讓大模型學(xué)會(huì)“高維找茬”,中國(guó)聯(lián)通新研究解決長(zhǎng)文本圖像檢索痛點(diǎn)|AAAI 2026 Oral
通過巧妙地建模“語義層級(jí)”與“語義單調(diào)性”
允中 整理自 凹非寺
量子位 | 公眾號(hào) QbitAI
長(zhǎng)文本圖像檢索新SOTA來了!
描述得越詳細(xì),圖文匹配的分?jǐn)?shù)就應(yīng)該越高——這聽起來是常識(shí),但現(xiàn)有的CLIP模型卻做不到。
而就在最近,中國(guó)聯(lián)通數(shù)據(jù)科學(xué)與人工智能研究院團(tuán)隊(duì)在AAAI 2026 (Oral)上發(fā)表了一項(xiàng)最新成果,成功突破了這一局限。
研究名為HiMo-CLIP,通過巧妙地建模“語義層級(jí)”與“語義單調(diào)性”,在不改變編碼器結(jié)構(gòu)的前提下,讓模型自動(dòng)捕捉當(dāng)前語境下的“語義差異點(diǎn)”。
由此,成功解決了視覺-語言對(duì)齊中長(zhǎng)期被忽視的結(jié)構(gòu)化問題,在長(zhǎng)文本、組合性文本檢索上取得SOTA,同時(shí)兼顧短文本性能。
這一工作不僅提升了檢索精度,更讓多模態(tài)模型的對(duì)齊機(jī)制更加符合人類的認(rèn)知邏輯,為未來更復(fù)雜的多模態(tài)理解任務(wù)指明了方向。

痛點(diǎn):當(dāng)描述變長(zhǎng),CLIP卻“懵”了
在多模態(tài)檢索任務(wù)中,我們通常期望:文字描述越詳細(xì)、越完整,其與對(duì)應(yīng)圖像的匹配度(對(duì)齊分?jǐn)?shù))應(yīng)該越高。這被稱為“語義單調(diào)性”。
然而,現(xiàn)實(shí)很骨感。現(xiàn)有的模型(包括專門針對(duì)長(zhǎng)文本優(yōu)化的Long-CLIP等)往往將文本視為扁平的序列,忽略了語言內(nèi)在的層級(jí)結(jié)構(gòu)。
如下圖所示,對(duì)于同一張“白色福特F250皮卡”的圖片,當(dāng)文本從簡(jiǎn)短的“正面視圖…”擴(kuò)展到包含“超大輪胎”、“車軸可見”、“有色車窗”等詳細(xì)描述的長(zhǎng)文本時(shí),許多SOTA模型的對(duì)齊分?jǐn)?shù)反而下降了。
這種現(xiàn)象表明,模型未能有效處理長(zhǎng)文本中的“語義層級(jí)”,導(dǎo)致細(xì)節(jié)信息淹沒了核心語義,或者無法在復(fù)雜的上下文中捕捉到最具區(qū)分度的特征。

