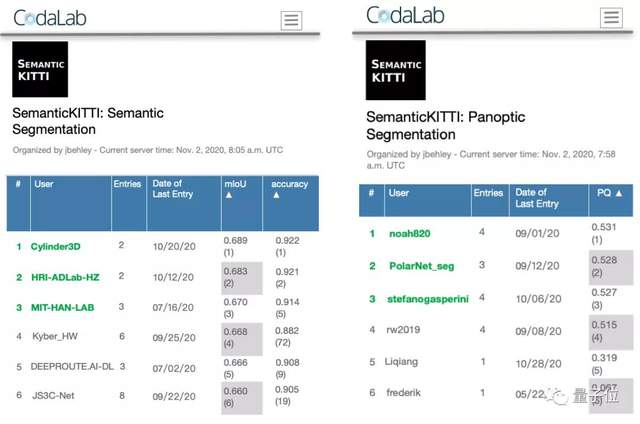
△ 榜首的Cylinder3D & noah820為來自嬴徹科技的兩支參賽團隊
相較于傳統(tǒng)的激光雷達語義分割算法,嬴徹這次做出了哪些突破?來自嬴徹Inceptio X-Lab的李偉博士,與量子位詳細分享了其中的技術原理。
1、從“劃井字”到“切蛋糕”, 使點云分割更均衡
在點云分割上,算法實現了「圓柱坐標系下的體素劃分」。
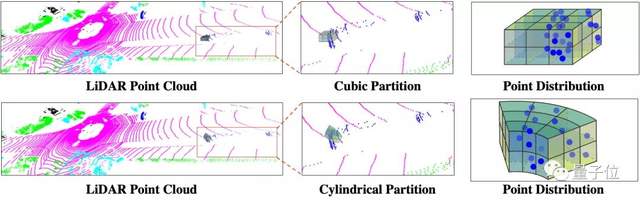
李偉博士用“劃井字”和“切蛋糕”,對這一突破進行了類比。傳統(tǒng)激光雷達點云的分割方法,就像是正正經經劃“井”字一樣,將空間劃成多個方塊,但是單個體素塊內的點云就會出現近多遠少、分布不均衡的問題;
那么,“圓柱坐標系下的體素劃分”,就是從激光雷達扇形掃描的特性出發(fā),即更加符合點云數據的分布特點,以“切蛋糕”的方式進行分區(qū)。近處密集的點,單元劃分空間也小;遠處稀疏的點,單元劃分空間就更大,體素塊內點云更均勻。
2、“核骨架增強”,揭開半遮半掩的面紗
做目標檢測的小伙伴們都有過這樣的經歷:一個完整的物體,AI通常都能檢測出來。
然而如果這個物體“遮遮掩掩”,檢測效果就大打折扣。
通過識別這個物體的核骨架(skeleton of the kernel),就能夠撥開面紗檢測出物體。

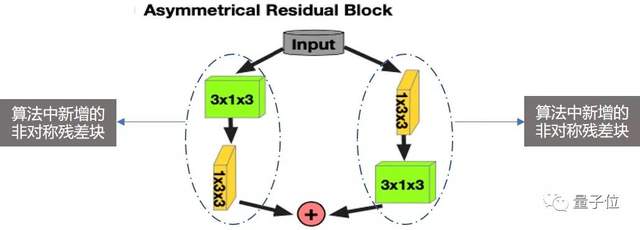
為達到這個目的,在數據處理的部分,算法中新增了「非對稱3維神經網絡模塊」。
這一模塊,在水平和垂直兩個方向分別增強卷積核,能更好地匹配駕駛場景下的物體形狀分布,從多角度更全面地看到每個點云的狀態(tài),即使在遮擋或是稀疏點云輸入的情況下,也能準確地辨別物體。
3、從單一劃區(qū)到塊點結合,精細區(qū)分小物體
區(qū)塊檢測是目前常用的方法,缺點是不同類別的點云有可能被劃分到一個體素塊內,物體分割的細節(jié)容易丟失,準確性降低。
嬴徹在劃區(qū)的基礎上,再進行「單個三維點云級別的分割」,獲得精細細節(jié)。如下圖所示,嬴徹的方法有效在一個小區(qū)域中繼續(xù)精確分割出更小的物體。
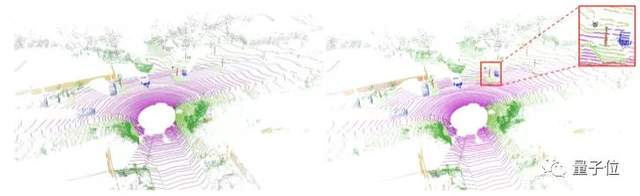
塊點結合檢測的效果,不僅辨識精度更高,且更易于小物體的識別,極大地提升了高速行車的安全性。
嬴徹此次發(fā)布的「精準語義分割3D感知技術」,基于激光雷達的感知算法,與純攝像頭方案形成雙重冗余,滿足在多場景下、尤其是夜晚的感知需求。
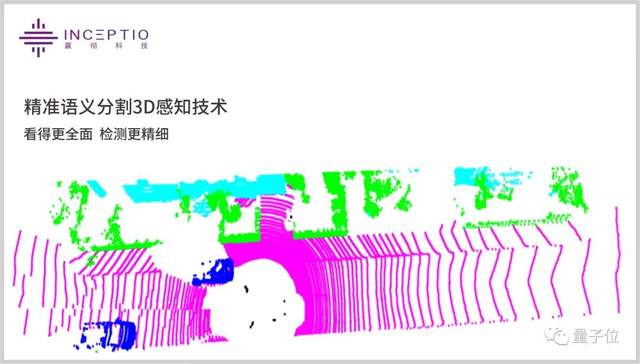
此外,這一算法還能更魯棒、更及時的感知高速公路上突發(fā)遇到的小物體,如突然躥出的小動物,從而更及時做出路徑規(guī)劃,確保高速行車安全。
比賽鏈接:
https://competitions.codalab.org/competitions/24025#results
https://competitions.codalab.org/competitions/20331#results
http://www.semantic-kitti.org/
paper鏈接:
https://arxiv.org/abs/2011.10033
https://arxiv.org/abs/2011.11964
code鏈接:
https://github.com/xinge008/Cylinder3D
- 首個GPT-4驅動的人形機器人!無需編程+零樣本學習,還可根據口頭反饋調整行為2023-12-13
- IDC霍錦潔:AI PC將顛覆性變革PC產業(yè)2023-12-08
- AI視覺字謎爆火!夢露轉180°秒變愛因斯坦,英偉達高級AI科學家:近期最酷的擴散模型2023-12-03
- 蘋果大模型最大動作:開源M芯專用ML框架,能跑70億大模型2023-12-07
相關閱讀

馭勢科技無人駕駛新品首秀鄂州機場,助力發(fā)布《機場無人駕駛設備應用路線圖》
馭勢科技在本次會議期間通過展臺向來賓介紹了自主研發(fā)的民航無人駕駛全場景解決方案,同時于鄂州機場數字化工地進行了無人駕駛行李牽引車與無人駕駛引導車機坪協(xié)同作業(yè)演示。這是馭勢科技無人駕駛引導車的業(yè)內首次亮相。








