騰訊優(yōu)圖10篇AAAI論文解析,涉及數(shù)學(xué)速算批改、視頻識別和語義分割 | 附下載
雷剛 發(fā)自 凹非寺
量子位 報道 | 公眾號 QbitAI
AI頂會AAAI開幕在即,入選論文悉數(shù)披露。
今日介紹10篇論文,來自騰訊旗下視覺研發(fā)平臺騰訊優(yōu)圖,涉及數(shù)學(xué)速算批改、視頻識別、語義分割等技術(shù)領(lǐng)域,跨越安防、交通、教育和醫(yī)療等場景,是騰訊優(yōu)圖最新研發(fā)成果。
作為人工智能領(lǐng)域最悠久、涵蓋內(nèi)容最廣泛的學(xué)術(shù)會議之一,AAAI會議的論文內(nèi)容涉及AI和機(jī)器學(xué)習(xí)所有領(lǐng)域,關(guān)注的傳統(tǒng)主題包括但不限于自然語言處理、深度學(xué)習(xí)等,同時大會還關(guān)注跨技術(shù)領(lǐng)域主題,如AI+行業(yè)應(yīng)用等。
AAAI 2020將于2月7日-2月12日在美國紐約舉辦,根據(jù)目前披露的信息,最終收到有效論文8800篇,接收1591篇,接受率20.6%。
而騰訊優(yōu)圖這10篇入選論文,詳情如下:

具體解讀
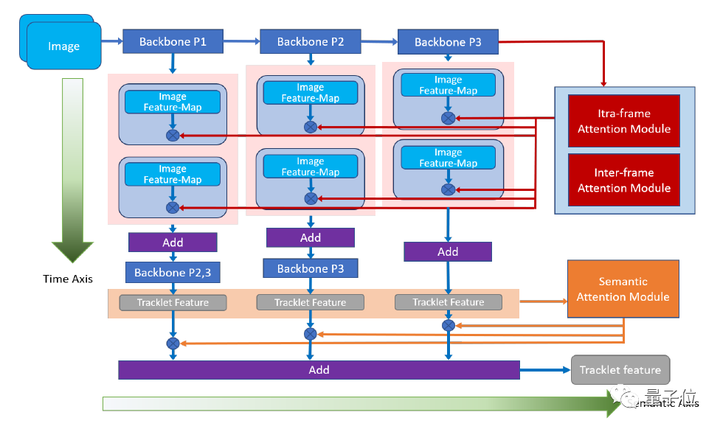
1. 從時間和語義層面重新思考時間域融合用于基于視頻的行人重識別(Oral)
Rethinking Temporal Fusion for Video-based Person Re-identification on Semantic and Time Aspect (Oral)
關(guān)鍵詞:行人重識別、時間和語義、時間融合
論文鏈接:https://arxiv.org/abs/1911.12512
解析:近年來對行人重識別(ReID)領(lǐng)域的研究不斷深入,越來越多的研究者開始關(guān)注基于整段視頻信息的聚合,來獲取人體特征的方法。
然而,現(xiàn)有人員重識別方法,忽視了卷積神經(jīng)網(wǎng)絡(luò)在不同深度上提取信息在語義層面的差別,因此可能造成最終獲取的視頻特征表征能力的不足。
此外,傳統(tǒng)方法在提取視頻特征時沒有考慮到幀間的關(guān)系,導(dǎo)致時序融合形成視頻特征時的信息冗余,和以此帶來的對關(guān)鍵信息的稀釋。
為了解決這些問題,本文提出了一種新穎、通用的時序融合框架,同時在語義層面和時序?qū)用嫔蠈畔⑦M(jìn)行聚合。
在語義層面上,本文使用多階段聚合網(wǎng)絡(luò)在多個語義層面上對視頻信息進(jìn)行提取,使得最終獲取的特征更全面地表征視頻信息。
而在時間層面上,本文對現(xiàn)有的幀內(nèi)注意力機(jī)制進(jìn)行了改進(jìn),加入幀間注意力模塊,通過考慮幀間關(guān)系來有效降低時序融合中的信息冗余。
實(shí)驗結(jié)果顯示本文的方法能有效提升基于視頻的行人識別準(zhǔn)確度,達(dá)到目前最佳的性能。
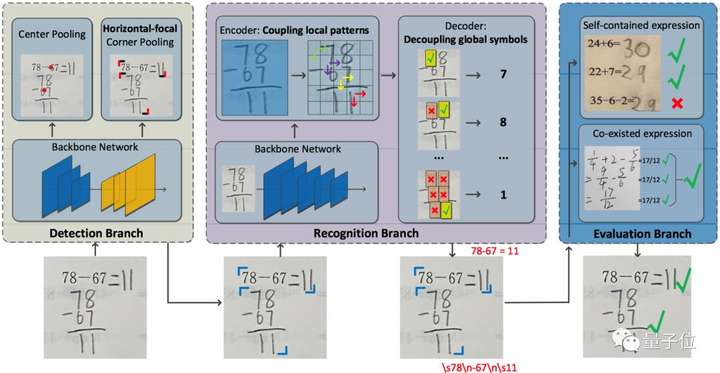