△圖1 隨著描述變長(zhǎng),現(xiàn)有模型分?jǐn)?shù)下降,而HiMo-CLIP(綠勾)穩(wěn)步提升
方法:HiMo-CLIP框架
為了解決上述問題,研究團(tuán)隊(duì)提出了一種即插即用的表征級(jí)框架HiMo-CLIP。
它包含兩個(gè)核心組件:層級(jí)分解模塊(Hierarchical Decomposition,HiDe)和單調(diào)性感知對(duì)比損失(Monotonicity-aware Contrastive Loss,MoLo)。
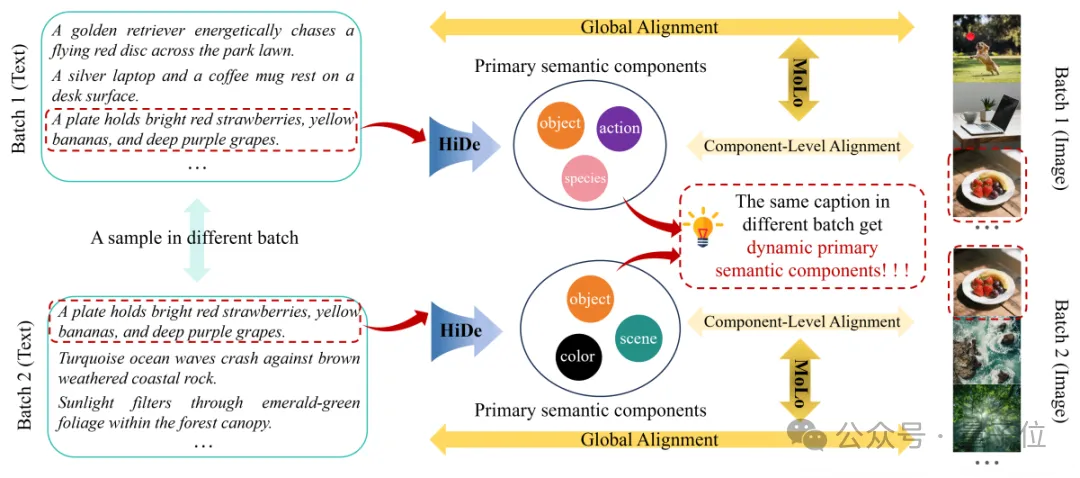
△圖2. HiMo-CLIP框架概覽
(1)HiDe模塊利用Batch內(nèi)的PCA動(dòng)態(tài)提取語義成分;(2)MoLo損失函數(shù)強(qiáng)制模型同時(shí)對(duì)齊“全量文本”和“語義成分”,實(shí)現(xiàn)單調(diào)性約束。
HiDe:誰是重點(diǎn)?由“鄰居”決定
在真實(shí)場(chǎng)景中,數(shù)據(jù)樣本往往是高度復(fù)雜的。
如上圖2所示,我們面對(duì)的不是簡(jiǎn)單的“紅蘋果”和“青蘋果”,而是像“一只金毛獵犬在公園草坪上追趕紅盤”、“盤子里放著鮮紅的草莓、黃香蕉和深紫色的葡萄”這樣高度復(fù)雜的場(chǎng)景。傳統(tǒng)的固定分詞法在這種復(fù)雜度下根本抓不住重點(diǎn)。
HiMo-CLIP換了個(gè)思路,它像一個(gè)玩“大家來找茬”的高手:通過觀察Batch內(nèi)的“鄰居”,動(dòng)態(tài)提取最具區(qū)分度的特征。
- 長(zhǎng)文本特征f1:代表“整句話”的意思。
- 動(dòng)態(tài)子語義f2:代表“這句話里最獨(dú)特的記憶點(diǎn)”。舉個(gè)栗子:假設(shè)長(zhǎng)文本是:“一只戴著墨鏡的柯基在沙灘上奔跑”。
- 場(chǎng)景A(混在風(fēng)景照里):如果這一批次(Batch)的其他圖片都是“沙灘排球”、“海邊游艇”。PCA一分析,發(fā)現(xiàn)“沙灘”大家都有,不稀奇。唯獨(dú)“柯基”是獨(dú)一份。→此時(shí),f2自動(dòng)代表“柯基(物體)”。
- 場(chǎng)景B(混在狗群里):如果這一批次的其他圖片都是“草地上的柯基”、“沙發(fā)上的柯基”。PCA一分析,發(fā)現(xiàn)“柯基”遍地都是,也沒法區(qū)分。唯獨(dú)“戴墨鏡”和“在沙灘”是特例。→此時(shí),f2自動(dòng)代表“戴墨鏡/沙灘(屬性/環(huán)境)”。
這就是HiDe最聰明的地方:它不需要人教它什么是重點(diǎn),而是利用統(tǒng)計(jì)學(xué)原理,自適應(yīng)地提取出那個(gè)最具辨識(shí)度的“特征指紋”,自動(dòng)構(gòu)建語義層級(jí)。
MoLo:既要顧全大局,又要抓住細(xì)節(jié)
找到了重點(diǎn)f2,怎么用呢?作者設(shè)計(jì)了MoLo,強(qiáng)制模型“兩手抓”:
MoLo=InfoNCE(f1, feat)+λ*InfoNCE(f2, feat)
- 第一手:InfoNCE(f1, feat)是傳統(tǒng)的圖文匹配,保證圖片和“整句話”(f1)對(duì)齊。
- 第二手:InfoNCE(f2, feat)強(qiáng)制圖片特征還要特別像那個(gè)提取出來的“獨(dú)特記憶點(diǎn)”(f2)。
這個(gè)操作看似簡(jiǎn)單,實(shí)則一石三鳥:
- 自動(dòng)摘要:f2就是特征空間里的“高維短文本”,省去了人工構(gòu)造短文本的偏差。
- 更懂機(jī)器的邏輯:人類定義的關(guān)鍵詞(如名詞)未必是模型分類的最佳依據(jù)(可能是紋理或形狀)。PCA完全在特征空間操作,提取的是機(jī)器認(rèn)為的差異點(diǎn),消除了人類語言和機(jī)器理解之間的隔閡(Gap)。
- 數(shù)據(jù)效率高:你只需要喂給模型長(zhǎng)文本,它在訓(xùn)練中順便學(xué)會(huì)了如何拆解長(zhǎng)句、提取關(guān)鍵詞。訓(xùn)練的是長(zhǎng)文本,卻白撿了短文本的匹配能力。
實(shí)驗(yàn):長(zhǎng)短通吃,全面SOTA
研究團(tuán)隊(duì)在多個(gè)經(jīng)典的長(zhǎng)文本、短文本檢索基準(zhǔn),以及自行構(gòu)造的深度層級(jí)數(shù)據(jù)集HiMo-Docci上進(jìn)行了廣泛實(shí)驗(yàn)。
在長(zhǎng)文本(表1)和短文本(表2)檢索任務(wù)上,HiMo-CLIP展現(xiàn)出了顯著的優(yōu)勢(shì)。值得注意的是,HiMo-CLIP僅使用了1M(一百萬)的訓(xùn)練數(shù)據(jù),就擊敗了使用100M甚至10B數(shù)據(jù)的方法(如LoTLIP,SigLIP等)。

