
大模型首次擁有“脖子”!紐大團隊實現360度類人視覺搜索
視覺空間推理從“脫離身體的被動范式”向“具身的主動范式”轉型
henry 發自 凹非寺
量子位 | 公眾號
終于有人要給大模型安“脖子”了!
在最新的論文Thinking in 360°: Humanoid Visual Search in the Wild中,來自紐約大學的研究團隊讓大模型能夠環顧四周,進行360度的全方位思考。

他們通過定義一套全新的數據集和基礎測試H*,讓模型可以在火車站、購物中心等真實環境中,進行像人類一樣的視覺搜索。
謝賽寧(也參與了這篇論文)在轉發中,直接表示:這不就是給模型安了個脖子嗎?
這是怎么回事?
類人視覺搜索
整體而言,研究團隊首先提出了一項在360度空間中實現人類主動空間推理的新任務——
類人視覺搜索(Humanoid Visual Search),這項任務能讓類人智能體在全景圖像構建的沉浸式環境中,通過自主旋轉頭部搜索目標物體或路徑。
為進一步評估智能體在視覺擁擠的真實場景中的搜索能力,研究團隊還構建了全新的針對性基準測試 ——H*Bench。
這一基準突破了傳統測試多聚焦簡單家庭場景的局限,涵蓋交通樞紐、大型零售場所、城市街道、公共機構等真實世界復雜環境,對智能體的高級視覺 -空間推理能力提出了更嚴苛的考驗。
該研究的推進,為視覺空間推理從 “脫離身體的被動范式” 向 “具身的主動范式” 轉型奠定了重要基礎。
接下來,我們具體來看。
在論文的開頭,研究提出了一個非常直覺的問題——如何開發出既能像人類一樣高效,又能繞過硬件限制在復雜現實場景中進行主動視覺搜索的具身智能體?
眾所周知,相比于腦袋、手腕、身體各處“長眼”的機器人,人類僅憑轉動脖子和眼睛,就能高效地搜索360°范圍內的視覺信息,從而完成視覺搜索任務(比如在地鐵站中尋找下一個出口)。

而現在的大模型,不但只能處理單張、靜態、低分辨率的圖像,而且在后續的操作中,也局限于將圖像放大、裁剪的計算操作。
這就意味著與生物視覺相比,大模型既無法改變初始視角以獲取視野以外的信息,同時也由于缺乏物理實體,不能移步換景,將視覺推理和物理行動結合起來。
基于此,研究提出了類人視覺搜索(Humanoid Visual Search,HVS)將主動的頭部轉動融入智能體在復雜環境中的視覺推理,其具備以下特性:
- 交互性:智能體從窄視角開始,在360度的全景圖中行動,每次頭部旋轉都會改變其視覺輸入。
- 具身性:將視覺推理與物理動作結合在一起,要求智能體有意識地協調頭部運動,將其作為思維過程的一部分。
具體地,類人視覺搜索進一步將研究聚焦于以下兩類搜索問題:
類人物體搜索(Humanoid Object Search,HOS):定位并將視線聚焦于目標物體,作為操作的先決條件。在基準中,難度根據初始可見度比率分為簡單、中等和困難三個等級。

類人路徑搜索(Humanoid Path Search,HPS):識別通往目的地的可通行路徑并調整身體朝向,作為移動的先決條件。在基準中,難度分為四個級別,由場景中文本線索的存在以及視覺/文本線索與實際路徑方向的一致性決定。

為了將搜索問題形式化,研究將其構建為一個多模態的推理任務。
簡單來說,多模態大模型通過一個策略網絡來實現工具使用與頭部旋轉,其將時間步、當前觀測、語言指令和歷史狀態作為輸入,輸出文本思維鏈和動作。
值得一提的是,由于人類的推理是間歇性的,僅在關鍵決策點才會被調用,所以研究僅利用在決策點采集的單個360°全景圖構建閉環搜索環境,而無需使用3D模擬器或硬件。

知道了找什么,去哪,和怎么走之后,為了找到最佳的測試環境,研究又構建了一個數據集、基準測試和基線——H*,旨在實現真實360度環境中類人的視覺搜索。

具體來說,H包含約3000個帶標注的任務實例,這些實例來源于多樣化的高分辨率全景視頻。
研究通過為每個任務實例設置四個不同的起始方向來初始化智能體,總共獲得了12000個搜索回合。
H*Bench 的數據來源于全球大都市地區(紐約、巴黎、阿姆斯特丹、法蘭克福)自行采集的素材以及開放平臺(YouTube和360+x數據集),從而提供了廣泛的地理覆蓋范圍。