2.速算批改中的帶結(jié)構(gòu)文本識別
Accurate Structured-Text Spotting for Arithmetical Exercise Correction
關(guān)鍵字:速算批改,算式檢測與識別
對于中小學(xué)教師而言,數(shù)學(xué)作業(yè)批改一直是一項勞動密集型任務(wù),為了減輕教師的負(fù)擔(dān),本文提出算術(shù)作業(yè)檢查器,一個自動評估圖像上所有算術(shù)表達(dá)式正誤的系統(tǒng)。
其主要挑戰(zhàn)是,算術(shù)表達(dá)式往往是由具有特殊格式(例如,多行式,分?jǐn)?shù)式)的印刷文本和手寫文本所混合組成的。
面臨這個挑戰(zhàn),傳統(tǒng)的速算批改方案在實(shí)際業(yè)務(wù)中暴露出了許多問題。本文在算式檢測和識別兩方面,針對實(shí)際問題提出了解決方案。
針對算式檢測中出現(xiàn)的非法算式候選問題,文中在無需錨框的檢測方法CenterNet的基礎(chǔ)上,進(jìn)一步設(shè)計了橫向邊緣聚焦的損失函數(shù)。
CenterNet通過捕捉對象的兩個邊角位置來定位算式對象,同時學(xué)習(xí)對象內(nèi)部的信息作為補(bǔ)充,避免生成 ”中空“的對象,在算式檢測任務(wù)上具有較好的適性。
橫向邊緣聚焦的損失函數(shù)進(jìn)一步把損失更新的關(guān)注點(diǎn)放在更易產(chǎn)生、更難定位的算式左右邊緣上,避免產(chǎn)生合理卻不合法的算式候選。該方法在檢測召回率和準(zhǔn)確率上都有較為明顯的提升。
在算式識別框方面,為避免無意義的上下文信息干擾識別結(jié)果,文中提出基于上下文門函數(shù)的識別方法。
該方法利用一個門函數(shù)來均衡圖像表征和上下文信息的輸入權(quán)重,迫使識別模型更多地學(xué)習(xí)圖像表征,從而避免無意義的上下文信息干擾識別結(jié)果。
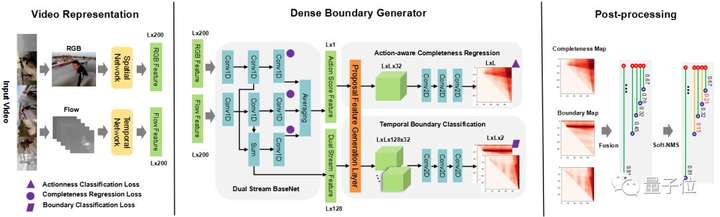
3. 基于稠密邊界生成器的時序動作提名的快速學(xué)習(xí)
Fast Learning of Temporal Action Proposal via Dense Boundary Generator
關(guān)鍵詞:DBG動作檢測法、算法框架、開源
論文鏈接:https://arxiv.org/abs/1911.04127
視頻動作檢測技術(shù)是精彩視頻集錦、視頻字幕生成、動作識別等任務(wù)的基礎(chǔ),隨著互聯(lián)網(wǎng)的飛速發(fā)展,在產(chǎn)業(yè)界中得到越來越廣泛地應(yīng)用,而互聯(lián)網(wǎng)場景視頻內(nèi)容的多樣性也對技術(shù)提出了很多的挑戰(zhàn),如視頻場景復(fù)雜、動作長度差異較大等。
針對這些挑戰(zhàn), 本文針對DBG動作檢測算法,提出3點(diǎn)創(chuàng)新:
- (1)提出一種快速的、端到端的稠密邊界動作生成器(Dense Boundary Generator,DBG)。該生成器能夠?qū)λ械膭幼魈崦╬roposal)估計出稠密的邊界置信度圖。
- (2)引入額外的時序上的動作分類損失函數(shù)來監(jiān)督動作概率特征(action score feature,asf),該特征能夠促進(jìn)動作完整度回歸(Action-aware Completeness Regression,ACR)。
- (3)設(shè)計一種高效的動作提名特征生成層(Proposal Feature Generation Layer,PFG),該Layer能夠有效捕獲動作的全局特征,方便實(shí)施后面的分類和回歸模塊。
其算法框架主要包含視頻特征抽取(Video Representation),稠密邊界動作檢測器(DBG),后處理(Post-processing)三部分內(nèi)容。
目前騰訊優(yōu)圖DBG的相關(guān)代碼已在GitHub上開源,并在ActivityNet上排名第一。
傳送門:https://github.com/TencentYoutuResearch/ActionDetection-DBG
4. TEINet:邁向視頻識別的高效架構(gòu)
TEINet: Towards an Efficient Architecture for Video Recognition
關(guān)鍵詞:TEI模塊、時序建模、時序結(jié)構(gòu)
論文鏈接:https://arxiv.org/abs/1911.09435
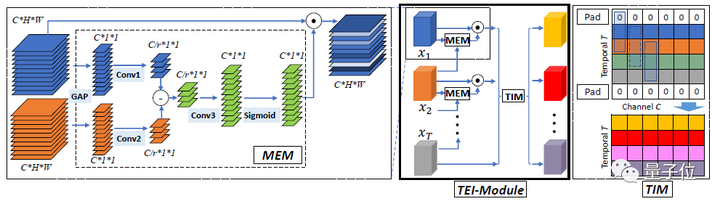
本文提出了一種快速的時序建模模塊,即TEI模塊。
該模塊能夠輕松加入已有的2D CNN網(wǎng)絡(luò)中。與以往的時序建模方式不同,TEI通過channel維度上的attention以及channel維度上的時序交互來學(xué)習(xí)時序特征。
首先,TEI所包含的MEM模塊能夠增強(qiáng)運(yùn)動相關(guān)特征,同時抑制無關(guān)特征(例如背景),然后TEI中的TIM模塊在channel維度上補(bǔ)充前后時序信息。
這兩個模塊不僅能夠靈活而有效地捕捉時序結(jié)構(gòu),而且在inference時保證效率。本文通過充分實(shí)驗在多個benchmark上驗證了TEI中兩個模塊的有效性。
5. 通過自監(jiān)督特征學(xué)習(xí)重新審視圖像美學(xué)質(zhì)量評估
Revisiting Image Aesthetic Assessment via Self-Supervised Feature Learning
關(guān)鍵詞:美學(xué)評估、自我監(jiān)督、計算機(jī)視覺
論文鏈接:https://arxiv.org/abs/1911.11419
圖像美學(xué)質(zhì)量評估是計算機(jī)視覺領(lǐng)域中一個重要研究課題。近年來,研究者們提出了很多有效的方法,在美學(xué)評估問題上取得了很大進(jìn)展。這些方法基本上都依賴于大規(guī)模的、與視覺美學(xué)相關(guān)圖像標(biāo)簽或?qū)傩裕@些信息往往需要耗費(fèi)巨大人力成本。
