混元OCR模型核心技術(shù)揭秘:統(tǒng)一框架、真端到端
,模型采用原生ViT和輕量LLM結(jié)合的架構(gòu)
HunyuanOCR模型團隊 投稿
量子位 | 公眾號 QbitAI
騰訊混元大模型團隊正式發(fā)布并開源HunyuanOCR模型!
這是一款商業(yè)級、開源且輕量(1B參數(shù))
的OCR專用視覺語言模型,模型采用原生ViT和輕量LLM結(jié)合的架構(gòu)。

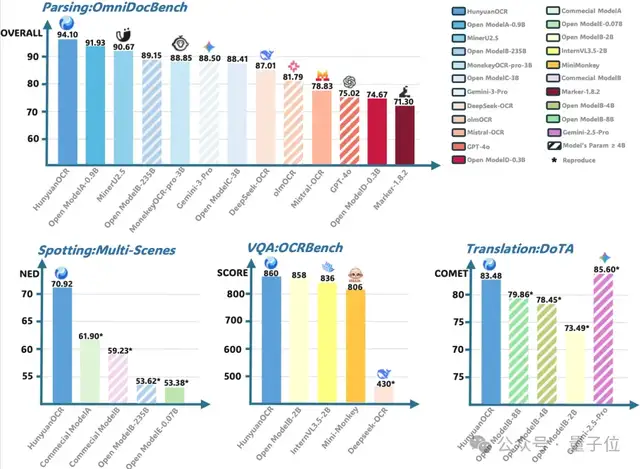
具體而言,其感知能力(文本檢測和識別、復(fù)雜文檔解析)優(yōu)于所有公開方案;語義能力(信息抽取、文字圖像翻譯)表現(xiàn)出色,榮獲ICDAR 2025 DIMT挑戰(zhàn)賽(小模型賽道)冠軍,并在OCRBench上取得3B以下模型SOTA成績。
目前,該模型在抱抱臉(Hugging Face)趨勢榜排名前四,GitHub標星超過700,并在Day 0被vllm官方團隊接入。
團隊介紹,混元OCR專家模型實現(xiàn)了三大突破:
(1)全能與高效統(tǒng)一。
在輕量框架下支持文字檢測和識別、復(fù)雜文檔解析、開放字段信息抽取、視覺問答和拍照圖像翻譯,解決了傳統(tǒng)專家模型功能單一和通用視覺理解大模型效率低下的痛點。
(2)極簡端到端架構(gòu)。
摒棄版面分析等前處理依賴,徹底解決流水線錯誤累積問題,大幅簡化部署。
(3)數(shù)據(jù)驅(qū)動與RL創(chuàng)新。
驗證了高質(zhì)量數(shù)據(jù)價值,并證明強化學(xué)習(xí)可顯著提升多項OCR任務(wù)性能。
目前模型參數(shù)已在抱抱臉和ModelScope等渠道開源,并提供基于vLLM的高性能部署方案,旨在助力科研與工業(yè)落地。
HunyuanOCR核心技術(shù)大揭秘
作為一款具備商業(yè)級性能的開源多語言VLM,混元OCR專家模型的核心動機在于構(gòu)建一個真正統(tǒng)一、高效的端到端OCR基礎(chǔ)模型。
其核心技術(shù)主要聚焦于以下幾個方面:
輕量化模型結(jié)構(gòu)設(shè)計、高質(zhì)量預(yù)訓(xùn)練數(shù)據(jù)生產(chǎn)、重應(yīng)用導(dǎo)向的預(yù)訓(xùn)練策略和OCR任務(wù)定制的強化學(xué)習(xí)。
輕量化模型結(jié)構(gòu)設(shè)計
下圖為HunyuanOCR架構(gòu)示意圖。
不同于其他開源的級聯(lián)OCR方案或?qū)<夷P停煸狾CR模型貫徹端到端訓(xùn)推一體范式,各項任務(wù)僅需單次推理即可獲取完整效果。
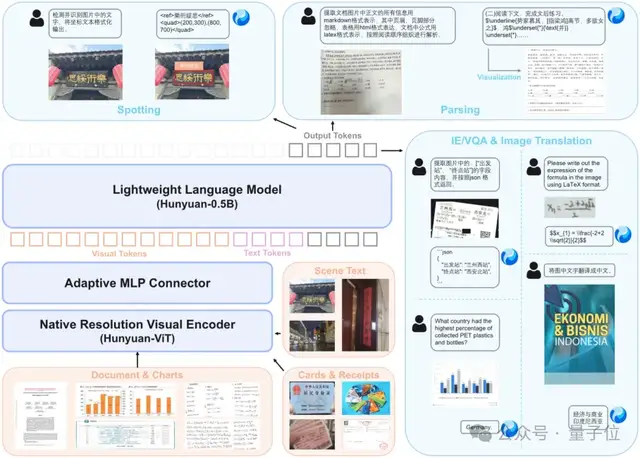
HunyuanOCR采用由原生分辨率視覺編碼器、自適應(yīng)MLP連接器和輕量級語言模型構(gòu)成的協(xié)同架構(gòu)。
視覺部分基于SigLIP-v2-400M,引入自適應(yīng)Patching機制支持任意分辨率輸入,有效避免了長文檔等極端長寬比場景下的圖像失真與細節(jié)丟失。
連接器通過可學(xué)習(xí)的池化操作充當(dāng)橋梁,在自適應(yīng)壓縮高分辨率特征的同時,精準保留了文本密集區(qū)的關(guān)鍵語義。
語言模型側(cè)則基于Hunyuan-0.5B,通過引入創(chuàng)新的XD-RoPE技術(shù),將一維文本、二維版面(高寬)及三維時空信息進行解耦與對齊,賦予了模型處理多欄排版及跨頁邏輯推理的強大能力。
與依賴多模型級聯(lián)或后處理的傳統(tǒng)方案不同,HunyuanOCR采用了純粹的端到端訓(xùn)練與推理范式。
