
稚暉君預(yù)告揭曉!智元機(jī)器人發(fā)布首個(gè)通用具身基座模型GO-1
預(yù)告明天還有驚喜
剛填完坑就又埋下“驚喜預(yù)告”??
預(yù)告多日之后,稚暉君正式官宣首個(gè)通用具身基座模型——智元啟元大模型(Genie Operator-1,以下簡稱GO-1),將具身智能邁向通用全能的門檻進(jìn)一步降低了。
而且劇透明天還有驚喜。

概括而言,此次發(fā)布的GO-1大模型主要有以下幾個(gè)特點(diǎn):
- 人類視頻學(xué)習(xí):可以結(jié)合互聯(lián)網(wǎng)視頻和真實(shí)人類示范進(jìn)行學(xué)習(xí),增強(qiáng)模型對人類行為的理解;
- 小樣本快速泛化:能夠在極少數(shù)據(jù)甚至零樣本下泛化到新場景、新任務(wù),使得后訓(xùn)練成本非常低;
- 一腦多形:能夠在不同機(jī)器人形態(tài)之間遷移,快速適配到不同本體;
- 持續(xù)進(jìn)化:搭配智元一整套數(shù)據(jù)回流系統(tǒng),可以從實(shí)際執(zhí)行遇到的問題數(shù)據(jù)中持續(xù)進(jìn)化學(xué)習(xí)。
網(wǎng)友們也紛紛表示,通用機(jī)器人指日可待了!


首個(gè)通用具身基座模型GO-1
具體來看,GO-1大模型由智元機(jī)器人聯(lián)合上海AI Lab共同發(fā)布。
通過大規(guī)模、多樣化的數(shù)據(jù)訓(xùn)練,GO-1展現(xiàn)出強(qiáng)大的通用性和智能化能力,突破了大量以往具身智能面臨的瓶頸。
按照官方說法,GO-1除了拓展機(jī)器人的運(yùn)動(dòng)能力,更重要的是加強(qiáng)了其AI能力,從而大大增加了機(jī)器人的實(shí)用價(jià)值。
首先,通過學(xué)習(xí)人類操作視頻,機(jī)器人能快速學(xué)習(xí)新技能了。
比如下面這個(gè)倒水的動(dòng)作:

而且機(jī)器人還具備了一定的物體跟蹤能力,即使隨意移動(dòng)水杯位置,它也能精準(zhǔn)倒水。

與此同時(shí),機(jī)器人不止掌握已經(jīng)學(xué)過的操作,還能識別并操作未見過的物品(僅通過百條級數(shù)據(jù)就能實(shí)現(xiàn)快速泛化)。
比如倒完水之后,再烤烤面包并抹上果醬:

另外,當(dāng)前的具身模型通常針對單一機(jī)器人本體(Hardware Embodiment)進(jìn)行設(shè)計(jì),這導(dǎo)致兩個(gè)問題:
- 數(shù)據(jù)利用率低:不同機(jī)器人收集的數(shù)據(jù)難以共享,無法充分利用跨本體數(shù)據(jù)進(jìn)行訓(xùn)練;
- 部署受限:訓(xùn)練好的模型難以遷移到不同類型的機(jī)器人,每個(gè)本體往往需要獨(dú)立訓(xùn)練一個(gè)模型,增加適配成本。
而用上GO-1大模型之后,這些問題都被解決了。

可以看到,多個(gè)相同/不同本體的機(jī)器人能夠共同協(xié)作完成復(fù)雜任務(wù)。

此外,GO-1大模型還支持?jǐn)?shù)據(jù)飛輪持續(xù)提升。即在實(shí)際操作過程中不斷回流數(shù)據(jù)尤其是執(zhí)行出現(xiàn)問題的數(shù)據(jù),持續(xù)驅(qū)動(dòng)優(yōu)化模型性能。
比如下面這個(gè)例子中,機(jī)器人放咖啡杯時(shí)出現(xiàn)失誤,就可以通過數(shù)據(jù)回流(加上人工審核)針對性優(yōu)化。

對了,GO-1大模型也為機(jī)器人增加了新的語音交互方式,這極大便利了用戶在現(xiàn)實(shí)場景中自由表達(dá)需求。

基于全新ViLLA架構(gòu)
事實(shí)上,GO-1大模型的構(gòu)建核心圍繞對數(shù)據(jù)的充分利用展開。
基于具身領(lǐng)域的數(shù)字金字塔,GO-1大模型吸納了人類世界多種維度和類型的數(shù)據(jù):
- 底層:互聯(lián)網(wǎng)的大規(guī)模純文本與圖文數(shù)據(jù),可以幫助機(jī)器人理解通用知識和場景;
- 第2層:大規(guī)模人類操作/跨本體視頻,可以幫助機(jī)器人學(xué)習(xí)人類或者其他本體的動(dòng)作操作模式;
- 第3層:仿真數(shù)據(jù),用于增強(qiáng)泛化性,讓機(jī)器人適應(yīng)不同場景、物體等;
- 頂層:高質(zhì)量的真機(jī)示教數(shù)據(jù),用于訓(xùn)練精準(zhǔn)動(dòng)作執(zhí)行。