為了能夠緩解人工標(biāo)注成本,“使用自監(jiān)督學(xué)習(xí)來學(xué)習(xí)具有美學(xué)表達(dá)力的視覺表征”是一個具有研究價值的方向。
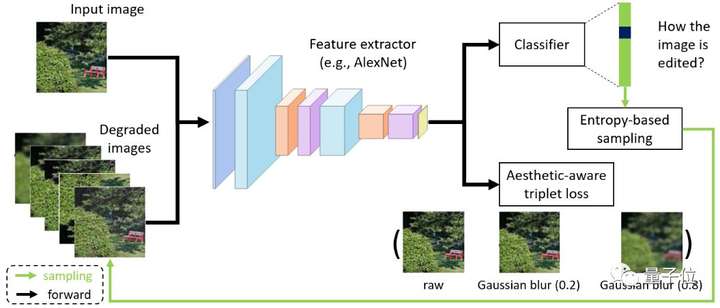
本文在這個方向上提出了一種簡單且有效的自監(jiān)督學(xué)習(xí)方法。我們方法的核心動機(jī)是:若一個表征空間不能鑒別不同的圖像編輯操作所帶來的美學(xué)質(zhì)量的變化,那么這個表征空間也不適合圖像美學(xué)質(zhì)量評估任務(wù)。
從這個動機(jī)出發(fā),本文提出了兩種不同的自監(jiān)督學(xué)習(xí)任務(wù):一個用來要求模型識別出施加在輸入圖像上的編輯操作的類型;另一個要求模型區(qū)分同一類操作在不同控制參數(shù)下所產(chǎn)生的美學(xué)質(zhì)量變動的差異,以此來進(jìn)一步優(yōu)化視覺表征空間。
為了對比實(shí)驗的需要,本文將提出的方法與現(xiàn)有的經(jīng)典的自監(jiān)督學(xué)習(xí)方法(如,Colorization,Split-brain,RotNet等)進(jìn)行比較。
實(shí)驗結(jié)果表明:在三個公開的美學(xué)評估數(shù)據(jù)集上(即AVA,AADB,和CUHK-PQ),本文的方法都能取得頗具競爭力的性能。而且值得注意的是:本文的方法能夠優(yōu)于直接使用 ImageNet 或者 Places 數(shù)據(jù)集的標(biāo)簽來學(xué)習(xí)表征的方法。
此外,我們還驗證了:在 AVA 數(shù)據(jù)集上,基于我們方法的模型,能夠在不使用 ImageNet 數(shù)據(jù)集的標(biāo)簽的情況下,取得與最佳方法相當(dāng)?shù)男阅堋?/p>
6. 基于生成模型的視頻域適應(yīng)技術(shù)
Generative Adversarial Networks for Video-to-Video Domain Adaptation
關(guān)鍵字:視頻生成,無監(jiān)督學(xué)習(xí),域適應(yīng)
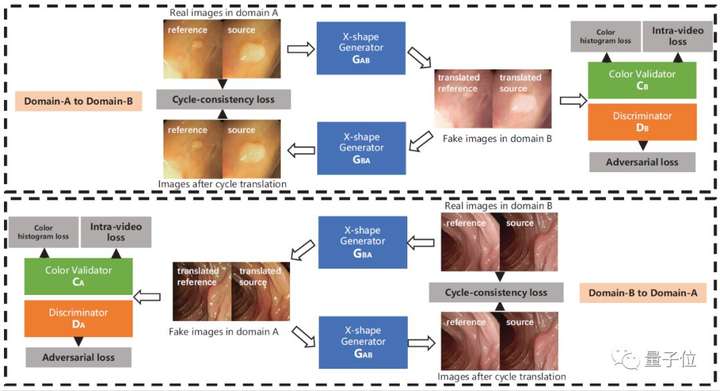
來自多中心的內(nèi)窺鏡視頻通常具有不同的成像條件,例如顏色和照明,這使得在一個域上訓(xùn)練的模型無法很好地推廣到另一個域。域適應(yīng)是解決該問題的潛在解決方案之一。但是,目前很少工作能集中在視頻數(shù)據(jù)域適應(yīng)處理任務(wù)上。
為解決上述問題,本文提出了一種新穎的生成對抗網(wǎng)絡(luò)(GAN)即VideoGAN,以在不同域之間轉(zhuǎn)換視頻數(shù)據(jù)。
實(shí)驗結(jié)果表明,由VideoGAN生成的域適應(yīng)結(jié)腸鏡檢查視頻,可以顯著提高深度學(xué)習(xí)網(wǎng)絡(luò)在多中心數(shù)據(jù)集上結(jié)直腸息肉的分割準(zhǔn)確度。
