Kimi開源新線性注意力架構(gòu),首次超越全注意力模型,推理速度暴漲6倍
KV緩存減少75%
聞樂 發(fā)自 凹非寺
量子位 | 公眾號 QbitAI
Transformer的時代,正在被改寫。
月之暗面最新發(fā)布的開源Kimi Linear架構(gòu),用一種全新的注意力機(jī)制,在相同訓(xùn)練條件下首次超越了全注意力模型。

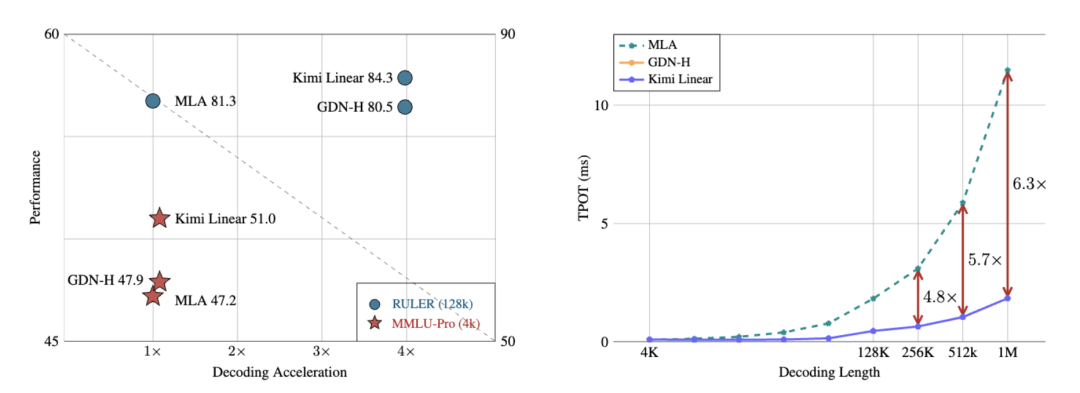
在長上下文任務(wù)中,它不僅減少了75%的KV緩存需求,還實(shí)現(xiàn)了高達(dá)6倍的推理加速。
有網(wǎng)友表示期待:這個架構(gòu)下的Kimi K2.5何時來??

不過,咱還是先來看一下Kimi Linear是如何挑戰(zhàn)傳統(tǒng)Transformer的。
讓注意力真正線性化
Transformer確實(shí)聰明,但聰明得有點(diǎn)太燒錢。
它的注意力機(jī)制是全連接的,每個token都要和其他所有token打交道。
計算量也隨著輸入長度呈平方增長(O(N2)),而且每生成一個新詞,還要查一遍之前的所有緩存。
這就導(dǎo)致推理階段的KV Cache占顯存極大,尤其是在128K以上的上下文中,顯卡直接崩潰警告。
模型越強(qiáng),顯卡越崩,錢包越痛。

所以,過去幾年無數(shù)團(tuán)隊都在研究線性注意力,希望把計算從 O(N2) 降到 O(N),讓模型能又快又省。
但問題是,以前的線性注意力都記不住東西,快是快了,but智商打折。
現(xiàn)在,Kimi Linear以既要又要還要的姿態(tài)登場了。

Kimi Linear的核心創(chuàng)新是Kimi Delta Attention(KDA)。
它在原有線性注意力的基礎(chǔ)上,引入了細(xì)粒度遺忘門控,不再像傳統(tǒng)線性注意力那樣一刀切地遺忘,而是讓模型可以在每個通道維度上獨(dú)立地控制記憶保留,把重要信息留下,把冗余信息扔掉。
更關(guān)鍵的是,KDA的狀態(tài)更新機(jī)制是基于一種改進(jìn)的Delta Rule(增量學(xué)習(xí)規(guī)則)。
它在數(shù)學(xué)上保證了穩(wěn)定性,即使是在百萬級token序列中,梯度也不會爆炸或消失。
這也讓Kimi Linear能在超長上下文中跑得穩(wěn)。
整個模型采用3:1的混合層設(shè)計,每3層線性注意力(KDA)后加1層全注意力。這樣既保留全局語義的建模能力,又能在多數(shù)層用線性計算節(jié)省資源。
團(tuán)隊還干脆把傳統(tǒng)的RoPE(旋轉(zhuǎn)位置編碼)砍掉,讓KDA自己通過時間衰減核函數(shù)學(xué)習(xí)序列位置信息。
結(jié)果,沒有RoPE,模型反而更穩(wěn)、更泛化。

