后生可畏!何愷明團隊新成果發(fā)布,共一清華姚班大二在讀
單步生成模型媲美多步擴散模型
henry 發(fā)自 凹非寺
量子位 | 公眾號
繼今年5月提出MeanFlow (MF) 之后,何愷明團隊于近日推出了最新的改進版本——
Improved MeanFlow (iMF),iMF成功解決了原始MF在訓練穩(wěn)定性、指導靈活性和架構效率上的三大核心問題。

其通過將訓練目標重新表述為更穩(wěn)定的瞬時速度損失,同時引入靈活的無分類器指導(CFG)和高效的上下文內條件作用,大幅提升了模型性能。
在ImageNet 256×256基準測試中,iMF-XL/2模型在 1-NFE(單步函數評估)中取得了1.72的FID成績,相較于原始MF提升了50%,證明了從頭開始訓練的單步生成模型可以達到與多步擴散模型相媲美的結果。

MeanFlow一作耿正陽依舊,值得注意的是共同一作的Yiyang Lu目前還是大二學生——來自清華姚班,而何愷明也在最后署了名。
其他合作者包括:Adobe研究員Zongze Wu、Eli Shechtman,及CMU機器學習系主任Zico Kolter。
重構預測函數,回到標準的回歸問題
iMF (Improved MeanFlow) 的核心改進是通過重構預測函數,將訓練過程轉換為一個標準的回歸問題。

