
1個(gè)GPU幾分鐘搞定強(qiáng)化學(xué)習(xí)訓(xùn)練,谷歌新引擎讓深度學(xué)習(xí)提速1000倍丨開(kāi)源
博雯 發(fā)自 凹非寺
量子位 報(bào)道 | 公眾號(hào) QbitAI
機(jī)器人要如何完成這樣一個(gè)動(dòng)作?

我們一般會(huì)基于強(qiáng)化學(xué)習(xí),在仿真環(huán)境中進(jìn)行模擬訓(xùn)練。
這時(shí),如果在一臺(tái)機(jī)器的CPU環(huán)境下進(jìn)行模擬訓(xùn)練,那么需要幾個(gè)小時(shí)到幾天。
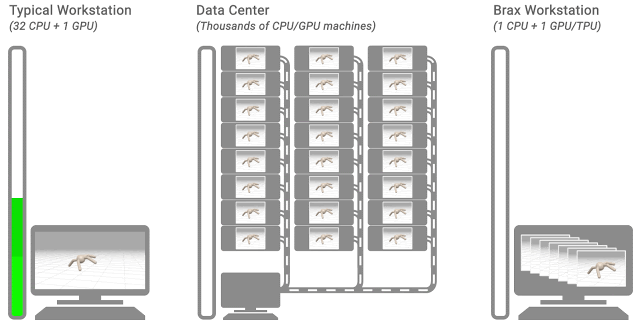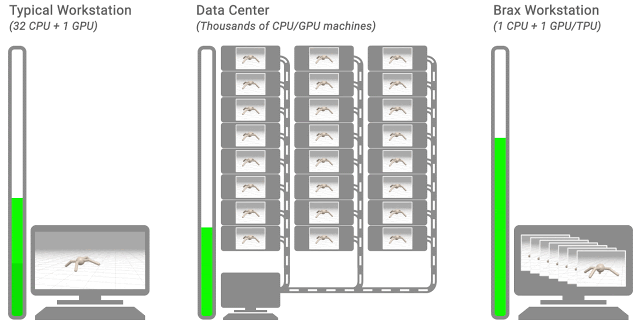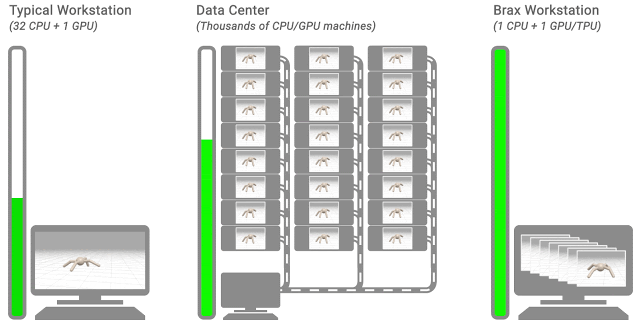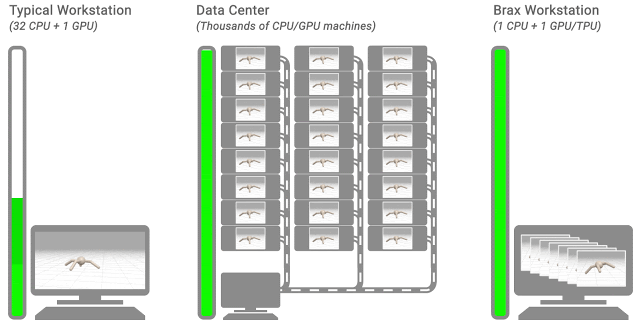
但現(xiàn)在,只需一個(gè)TPU/GPU,就能和數(shù)千個(gè)CPU或GPU的計(jì)算集群的速度一樣快,直接將所需時(shí)間縮短到幾分鐘!
相當(dāng)于將強(qiáng)化學(xué)習(xí)的速度提升了1000倍!
這就是來(lái)自谷歌的科學(xué)家們開(kāi)發(fā)的物理模擬引擎Brax。

