階躍開源4B Agent模型,跑通所有安卓設備,手搓黨一鍵部署
告別GUI Agent工程基建噩夢
GELab-Zero團隊 投稿
量子位 | 公眾號 QbitAI
首次將GUI Agent模型與完整配套基建同步開放,支持手搓黨一鍵部署!
這就是階躍星辰剛剛開源的GELab-Zero。
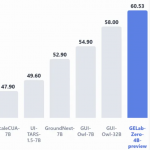
其中4B版本的GUI Agent模型在手機端、電腦端等多個GUI榜單上全面刷新同尺寸模型性能紀錄,取得SOTA成績。
隨著AI在手機等消費終端的普及,Mobile Agent正從“能不能用”邁向“能否規模化落地”。
GUI Agent是執行能力最強的形態之一。它基于視覺理解即可適配幾乎所有App,無需廠商額外改造,接入成本極低。
此外,階躍還同步開源了基于真實業務場景的自建評測標準AndroidDaily,以期推動GUI領域模型評測向消費級、規模化應用發展。
同尺寸性能 SOTA,端到端、輕量化、速度快
要知道,讓GUI Agent在不同品牌與系統版本的設備上順暢運行并不輕松。
移動生態的高度碎片化讓開發者需處理多設備ADB連接、依賴安裝、權限配置、推理服務部署、任務編排與回放等繁瑣流程,工程成本高昂,精力難以聚焦在策略創新與體驗設計上。
要推動移動端Agent真正規模化,必須首先降低開發與使用門檻,讓開發者專注于創造價值,而非重復搭建底層設施。
基于此,階躍開源了GELab-Zero。
它主要包含三部分:
- 一個能在本地運行的GUI Agent模型GELab-Zero-4B-preview
- 即插即用的完整推理工程基建,解決所有臟活累活
- 基于真實業務場景的自建評測標準AndroidDaily
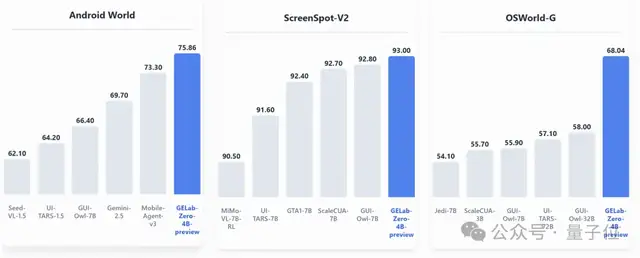
研究團隊在ScreenSpot、OSWorld、MMBench、Android World多個開源基準測試上對GELab-Zero-4B-preview模型進行了全面評估。
這些基準測試涵蓋了GUI理解、定位、交互等多個維度。
從測試結果可以看出,GELab-Zero-4B-preview在多項開源基準測試中超越其他主流模型,拿下同尺寸SOTA。
值得一提的是,GELab-Zero-4B-preview的表現還超越了參數量更大的GUI-Owl-32B等模型,性能更優,也更易部署。

來看一下研究團隊給出的示例場景。
復雜任務
場景1:在外賣平臺同時采購跨品類、不同規格和數量的商品。
Prompt:去餓了么離我最近的盒馬鮮生購買:紅顏草莓300g、秘魯比安卡藍莓125g(果徑18mm)、當季新鮮黃心土豆500g、粉糯貝貝南瓜750g、盒馬大顆粒蝦滑、2瓶盒馬純黑豆豆漿300ml、小王子夏威夷果可可脆120g、盒馬菠菜面、盒馬五香牛肉、5袋好歡螺柳州螺獅粉(加辣加臭)400g、m&m’s牛奶巧克力豆100g
可以看到,模型精準識別了物品信息,并順暢地完成了多步驟、重復性的購買操作。
場景2:在企業福利APP中領取餐券。
Prompt:打開給到App,在我的,下滑尋找,員工權益-奮斗食代,幫我領劵。
上述示例展示了GELab-Zero-4B-preview執行的能力和范圍具有很強的泛化性,無論在國民級APP還是小眾產品平臺,都可以順利完成任務。
模糊指令
場景1:在某個視頻平臺上播放指定演員的經典作品。
Prompt:在騰訊視頻上找一部成龍的經典動作片播放。
接到指令后,GELab-Zero-4B-preview自主拆解“經典”這一需求,確定執行標準。
過程中,模型先打開騰訊視頻,識別并關閉了彈窗,搜索“成龍”后在電影類目中選擇了頁面上成龍評分最高的代表作播放。
場景2:找一個周末能帶孩子玩的地方。
Prompt:幫我找個周末能帶孩子去玩的地方。
接到指令后,模型首先在內容平臺搜索“北京周末帶娃”,然后自主判斷衡量標準后為用戶推薦北京園博園“頑酷奇遇”,并為用戶提煉出該地點的亮點——“有巨型裝置卡通,親子活動豐富”。
可以看到,GELab-Zero-4B-preview模型能夠很好地執行復雜任務和模糊指令,不僅可以準確、流暢地執行涉及到多步驟、多主體、重復操作的任務,也能對“好看”“適合玩的”“經典”等偏籠統和主觀性的指令進行自主拆解,確定執行路徑和標準。
GUI+基建=GUI Agent MCP,一鍵拉起部署
針對GUI智能體,研究人員構建了一整套完整的技術架構體系,可以一鍵拉起獲得類似開源GUI Agent MCP的體驗。
具體能力如下:
- 輕量級本地推理
- 支持4B模型在消費級硬件上運行,兼顧低延遲與隱私。
- 一鍵任務啟動
- 提供統一部署流水線,自動處理環境依賴和設備管理。
- 多設備任務分發
- 可以分發到多臺手機并記錄交互軌跡,實現可觀測、可復現。
- 多種Agent模式
- 涵蓋ReAct閉環、多智能體協作以及定時任務等多種工作模式。

