全新合成框架SOTA:強化學習當引擎,任務合成當燃料,螞蟻港大聯合出品
PromptCoT框架全面升級
AntResearchNLP團隊 投稿
量子位 | 公眾號 QbitAI
下一步,大模型應該押注什么方向?
螞蟻通用人工智能中心自然語言組聯合香港大學自然語言組(后簡稱“團隊”)推出PromptCoT 2.0,要在大模型下半場押注任務合成。

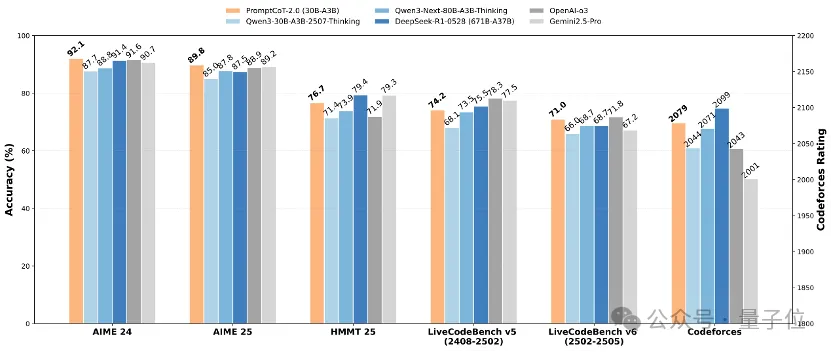
實驗表明,通過“強起點、強反饋”的自博弈式訓練,PromptCoT 2.0可以讓30B-A3B模型在一系列數學代碼推理任務上實現新的SOTA結果,達到和DeepSeek-R1-0528, OpenAI o3, Gemini 2.5 Pro等相當的表現。
PromptCoT 2.0:PromptCoT框架的一次全面升級
在一年前的這個時候,在整個AI社區都在思考大模型應該押注什么方向的時候,OpenAI公布了o1的預覽版,通過深度思考的新范式以及在競賽數學代碼任務上遠遠甩開gpt4o的性能,讓整個大模型社區進入了“深度思考”時代。
如今,又是一年9月,螞蟻與港大聯合在大模型下半場押注任務合成。
為什么是任務合成?
事實上,按照OpenAI規劃的AGI藍圖,大模型社區正在從Reasoners向Agents急速推進,各種關于Agent的工作,包括搜索、軟件工程、客服、以及GUI等層出不窮。
在這林林總總的工作背后,團隊認為,無論是對大模型推理,還是對于方興未艾的智能體,有兩項技術是起著基石作用的:
一是強化學習。作為強化學習之年,該項技術已經得到社區足夠多的關注與投入,無論是方法還是框架都在急速推進。

而另一個,團隊認為是任務合成。這里的任務合成是一個比較廣泛的概念,可能包含問題合成、答案合成、環境合成、乃至評估合成。之所以將其和強化學習并列起來,團隊有一些底層思考。
①當大模型走出數學代碼競賽之后,必然要面對的是現實世界中長尾而又復雜的問題,而“長尾”和“復雜”兩個屬性疊加在一起,就會導致一個數據稀缺的問題。沒有一定量高質量(難度合適、覆蓋全面)的任務數據作為起始點,無論強化學習多么強大,也沒法發揮作用,甚至沒法開始;
②當大模型變得越來越智能之后,可以預見合成數據的質量會越來越高,那么有一天,合成數據也許會取代人工數據成為大模型訓練的主力。
強化學習是引擎,任務合成提供燃料,這是團隊對未來大模型后訓練范式的一個判斷。
在這樣的判斷下,團隊首先從問題合成切入,力圖發展一套通用且強力的問題合成框架。這樣的選擇一是任務合成的課題比較龐大;二是問題合成可以說是任務合成的基石和起點。
早在今年年初,團隊就提出了PromptCoT框架,通過將“思考過程”引入問題合成來提升合成問題的難度。