三種策略避免邏輯分支
現(xiàn)在大多數(shù)的物理模擬引擎都是怎么設(shè)計(jì)的呢?
將重力、電機(jī)驅(qū)動(dòng)、關(guān)節(jié)約束、物體碰撞等任務(wù)都整合在一個(gè)模擬器中,并行地進(jìn)行多個(gè)模擬,以此來(lái)逼近現(xiàn)實(shí)中的運(yùn)動(dòng)系統(tǒng)。
這種情況下,每個(gè)模擬器中的計(jì)算都不相同,且數(shù)據(jù)必須在數(shù)據(jù)中心內(nèi)通過(guò)網(wǎng)絡(luò)傳輸。
這種并行布局也就導(dǎo)致了較高的延遲時(shí)間——即學(xué)習(xí)者可能需要超過(guò)10000納秒的等待時(shí)間,才能從模擬器中獲得經(jīng)驗(yàn)。
那么怎樣才能縮短這種延遲時(shí)間呢?
Brax選擇通過(guò)避免模擬中的分支來(lái)保證數(shù)千個(gè)并行環(huán)境中的計(jì)算完全統(tǒng)一,進(jìn)而降低整個(gè)訓(xùn)練架構(gòu)的復(fù)雜度。
直到復(fù)雜度降低到可以在單一的TPU或GPU上執(zhí)行,跨機(jī)器通信的計(jì)算開(kāi)銷就隨之降低,延遲也就能被有效消除。
主要分為以下三個(gè)方法:
- 連續(xù)函數(shù)替換離散分支邏輯
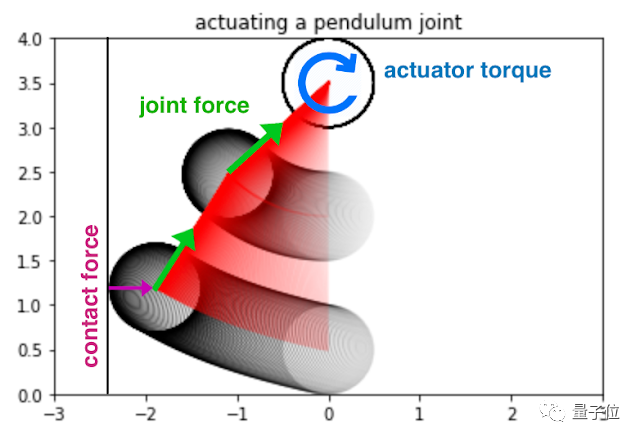
比如,在計(jì)算一個(gè)小球與墻壁之間的接觸力時(shí),就產(chǎn)生了一個(gè)分支:
如果球接觸墻壁,就執(zhí)行模擬球從墻壁反彈的獨(dú)立代碼;
否則,就執(zhí)行其他代碼;
這里就可以通過(guò)符號(hào)距離函數(shù)來(lái)避免這種if/else的離散分支邏輯的產(chǎn)生。
- 使用JAX即時(shí)編譯中評(píng)估分支
在仿真時(shí)間之前評(píng)估基于環(huán)境靜態(tài)屬性的分支,例如兩個(gè)物體是否有可能發(fā)生碰撞。
- 在模擬中只選擇需要的分支結(jié)果
在使用了這三種策略之后,我們就得到了一個(gè)模擬由剛體、關(guān)節(jié)、執(zhí)行器組成環(huán)境的物理引擎。
同時(shí)也是一種實(shí)現(xiàn)在這種環(huán)境中各類操作(如進(jìn)化策略,直接軌跡優(yōu)化等)的學(xué)習(xí)算法。
那么Brax的性能究竟如何呢?
速度最高提升1000倍
Brax測(cè)試所用的基準(zhǔn)是OpenAI Gym中Ant、HalfCheetah、Humanoid、Reacher四種。
同時(shí)也增加了三個(gè)新環(huán)境:包括對(duì)物理的靈巧操作、通用運(yùn)動(dòng)(例如前往周圍任何一個(gè)放置了物體的地點(diǎn))、以及工業(yè)機(jī)器人手臂的模擬:



研究人員首先測(cè)試了Brax在并行模擬越來(lái)越多的環(huán)境時(shí),可以產(chǎn)生多少次物理步驟(也即對(duì)環(huán)境狀態(tài)的更新)。
測(cè)試結(jié)果中的TPUv3 8×8曲線顯示,Brax可以在多個(gè)設(shè)備之間進(jìn)行無(wú)縫擴(kuò)展,每秒可達(dá)到數(shù)億個(gè)物理步驟:
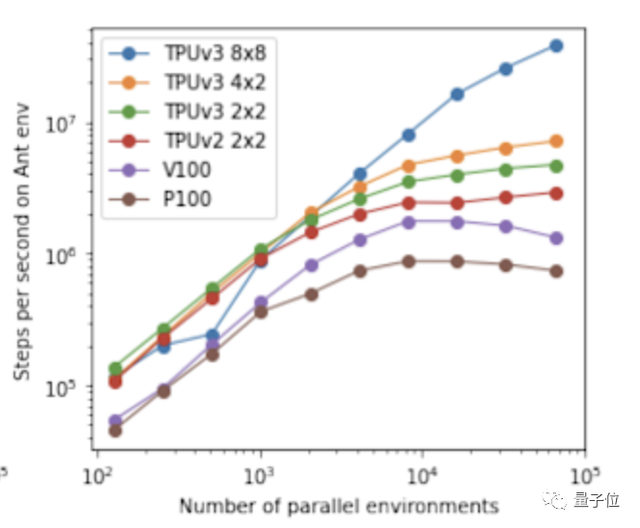
而不僅是在TPU上,從V100和P100曲線也能看出,Brax在高端GPU上同樣表現(xiàn)出色。
然后就是Brax在單個(gè)工作站(workstation)上運(yùn)行一個(gè)強(qiáng)化學(xué)習(xí)實(shí)驗(yàn)所需要的時(shí)間。
在這里,研究人員將基于Ant基準(zhǔn)環(huán)境訓(xùn)練的Brax引擎與MuJoCo物理引擎做了對(duì)比:
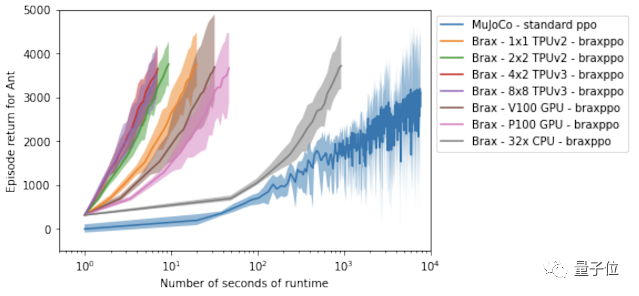
可以看到,相對(duì)于MuJoCo(藍(lán)線)所需的將近3小時(shí)時(shí)間,使用了Brax的加速器硬件最快只需要10秒。
使用Brax,不僅能夠提高單核訓(xùn)練的效率,還可以擴(kuò)展到大規(guī)模的并行模擬訓(xùn)練。
論文地址:
https://arxiv.org/abs/2106.13281
下載:
https://github.com/google/brax
參考鏈接:
https://ai.googleblog.com/2021/07/speeding-up-reinforcement-learning-with.html

計(jì)-67-150x150.png)