在原始的MeanFlow (MF) (上圖左)中,其直接最小化平均速度的損失。其中,Utgt是根據MeanFlow恒等式和條件速度e-x推導出來的目標平均速度。
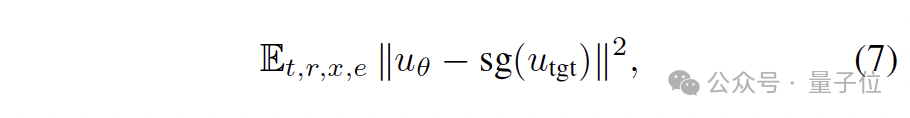
這里的問題在于,推導出來的目標Utgt包含網絡自身預測輸出的導數項,而這種“目標自依賴”的結構使得優(yōu)化極不穩(wěn)定、方差極大。
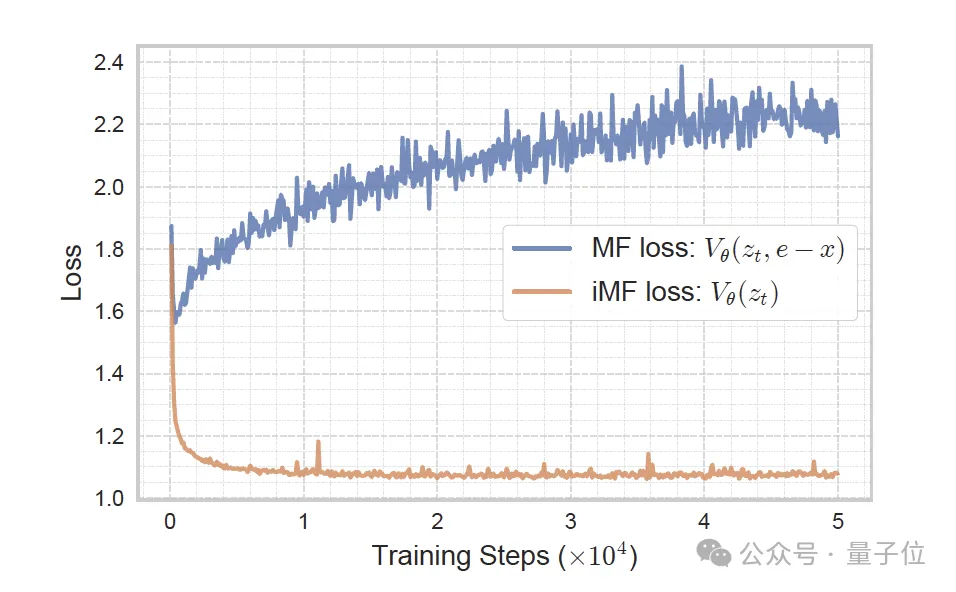
基于此,iMF從瞬時速度的角度去構建損失,使整個訓練就變得穩(wěn)定。
值得注意的是,網絡輸出仍然是平均速度,而訓練損失則變成了瞬時速度損失,以獲得穩(wěn)定的、標準的回歸訓練。
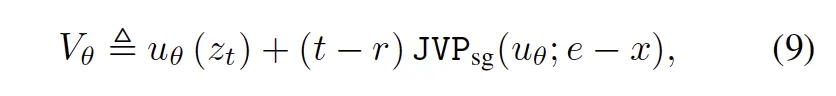
它首先將輸入簡化為單一的含噪數據z,并在內部巧妙地修改了預測函數的計算方式。
具體來說,iMF讓用于計算復合預測函數V(代表對瞬時速度的預測)中,雅可比向量積(JVP)項所需的切向量輸入不再是外部的e-x,而是由網絡自身預測的邊緣速度。
通過這一系列步驟,iMF成功移除了復合預測函數V對目標近似值e-x的依賴。此時,iMF再將損失函數的目標設定為穩(wěn)定的條件速度e-x。
最終,iMF 成功將訓練流程轉換成了一個穩(wěn)定的、標準的回歸問題,為平均速度的學習提供了堅實的優(yōu)化基礎。
除了對訓練目標進行改良外,iMF還通過以下兩大突破,全面提升了MeanFlow框架的實用性和效率:
靈活的無分類器指導(CFG)。
原始MeanFlow框架的一大局限是:為了支持單步生成,無分類器指導(CFG)的指導尺度在訓練時必須被固定,這極大地限制了在推理時通過調整尺度來優(yōu)化圖像質量或多樣性的能力。
iMF通過將指導尺度內化為一個可學習的條件來解決此問題。
具體來說,iMF直接將指導尺度作為一個輸入條件提供給網絡。
在訓練階段,模型會從一個偏向較小值的冪分布中隨機采樣不同的指導尺度。這種處理方式使得網絡能夠適應并學習不同指導強度下的平均速度場,從而在推理時解鎖了CFG的全部靈活性。
此外,iMF 還將這種靈活的條件作用擴展到支持CFG區(qū)間,進一步增強了模型對樣本多樣性的控制。
高效的上下文內條件作用(In-context Conditioning)架構
原始MF依賴于參數量巨大的adaLN-zero機制來處理多種異構條件(如時間步、類別標簽和指導尺度)。
當條件數量增多時,簡單地對所有條件嵌入進行求和并交給adaLN-zero處理,會變得效率低下且參數冗余。
iMF引入了改進的上下文內條件作用來解決此問題。
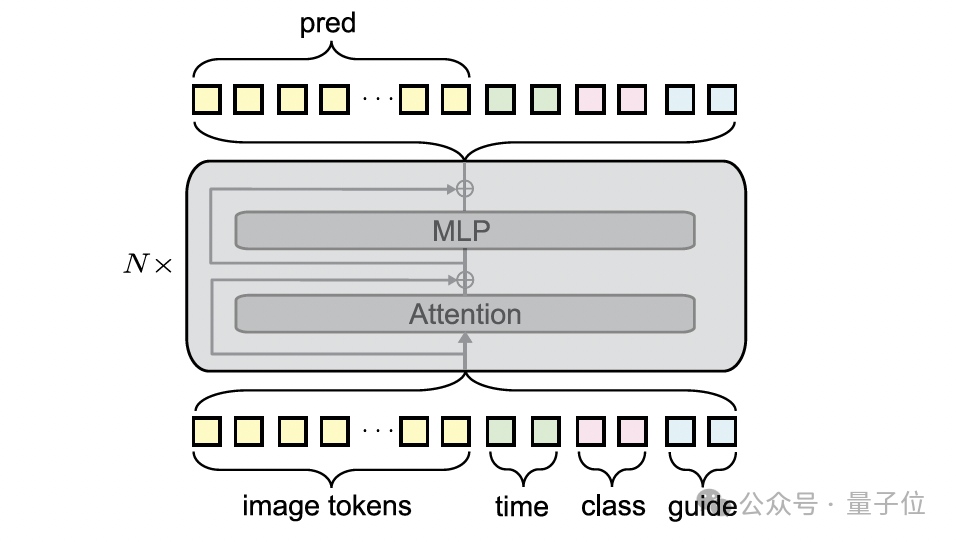
它的創(chuàng)新點在于:它將所有條件(包括時間步、類別以及 CFG 因子等)編碼成多個可學習的Token(而非單一向量),并將這些條件Token直接沿序列軸與圖像潛在空間的Token進行拼接,然后一起輸入到 Transformer 塊中進行聯(lián)合處理。
這一架構調整帶來的最大益處是:iMF可以徹底移除參數量巨大的adaLN-zero模塊。
這使得iMF在性能提升的同時,模型尺寸得到了大幅優(yōu)化,例如 iMF-Base 模型尺寸減小了約1/3(從 133M 降至 89M),極大地提升了模型的效率和設計靈活性。
實驗結果
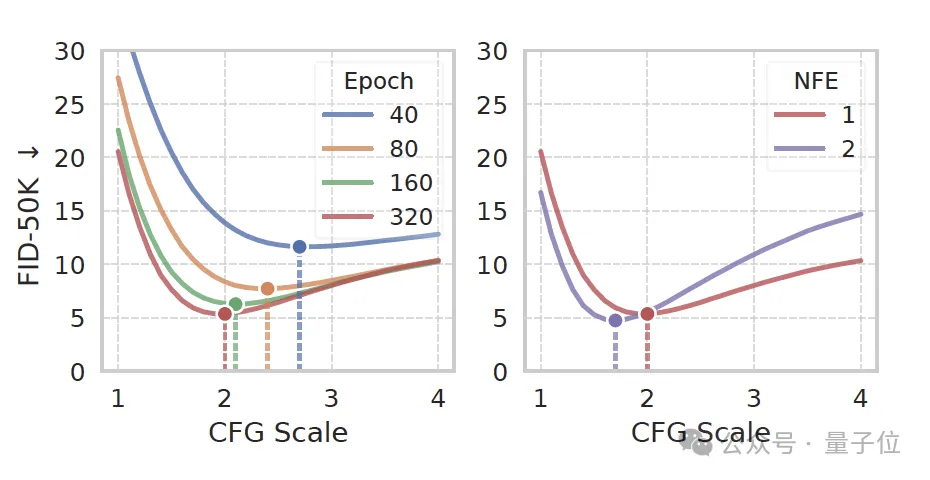
iMF在最具挑戰(zhàn)性的ImageNet 256×256上的1-NFE中展示了卓越的性能。
iMF-XL/2在1-NFE下的FID達到了1.72,將單步生成模型的性能推到了一個新的高度。