△表1 長(zhǎng)文本檢索結(jié)果

△表2 短文本檢索結(jié)果
為了充分評(píng)估長(zhǎng)文本的對(duì)齊效果,研究團(tuán)隊(duì)構(gòu)建了HiMo-Docci數(shù)據(jù)集,同時(shí)還提出了HiMo@K指標(biāo),以量化模型是否真的“讀懂”了層級(jí)。結(jié)果顯示,HiMo-CLIP保持了極高的單調(diào)性相關(guān)系數(shù)(0.88),遠(yuǎn)超對(duì)比方法。

△HiMo-Docci上的單調(diào)性可視化
隨著文本描述逐漸完整(1→5),HiMo-CLIP的分?jǐn)?shù)(紅線)呈現(xiàn)出完美的上升趨勢(shì),而其他模型的分?jǐn)?shù)則波動(dòng)劇烈,甚至下降。
進(jìn)一步的,為了探究各個(gè)組件對(duì)性能的具體貢獻(xiàn),研究團(tuán)隊(duì)進(jìn)行了詳盡的消融實(shí)驗(yàn),揭示了HiDe與MoLo協(xié)同工作的內(nèi)在機(jī)理。
感興趣的朋友可到原文了解更多細(xì)節(jié)~
論文鏈接:https://arxiv.org/abs/2511.06653
開源地址:https://github.com/UnicomAI/HiMo-CLIP
相關(guān)閱讀


小冰李笛:真正的AI信仰者不該FOMO | MEET 2025
AI天生注定是為私域服務(wù)的

大模型中的「羅翔老師」!北大團(tuán)隊(duì)搞出ChatLaw,發(fā)布即登頂熱榜
和ChatExcel團(tuán)隊(duì)師出同門



什么會(huì)影響大模型安全?NeurIPS'24新研究提出大模型越獄攻擊新基準(zhǔn)與評(píng)估體系
不僅專注于攻擊,還深入探討了越獄評(píng)估