由于我們的VideoGAN是通用的網(wǎng)絡(luò)體系結(jié)構(gòu),因此本文還將CamVid駕駛視頻數(shù)據(jù)集上進(jìn)行了測試。實(shí)驗表明, 我們的VideoGAN可以大大縮小域間差距。
7. 非對稱協(xié)同教學(xué)用于無監(jiān)督的跨領(lǐng)域行人再識別
Asymmetric Co-Teaching for Unsupervised Cross-Domain Person Re-Identification
關(guān)鍵詞:行人重識別、非對稱協(xié)同教學(xué)、域適應(yīng)
論文鏈接:https://arxiv.org/abs/1912.01349
行人重識別由于樣本的高方差及成圖質(zhì)量,一直以來都是極具挑戰(zhàn)性的課題。雖然在一些固定場景下的re-ID取得了很大進(jìn)展(源域),但只有極少的工作能夠在模型未見過的目標(biāo)域上得到很好的效果。
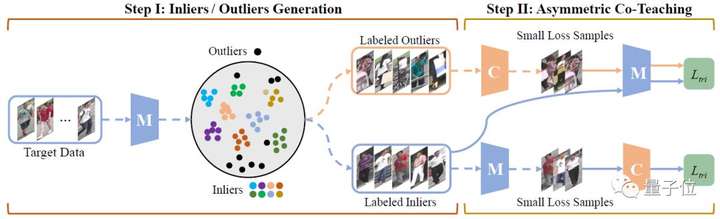
目前有一種有效解決方法,是通過聚類為無標(biāo)記數(shù)據(jù)打上偽標(biāo)簽,輔助模型適應(yīng)新場景,然而,聚類往往會引入標(biāo)簽噪聲,并且會丟棄低置信度樣本,阻礙模型精度提升。
本文通過提出非對稱協(xié)同教學(xué)方法,更有效地利用挖掘樣本,提升域適應(yīng)精度。具體來說,就是使用兩個網(wǎng)絡(luò),一個網(wǎng)絡(luò)接收盡可能純凈的樣本,另一個網(wǎng)絡(luò)接收盡可能多樣的樣本,在“類協(xié)同教學(xué)”的框架下,該方法在濾除噪聲樣本的同時,可將更多低置信度樣本納入到訓(xùn)練過程中。多個公開實(shí)驗可說明此方法能有效提升現(xiàn)階段域適應(yīng)精度,并可用于不同聚類方法下的域適應(yīng)。
8. 帶角度正則的朝向敏感損失用于行人再識別
Viewpoint-Aware Loss with Angular Regularization for Person Re-Identification
關(guān)鍵詞:行人重識別、朝向、建模
論文鏈接:https://arxiv.org/abs/1912.01300
近年來有監(jiān)督的行人重識別(ReID)取得了重大進(jìn)展,但是行人圖像間巨大朝向差異,使得這一問題仍然充滿挑戰(zhàn)。
大多數(shù)現(xiàn)有的基于朝向的特征學(xué)習(xí)方法,將來自不同朝向的圖像映射到分離和獨(dú)立的子特征空間當(dāng)中。
這種方法只建模了一個朝向下人體圖像的身份級別的特征分布,卻忽略了朝向間潛在的關(guān)聯(lián)關(guān)系。
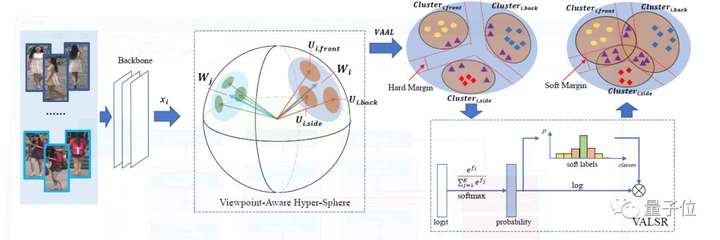
為解決這一問題,本文提出了一種新的方法,叫帶角度正則的朝向敏感損失(VA-ReID)。