iMF從頭開始訓練的性能甚至優(yōu)于許多從預訓練多步模型中蒸餾而來的快進模型,證明了 iMF 框架在基礎訓練上的優(yōu)越性。
下圖在ImageNet 256×256上進行1-NFE(單步函數評估)生成的結果。

iMF在2-NFE時的FID達到1.54,將單步模型與多步擴散模型(FID約1.4-1.7)的差距進一步縮小。

One more thing
如前文所述,IMF 一作延續(xù)前作Mean Flow(已入選 NeurIPS 2025 Oral)的核心班底——耿正陽。
他本科畢業(yè)于四川大學,目前在CMU攻讀博士,師從Zico Kolter教授。

共一作者為清華姚班大二學生Yiyang Lu,現(xiàn)于MIT跟隨何愷明教授研究計算機視覺,此前曾在清華叉院許華哲教授指導下研究機器人方向。

這篇論文部分的內容由他們在MIT期間,于何愷明教授指導下完成。
此外,論文的其他作者還包括:Adobe研究員Zongze Wu、Eli Shechtman,CMU機器學習系主任J. Zico Kolter以及何愷明教授。
其中,Zongze Wu本科畢業(yè)于同濟大學,并在Hebrew University of Jerusalem獲得博士學位,他目前在Adobe舊金山研究院擔任研究科學家,

同樣的,Eli Shechtman也同樣來自Adobe,他是Adobe Research圖像實驗室的高級首席科學家。他于2007加入 Adobe,并于2007–2010年間在華盛頓大學擔任博士后研究員。

J. Zico Kolter是論文一作耿正陽的導師,他是CMU計算機科學學院教授,并擔任機器學習系主任。

論文的尾作則是著名的機器學習科學家何愷明教授,他目前是MIT的終身副教授。
他最出名的工作是ResNet,是21世紀被引用次數最多的論文。

就在最近的NeurIPS放榜中,何愷明參與的FastCNN還拿下了時間檢驗獎。
參考鏈接;
[1]https://arxiv.org/pdf/2505.13447
[2]https://gsunshine.github.io/
[3]https://arxiv.org/pdf/2512.02012
- 清華成立具身智能與機器人研究院2025-12-04
- DeepSeekV3.2技術報告還是老外看得細2025-12-04
- 爆發(fā)力超越波士頓動力液壓機器人,PHYBOT M1實現(xiàn)全球首次全尺寸重型電驅人形機器人完美擬人態(tài)后空翻2025-11-26
- DeepSeek再破谷歌OpenAI壟斷:開源IMO數學金牌大模型2025-11-28
相關閱讀