有了這些數(shù)據(jù),可以讓機(jī)器人在一開始就擁有通用的場景感知和語言能力,通用的動(dòng)作理解能力,以及精細(xì)的動(dòng)作執(zhí)行力。
當(dāng)然,過程中也少不了一個(gè)合適的數(shù)據(jù)處理架構(gòu)。
由于現(xiàn)有的VLA(Vision-Language-Action)架構(gòu)沒有利用到數(shù)字金字塔中大規(guī)模人類/跨本體操作視頻數(shù)據(jù),缺少了一個(gè)重要的數(shù)據(jù)來源,導(dǎo)致迭代的成本更高,進(jìn)化的速度更慢。
因此,智元團(tuán)隊(duì)創(chuàng)新性地提出了ViLLA(Vision-Language-Latent-Action)架構(gòu)。
與VLA架構(gòu)相比,ViLLA通過預(yù)測Latent Action Tokens(隱式動(dòng)作標(biāo)記),彌合圖像-文本輸入與機(jī)器人執(zhí)行動(dòng)作之間的鴻溝。它能有效利用高質(zhì)量的AgiBot World數(shù)據(jù)集以及互聯(lián)網(wǎng)大規(guī)模異構(gòu)視頻數(shù)據(jù),增強(qiáng)策略的泛化能力。
展開來說,ViLLA架構(gòu)是由VLM(多模態(tài)大模型)+MoE(混合專家)組成。
其中VLM借助海量互聯(lián)網(wǎng)圖文數(shù)據(jù)獲得通用場景感知和語言理解能力,MoE中的Latent Planner(隱式規(guī)劃器)借助大量跨本體和人類操作數(shù)據(jù)獲得通用的動(dòng)作理解能力,MoE中的Action Expert(動(dòng)作專家)借助百萬真機(jī)數(shù)據(jù)獲得精細(xì)的動(dòng)作執(zhí)行能力。
推理時(shí),VLM、Latent Planner和Action Expert三者協(xié)同工作:
- VLM采用InternVL-2B,接收多視角視覺圖片、力覺信號、語言輸入等多模態(tài)信息,進(jìn)行通用的場景感知和指令理解;
- Latent Planner是MoE中的一組專家,基于VLM的中間層輸出預(yù)測Latent Action Tokens作為CoP(Chain of Planning,規(guī)劃鏈),進(jìn)行通用的動(dòng)作理解和規(guī)劃;
- Action Expert是MoE中的另外一組專家,基于VLM的中間層輸出以及Latent Action Tokens,生成最終的精細(xì)動(dòng)作序列。
舉個(gè)例子,假如用戶給出機(jī)器人指令“掛衣服”,模型就可以根據(jù)看到的畫面,理解這句話對應(yīng)的任務(wù)要求。然后模型根據(jù)之前訓(xùn)練時(shí)看過的掛衣服數(shù)據(jù),設(shè)想這個(gè)過程應(yīng)該包括哪些操作步驟,最后執(zhí)行這一連串的步驟,完成整個(gè)任務(wù)的操作。

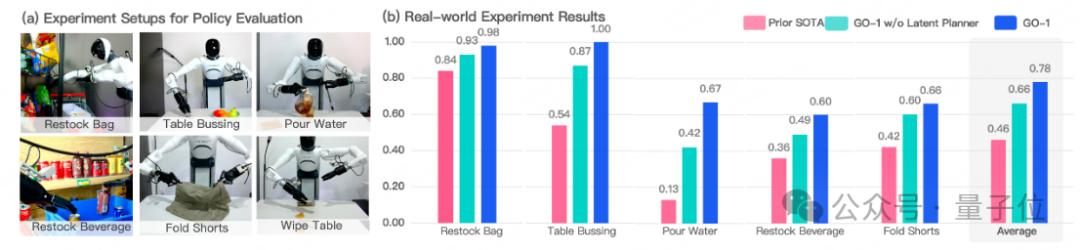
與此同時(shí),通過ViLLA架構(gòu),智元團(tuán)隊(duì)在五種不同復(fù)雜度任務(wù)上測試GO-1。
結(jié)果顯示,相比已有的最優(yōu)模型,GO-1成功率大幅領(lǐng)先,平均成功率提高了32%(46%->78%)。其中 “Pour Water”(倒水)、“Table Bussing”(清理桌面) 和 “Restock Beverage”(補(bǔ)充飲料) 任務(wù)表現(xiàn)尤為突出。
此外團(tuán)隊(duì)還單獨(dú)驗(yàn)證了ViLLA 架構(gòu)中Latent Planner的作用,可以看到增加Latent Planner可以提升12%的成功率(66%->78%)。
還有一個(gè)彩蛋
GO-1發(fā)布視頻的最后,相信大家也看到了一個(gè)彩蛋:

不知道內(nèi)容是否和稚暉君的最新預(yù)告有關(guān),明天我們繼續(xù)蹲蹲~
論文:
https://agibot-world.com/blog/agibot_go1.pdf
相關(guān)閱讀






全國第二!智平方榮獲第十三屆全國創(chuàng)新創(chuàng)業(yè)大賽初創(chuàng)型企業(yè)全國總決賽第二名(新一代信息技術(shù)賽道)
唯一獲獎(jiǎng)具身智能初創(chuàng)企業(yè)