在KDA的狀態(tài)更新過程中,Kimi Linear用了一種叫Diagonal-Plus-Low-Rank(DPLR)的結(jié)構(gòu)。
核心思路是把注意力矩陣拆成「對角塊+低秩補(bǔ)丁」,這樣GPU在并行計算時能一次性處理更多內(nèi)容,吞吐率直接翻倍。
此外,團(tuán)隊還引入了分塊并行計算和kernel fusion優(yōu)化(內(nèi)核融合),極大地減少了顯存I/O開銷。
在工程部署上,它還能無縫對接vLLM推理框架,不需要改模型結(jié)構(gòu),也不需要改緩存管理,直接替換即可。
這意味著,任何基于Transformer的系統(tǒng)在理論上都能一鍵升級為Kimi Linear。
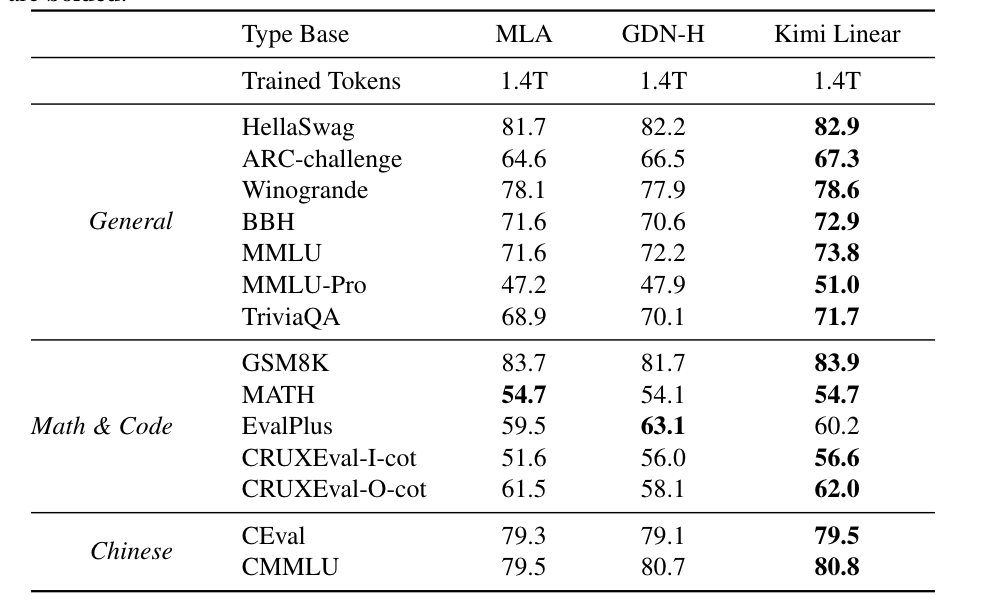
實(shí)驗結(jié)果顯示,在相同訓(xùn)練規(guī)模下,比如1.4T tokens,Kimi Linear在MMLU、BBH、RULER、GPQA-Diamond等多個基準(zhǔn)測試上全面超越Transformer。
長上下文推理中,解碼速度提升最高達(dá)6倍,KV緩存減少75%。
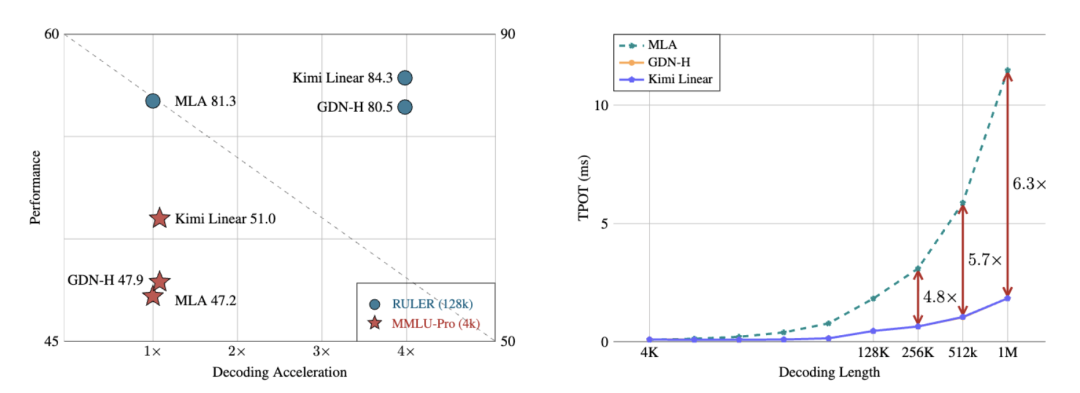
不僅沒丟精度,還在數(shù)學(xué)推理、代碼生成等任務(wù)上更穩(wěn)定、更高分。

One More Thing
不得不說,Transformer的地位正在被重新審視。
Mamba的作者曾用長文論述Transformer并非最終解法,狀態(tài)空間模型(SSM)在長序列建模和高效計算上展現(xiàn)出強(qiáng)大的替代潛力,這也讓人們重新思考注意力是否真的是唯一答案。
之前谷歌推出的MoR架構(gòu),探索用遞歸結(jié)構(gòu)取代部分注意力,通過動態(tài)計算深度來減少冗余推理,進(jìn)一步提升效率。
蘋果公司也在多項研究中傾向采用Mamba,而非傳統(tǒng)Transformer,理由很現(xiàn)實(shí)——SSM架構(gòu)更節(jié)能、延遲更低、適合在終端設(shè)備上部署。
現(xiàn)在,Kimi Linear則從另一條路線突圍,在線性注意力方向上取得突破。
或許這也預(yù)示著,AI架構(gòu)正在告別對傳統(tǒng)Transformer的路徑依賴,邁向多元創(chuàng)新時代。
但值得一提的是,剛剛坐上開源模型王座的MiniMax M2,卻重新用回了全注意力機(jī)制。
技術(shù)報告:https://huggingface.co/moonshotai/Kimi-Linear-48B-A3B-Instruct
— 完 —
- 又一高管棄庫克而去!蘋果UI設(shè)計負(fù)責(zé)人轉(zhuǎn)投Meta2025-12-04
- 萬卡集群要上天?中國硬核企業(yè)打造太空超算!2025-11-29
- 學(xué)生3年投稿6次被拒,于是吳恩達(dá)親手搓了個評審Agent2025-11-25
- 波士頓動力前CTO加盟DeepMind,Gemini要做機(jī)器人界的安卓2025-11-25
相關(guān)閱讀





把大核卷積拆成三步,清華胡事民團(tuán)隊新視覺Backbone刷榜了,集CNN與ViT優(yōu)點(diǎn)于一身
超越SwinTransformer與ConvNeXT