該模型通過大規(guī)模高質(zhì)量的應(yīng)用導(dǎo)向數(shù)據(jù)進行驅(qū)動,并結(jié)合強化學(xué)習(xí)策略進行優(yōu)化,實現(xiàn)了從圖像到文本的直接映射。這種設(shè)計徹底消除了傳統(tǒng)架構(gòu)中常見的“錯誤累積”問題,并擺脫了對復(fù)雜后處理模塊的依賴,從而在混合版面理解等高難度場景中展現(xiàn)出遠超同類模型的魯棒性與穩(wěn)定性。
高質(zhì)量預(yù)訓(xùn)練數(shù)據(jù)生產(chǎn)
為了系統(tǒng)性提升HunyuanOCR在多語言、多場景及復(fù)雜版面下的感知與理解能力,研究團隊構(gòu)建了一個包含超2億“圖像-文本對”的大規(guī)模高質(zhì)量多模態(tài)訓(xùn)練語料庫。
通過整合公開基準、網(wǎng)絡(luò)爬取真實數(shù)據(jù)及自研工具生成的合成數(shù)據(jù),該數(shù)據(jù)庫覆蓋了9大核心真實場景(包括文檔、街景、廣告、手寫體、截屏、票據(jù)卡證、游戲界面、視頻幀及藝術(shù)字體)以及超過130種語言的OCR數(shù)據(jù)。
這套完整的數(shù)據(jù)生產(chǎn)與清洗流水線,為模型提供了堅實的高質(zhì)量多模態(tài)訓(xùn)練資源,具體揭示如下:

(注:圖為高質(zhì)量預(yù)訓(xùn)練數(shù)據(jù),(a)(b)(c)展示了數(shù)據(jù)合成和仿真增強的效果,(d)(e)展示自動化QA數(shù)據(jù)生產(chǎn)的案例)
在數(shù)據(jù)合成方面,研究人員基于SynthDog框架進行了深度擴展,實現(xiàn)了對130多種語言的段落級長文檔渲染及雙向文本(從左到右和從右到左兩種閱讀順序)支持,并能精細控制字體、顏色、混合排版及手寫風(fēng)格,有效提升了跨語言泛化能力。
同時,引入自研的Warping變形合成流水線,通過模擬幾何變形(折疊、透視)、成像退化(模糊、噪聲)及復(fù)雜光照干擾,逼真還原自然場景下的拍攝缺陷。
這種“合成+仿真”的策略顯著增強了模型在文本定位、文檔解析等任務(wù)中的魯棒性。
針對高階語義理解任務(wù),團隊開發(fā)了一套集“難例挖掘、指令式QA生成與一致性校驗”于一體的自動化流水線。
遵循“一源多用”原則,該流水線實現(xiàn)了對同一圖像進行文本定位、結(jié)構(gòu)化解析(Markdown/JSON)及多維推理問答(信息抽取、摘要、計算)的統(tǒng)一標注。系統(tǒng)優(yōu)先挖掘低清晰度或含復(fù)雜圖表的難例,利用高性能VLM生成多樣化問答對,并通過多模型交叉驗證機制確保數(shù)據(jù)質(zhì)量。
這一流程有效解決了復(fù)雜場景下高質(zhì)量VLM訓(xùn)練數(shù)據(jù)稀缺的問題,大幅提升了模型的數(shù)據(jù)利用效率。
重應(yīng)用導(dǎo)向的預(yù)訓(xùn)練策略
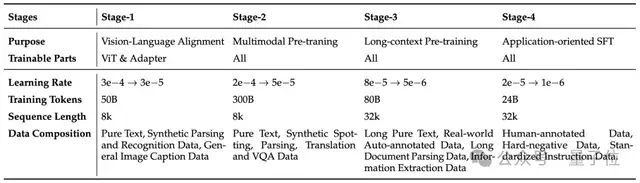
HunyuanOCR采用循序漸進的四階段預(yù)訓(xùn)練策略:
前兩階段聚焦視覺&語言對齊與通用理解能力構(gòu)建。
其中Stage-1為熱身階段,凍結(jié)LLM并僅訓(xùn)練ViT與MLP適配器,通過Caption和OCR數(shù)據(jù)實現(xiàn)視覺特征與文本語義空間的對齊,強化基礎(chǔ)感知與結(jié)構(gòu)化理解。
Stage-2解凍所有參數(shù)進行端到端學(xué)習(xí),依托約300Btoken數(shù)據(jù)及涵蓋文檔解析、文字檢測和識別、圖片翻譯、VQA的多任務(wù)合成樣本,深度增強模型對文檔、表格、公式、圖表等復(fù)雜結(jié)構(gòu)化內(nèi)容的感知和理解能力。