這些能力讓GELab-Zero能夠靈活應對真實場景的復雜任務流,并為后續擴展提供扎實底座。
Agent開發者可基于這套基建快速測試新想法、驗證交互策略;企業級用戶則能直接復用這套基建,將MCP能力快速植入到產品業務中。
自建并開源貼合真實業務場景的評測基準
此外,研究團隊基于手機、IoT、汽車等行業頭部公司的真實合作案例,建立了高度貼合業務場景的評測基準。
當前的主流基準測試,大部分聚焦于生產力類應用(如郵件與文檔處理)。
然而在日常真實場景中,用戶高頻依賴的卻是生活服務類應用,如外賣、打車、社交、支付等,而這部分場景不僅覆蓋面更廣,也更能體現當下GUI Agent 的實用價值。
為此研究者提出 AndroidDaily,一個面向真實世界、動態演進的多維基準體系。
它聚焦在現代生活六大核心維度:飲食、出行、購物、居住、信息消費、娛樂,并優先選擇在這些類別中具有代表性(高頻使用、應用商店日活排名靠前)的主流應用進行測試,高度還原真實任務執行流程(包括詢問用戶更多信息補充輸入、高危操作請求用戶接管)。
評測結果顯示,GELab-Zero-4B-preview在AndroidDaily測試中準確率達到73.4% ,在移動端復雜任務中表現優秀。
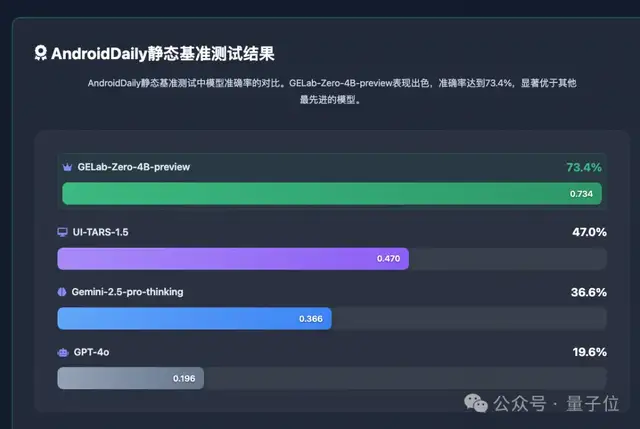
為了平衡評估的全面性和執行效率,AndroidDaily采用了靜態評測和端到端評測雙軌評估體系。
靜態評測考察模型的grounding(界面理解、元素識別)和action規劃能力,用于檢驗其在推理與執行一致性等基礎層面的表現。
端到端測試重點衡量GUI Agent在真實環境中處理復雜任務時的執行效果與穩定性。
其中,靜態測試包含3146個actions,提供任務描述和逐步的屏幕截圖,要求Agent預測每一步的動作類型和動作值(如點擊坐標、輸入文本),主要評估數值準確率。
這種方法無需復雜的工程基礎設施,可以快速、低成本地進行大規模模型迭代和測試。
而端到端測試包含235個任務,典型任務場景包括出行交通(打車、導航、公共交通等)、購物消費(電商購物、支付、訂單管理等)、社交通訊(消息發送、社交互動等)、內容消費(新聞閱讀、視頻觀看、內容收藏等)、本地服務(外賣、到店服務)等。
在完全功能化的測試環境(如真實設備或模擬器)中進行,Agent需要從頭到尾自主執行任務,最終以整體任務成功率作為評價指標,能真實反映智能體在復雜環境中的綜合能力。

團隊表示,希望通過GELab-Zero的開源,進一步降低移動端Agent的開發門檻,讓更多開發者能夠快速構建和驗證自己的想法。
未來,研究團隊將始終堅持開放、可控、隱私優先的原則,持續優化模型性能、擴展跨平臺支持、豐富生態工具鏈。
GitHub:
https://github.com/stepfun-ai/gelab-zero
抱抱臉:
https://huggingface.co/stepfun-ai/GELab-Zero-4B-preview
- DeepSeek-V3.2系列開源,性能直接對標Gemini-3.0-Pro2025-12-01
- 誤入人均10個頂級offer的技術天團活動,頂尖AI人才的選擇邏輯我悟了2025-12-04
- 字節“豆包手機”剛開賣,吉利系進展也曝光了:首月速成200人團隊,挖遍華為小米榮耀2025-12-01
- 居然有21%的ICLR 2026評審純用AI生成…2025-11-30