相比每一個朝向?qū)W習(xí)一個子空間,該方法能夠?qū)碜圆煌虻奶卣饔成涞酵粋€超球面上,這樣就能同時建模身份級別和朝向級別的特征分布。在此基礎(chǔ)上,相比傳統(tǒng)分類方法將不同的朝向建模成硬標(biāo)簽,本文提出了朝向敏感的自適應(yīng)標(biāo)簽平滑正則方法(VALSR)。這一方法能夠給予特征表示自適應(yīng)的軟朝向標(biāo)簽,從而解決了部分朝向無法明確標(biāo)注的問題。
大量在Market1501和DukeMTMC數(shù)據(jù)集上的實(shí)驗證明了本文的方法有效性,其性能顯著超越已有的最好有監(jiān)督ReID方法。
9. 如何利用弱監(jiān)督信息訓(xùn)練條件對抗生成模型
Robust Conditional GAN from Uncertainty-Aware Pairwise Comparisons
關(guān)鍵詞:CGAN、弱監(jiān)督、成對比較
論文鏈接:https://arxiv.org/abs/1911.09298
條件對抗生成網(wǎng)絡(luò)(conditinal GAN, CGAN)已在近些年取得很大成就,并且在圖片屬性編輯等領(lǐng)域有成功的應(yīng)用。
但是CGAN往往需要大量標(biāo)注。為了解決這個問題,現(xiàn)有方法大多基于無監(jiān)督聚類,比如先用無監(jiān)督學(xué)習(xí)方法得到偽標(biāo)注,再用偽標(biāo)注當(dāng)作真標(biāo)注訓(xùn)練CGAN。
然而,當(dāng)目標(biāo)屬性是連續(xù)值而非離散值時,或者目標(biāo)屬性不能表征數(shù)據(jù)間的主要差異,那么這種基于無監(jiān)督聚類的方法就難以取得理想效果。
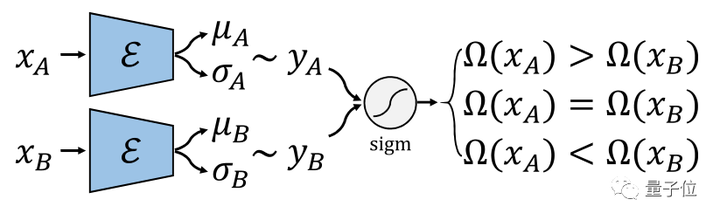
本文進(jìn)而考慮用弱監(jiān)督信息去訓(xùn)練CGAN,在文中我們考慮成對比較這種弱監(jiān)督。成對比較相較于絕對標(biāo)注具有以下優(yōu)點(diǎn):
1.更容易標(biāo)注;2.更準(zhǔn)確;3.不易受主觀影響。
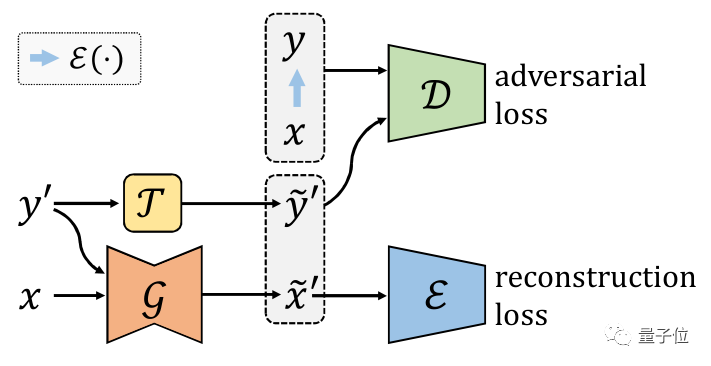
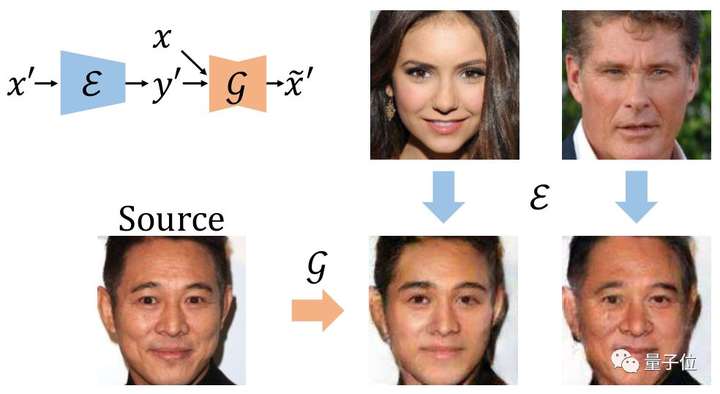
我們提出先訓(xùn)練一個比較網(wǎng)絡(luò)來預(yù)測每張圖片的得分,再將這個得分當(dāng)做條件訓(xùn)練CGAN。第一部分的比較網(wǎng)絡(luò)我們受到國際象棋等比賽中常用的等級分(Elo rating system)算法的啟發(fā),將一次成對比較的標(biāo)注視為一次比賽,用一個網(wǎng)絡(luò)預(yù)測圖片的得分,我們根據(jù)等級分設(shè)計了可以反向傳播學(xué)習(xí)的神經(jīng)網(wǎng)絡(luò)。