具體的場景主要包含6個主要類別——零售環境、交通樞紐、城市街道、公共機構、辦公室和娛樂場所。

此外,由于多模態大模型是在靜態、非具身的互聯網數據上訓練的,它們本質上缺乏擬人化視覺搜索所需的空間常識和主動 3D 規劃能力。

因此,研究又通過上面pipeline將多模態大模型轉化為有效的視覺搜索智能體:
- 監督微調:首先在一個精選的多輪數據集上執行SFT,以灌輸基本的任務導向推理和工具使用能力。這教會模型從多模態輸入中生成結構化的動作計劃,建立了強大的行為先驗。
- 多輪強化學習:使用GRPO算法來精煉策略。根據以往的發現,這一 RL 階段鼓勵長程推理,對于開發超越模仿學習基線的魯棒、可泛化的搜索策略至關重要。
實驗驗證
在部署環節,研究基于Qwen2.5-VL-3B-Instruct模型展開上述pipeline,
- 微調:利用GPT-4o生成結構化的思維鏈解釋,并通過人工審核修正,構建高質量的多輪對話軌跡 。
- 多輪強化學習:使用GRPO,對于HPS任務,額外增加了“距離目標的角度距離”作為獎勵項。
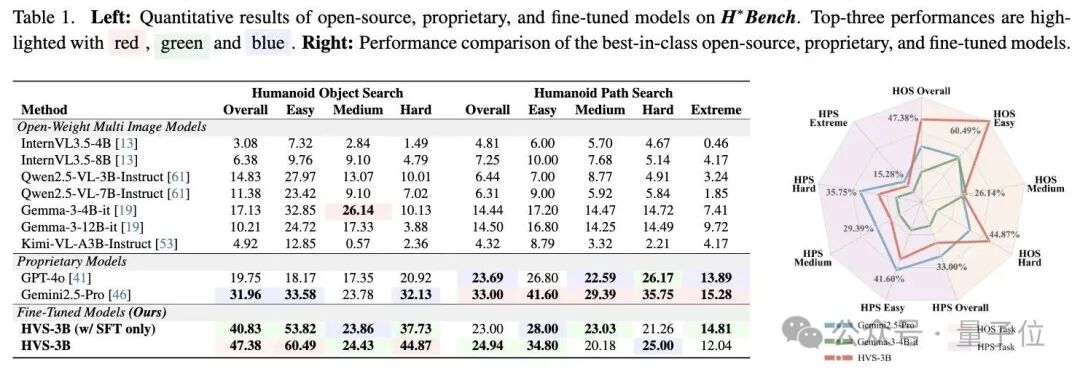
測試表明,經訓練后,Qwen2.5-VL-3B-Instruc在目標搜索(14.83%→47.38%)和路徑搜索(6.44%→24.94%)上的搜索準確率均有所提高。

其中,路徑搜索的上限較低,表明其難度在于需要復雜的空間常識。
而在其他多模態大模型的測試中, 谷歌的Gemini 2.5 Pro是整體表現最強的模型,在HOS任務中達到31.96%,在HPS任務中達到33%。
此外,研究發現,更大的模型尺寸并不一定能保證更好的性能。
無論是Gemma-3還是Qwen2.5-VL系列,較小的4B/3B模型在HOS任務中均超越了其較大的12B/7B對應模型,并在 HPS 任務中表現持平。
通過分析錯誤類型,研究發現
- HOS錯誤主要源于感知能力不足(無法在雜亂環境中識別目標)和感知-動作差距(檢測到目標但無法精細對齊)。
- HPS錯誤則更為復雜,包括缺乏物理常識(如試圖穿墻)、缺乏社會空間常識(如不懂排隊區或員工通道規則)以及視覺-動作不匹配 。
- 主動 vs. 被動:主動視覺搜索(在全景圖中旋轉)優于被動分析(直接輸入全景圖),因為前者更符合人類直覺且避免了全景圖的畸變
總的來說,研究通過引入H*Bench基準和利用后訓練技術,探討了由 MLLM 驅動的in wild類人視覺搜索。
研究表明盡管后訓練能夠有效地提高低級感知-運動能力(例如視覺定位和探索),但它也暴露了高級推理方面的根本瓶頸,這些推理需要物理、空間和社會常識。
One more thing
這篇研究出自紐約大學的李一鳴團隊,在推文中,他感謝了謝賽寧和chen feng的指導。

李一鳴目前在英偉達就職,擔任研究科學家,與Marco Pavone教授合作,研究物理人工智能和自動駕駛。

他于2025年在紐約大學取得博士學位,師從chen feng教授,研究機器人感知。
值得一提的是,在他的簡介中,他還表明自己將于2026年入職清華大學人工智能學院,擔任助理教授。

參考鏈接
[1]https://yimingli-page.github.io/
[2]https://x.com/YimingLi9702/status/1993676992303268142
[3]https://x.com/sainingxie/status/1993776740154610084?s=20
[4]https://arxiv.org/pdf/2511.20351
- 清華成立具身智能與機器人研究院2025-12-04
- DeepSeekV3.2技術報告還是老外看得細2025-12-04
- 后生可畏!何愷明團隊新成果發布,共一清華姚班大二在讀2025-12-04
- 爆發力超越波士頓動力液壓機器人,PHYBOT M1實現全球首次全尺寸重型電驅人形機器人完美擬人態后空翻2025-11-26
相關閱讀