后兩階段則側(cè)重長文檔處理能力與實際應(yīng)用場景適配。
Stage-3將上下文窗口擴展至32k,通過長窗口數(shù)據(jù)訓(xùn)練滿足長文檔圖像解析與理解需求。
Stage-4開展應(yīng)用導(dǎo)向的退火訓(xùn)練,結(jié)合精心篩選的人工標注真值數(shù)據(jù)與高質(zhì)量合成數(shù)據(jù),通過統(tǒng)一指令模版與標準化輸出格式規(guī)范模型響應(yīng)模式,既提升了復(fù)雜場景下的魯棒性,也為后續(xù)強化學(xué)習(xí)階段奠定了堅實基礎(chǔ)。
下面的表格展示了混元OCR模型四階段預(yù)訓(xùn)練:
OCR任務(wù)定制的強化學(xué)習(xí)方案
盡管強化學(xué)習(xí)已在大型推理模型中取得顯著成功,Hunyuan視覺團隊創(chuàng)新性地將其應(yīng)用于注重效率的輕量級OCR專家模型。
針對OCR任務(wù)結(jié)構(gòu)化強且易于驗證的特點,采取了混合策略:
對于文字檢測識別和文檔解析等具有封閉解的任務(wù),采用基于可驗證獎勵的強化學(xué)習(xí)。
而對于翻譯和VQA等開放式任務(wù),則設(shè)計了基于LLM-as-a-judge的獎勵機制。這種結(jié)合證明了輕量級模型也能通過RL獲得顯著性能躍升,為邊緣側(cè)和移動端的高性能應(yīng)用開辟了新路徑。

以下是三個主要注意事項:
第一,嚴苛的數(shù)據(jù)篩選。
數(shù)據(jù)構(gòu)建嚴格遵循質(zhì)量、多樣性與難度平衡原則,利用LLM過濾低質(zhì)數(shù)據(jù),并剔除過于簡單或無法求解的樣本以保持訓(xùn)練的有效性。
第二,自適應(yīng)獎勵設(shè)計。
文字檢測和識別任務(wù)上,綜合考慮IoU與編輯距離。
復(fù)雜文檔解析任務(wù)聚焦于結(jié)構(gòu)與內(nèi)容的準確性;VQA采用基于語義匹配的二值獎勵;而文本圖像翻譯則引入經(jīng)過去偏歸一化的軟獎勵(例如0~5的連續(xù)空間),特意擴展了中段分數(shù)的粒度,以便更敏銳地捕捉翻譯質(zhì)量的細微差異。
第三,GRPO算法與格式約束優(yōu)化。
訓(xùn)練階段采用群組相對策略優(yōu)化(GRPO)作為核心算法,為了確保訓(xùn)練的穩(wěn)定性,團隊引入了嚴格的長度約束與格式規(guī)范機制,任何超長或不符合預(yù)定義Schema(如結(jié)構(gòu)化解析格式)的輸出將直接被判為零獎勵。
這一強約束機制迫使模型專注于生成有效、規(guī)范且可驗證的輸出,從而在受限條件下習(xí)得精準的推理與格式化能力。
項目主頁:
https://hunyuan.tencent.com/vision/zh?tabIndex=0
Github:
GitHub-Tencent-Hunyuan/HunyuanOCR
抱抱臉:
https://huggingface.co/tencent/HunyuanOCR
論文:
https://arxiv.org/abs/2511.19575
- GPT-5-Thinking新訓(xùn)練方法公開:讓AI學(xué)會懺悔2025-12-04
- GPT5.5代號“蒜你狠”曝光!OpenAI拉響紅色警報加班趕制新模型,最快下周就發(fā)2025-12-03
- 華爾街尬捧TPU學(xué)術(shù)界懵了:何愷明5年前就是TPU編程高手,多新鮮2025-11-30
- 馬斯克悄然發(fā)布Grok 4.1,霸榜大模型競技場所有排行榜2025-11-18
相關(guān)閱讀


騰訊優(yōu)圖刷新國際權(quán)威比賽ICDAR OCR信息提取紀錄
從識別到內(nèi)容理解,優(yōu)圖OCR正在不斷突破技術(shù)邊界。