我們還考慮了網(wǎng)絡(luò)的貝葉斯版本,使網(wǎng)絡(luò)具有估計不確定性的能力。對于圖像生成部分,我們將魯棒條件對抗生成網(wǎng)絡(luò)(RObust Conditional GAN, RCGAN)拓展到條件是連續(xù)值的情形。具體的,與生成的假圖對應(yīng)的預(yù)測得分在被判別器接收之前會被一個重采樣過程污染。這個重采樣過程需要用到貝葉斯比較網(wǎng)絡(luò)的不確定性估計。
我們在四個數(shù)據(jù)集上進(jìn)行了實(shí)驗,分別改變?nèi)四槇D像的年齡和顏值。
實(shí)驗結(jié)果表明提出的弱監(jiān)督方法和全監(jiān)督基線相當(dāng),并遠(yuǎn)遠(yuǎn)好于非監(jiān)督基線。
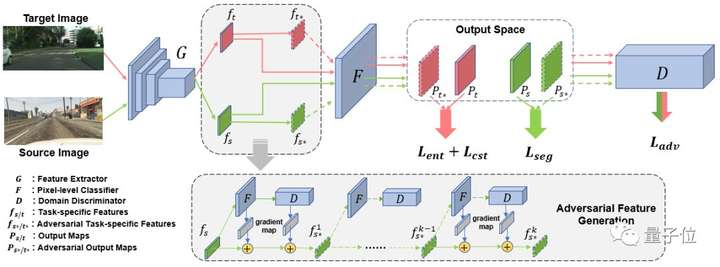
10. 基于對抗擾動的無監(jiān)督領(lǐng)域自適應(yīng)語義分割
An Adversarial Perturbation Oriented Domain Adaptation Approach for Semantic Segmentation
關(guān)鍵詞:無監(jiān)督領(lǐng)域自適應(yīng)、語義分割、對抗訓(xùn)練
論文鏈接:https://arxiv.org/pdf/1912.08954.pdf
如今神經(jīng)網(wǎng)絡(luò)借助大量標(biāo)注數(shù)據(jù)已經(jīng)能夠達(dá)到很好的效果,但是往往不能很好的泛化到一個新的環(huán)境中,而且大量數(shù)據(jù)標(biāo)注是十分昂貴的。因此,無監(jiān)督領(lǐng)域自適應(yīng)就嘗試借助已有的有標(biāo)注數(shù)據(jù)訓(xùn)練出模型,并遷移到無標(biāo)注數(shù)據(jù)上。
對抗對齊(adversarial alignment)方法被廣泛應(yīng)用在無監(jiān)督領(lǐng)域自適應(yīng)問題上,全局地匹配兩個領(lǐng)域間特征表達(dá)的邊緣分布。
但由于語義分割任務(wù)上數(shù)據(jù)的長尾分布(long-tail)嚴(yán)重且缺乏類別上的領(lǐng)域適配監(jiān)督,領(lǐng)域間匹配的過程最終會被大物體類別(如:公路、建筑)主導(dǎo),從而導(dǎo)致這種策略容易忽略尾部類別或小物體(如:紅路燈、自行車)的特征表達(dá)。
本文提出了一種生成對抗擾動并防御的框架。
首先該框架設(shè)計了幾個對抗目標(biāo)(分類器和鑒別器),并通過對抗目標(biāo)在兩個領(lǐng)域的特征空間分別逐點(diǎn)生成對抗樣本。這些對抗樣本連接了兩個領(lǐng)域的特征表達(dá)空間,并蘊(yùn)含網(wǎng)絡(luò)脆弱的信息。然后該框架強(qiáng)制模型防御對抗樣本,從而得到一個對于領(lǐng)域變化和物體尺寸、類別長尾分布都更魯棒的模型。
本文提出的對抗擾動框架,在兩個合成數(shù)據(jù)遷移到真實(shí)數(shù)據(jù)的任務(wù)上進(jìn)行了驗證。該方法不僅在圖像整體分割上取得了優(yōu)異的性能,并且大大提升了模型在小物體和類別上的精度,證明了其有效性。