在這個框架下,團隊將問題合成拆解成了概念抽取、邏輯生成、以及問題生成模型訓練三個步驟。按照這三個步驟,通過精心構造的提示詞生成了一批問題合成訓練數據,并由此訓練了一個基于Llama3.1-8B的問題生成模型。
利用這個模型,團隊生成了400k SFT數據,并用這份數據訓練了DeepSeek-R1-Distill-Qwen-7B模型,在MATH-500、AIME 2024以及AIME 2025上的表現均超過了32B的s1模型。
在開源模型性能不斷刷新的浪潮下,團隊也在思考:
- PromptCoT能否走向更可擴展,更優雅的學習范式?
- 純粹的合成問題有可能在效果上超過人工數據嗎?
- 如果說SFT是通過蒸餾強模型來提升弱模型,那么強模型的能力還能通過PromptCoT提升嗎?特別是當這些模型已經消費了社區海量的開源數據之后?
為了回答這些問題,團隊推出了PromptCoT 2.0。
PromptCoT 2.0為一個可擴展框架,它用期望最大化(EM)循環取代了人工設計,在循環中,推理鏈會被迭代優化以指導提示構造。這樣生成的問題不僅更難,而且比以往語料更加多樣化。
PromptCoT 2.0在PromptCoT 1.0基礎上,實現了效果、方法、數據的全面升級。
效果升級:強化學習+SFT,強弱模型齊起飛
前面已經展示了PromptCoT 2.0+強化學習讓強推理模型達到新SOTA的結果。那么如果用PromptCoT 2.0合成的問題進行蒸餾來訓練弱推理模型,效果會怎樣呢?

從表里可以看到,在完全不依賴人工問題的情況下,PromptCoT 2.0大幅提升了弱模型的數學與代碼推理能力,且整體表現優于依賴人工問題構建的數據集(如OpenMathReasoning、OpenCodeReasoning)。
這一結果充分說明,相較于人工數據,合成數據具備更強的可擴展性,未來有望成為推動大模型推理能力提升的核心動力。與此同時,團隊使用的教師監督(來自GPT-OSS-120B-medium)在表達上更為緊湊(平均推理長度更短)。在保證高質量的前提下,較短的輸出不僅減少了推理開銷,也為更高效的大模型訓練和推理提供了新的可能。
更重要的是,團隊此次全面開源了4.77M個合成問題及對應的教師監督,供社區進行模型訓練,特別是一些不適于LongCoT的模型(如擴散語言模型)。
數據升級:更難、更具差異化
在數據層面,開源的4.77M合成數據展現出兩個顯著特征:
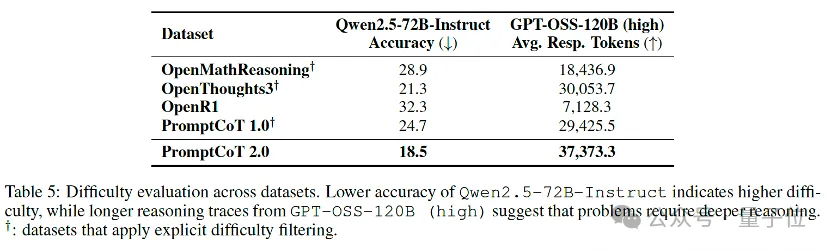
1、更難:在零微調評測下(例如直接使用強指令模型解題),PromptCoT 2.0表現為更低的即刻正確率和更高的推理token消耗,說明這些題目更能“咬合推理”,有效挖掘模型潛在的推理上限。

2、更具差異化:基于all-MiniLM-L6-v2的嵌入均值與余弦距離,并通過MDS映射到二維空間后,PromptCoT 2.0的數據點與現有開源題集(OpenMathReasoning、OpenThoughts3、OpenR1 等)形成了獨立分簇,而后者之間分布更為接近。
這表明 PromptCoT 2.0并非簡單重復已有題庫,而是補充了其中缺失的“困難+新穎”區域,為模型訓練提供了額外的分布層增益。
方法升級:從提示工程到EM算法
PromptCoT 2.0在PromptCoT 1.0基礎上引入基于期望最大化(EM)的優化過程,使邏輯生成模型和問題生成模型能夠在迭代中相互促進。
具體而言,E-step通過獎勵信號不斷優化邏輯生成,使其更契合概念并支撐問題構造;M-step則利用這些邏輯持續改進問題生成模型。與以往依賴人工提示或特定領域規則的方式不同,PromptCoT 2.0完全可學習、跨領域通用,能夠在幾乎無需人工干預的情況下,生成更具挑戰性和多樣性的問題。
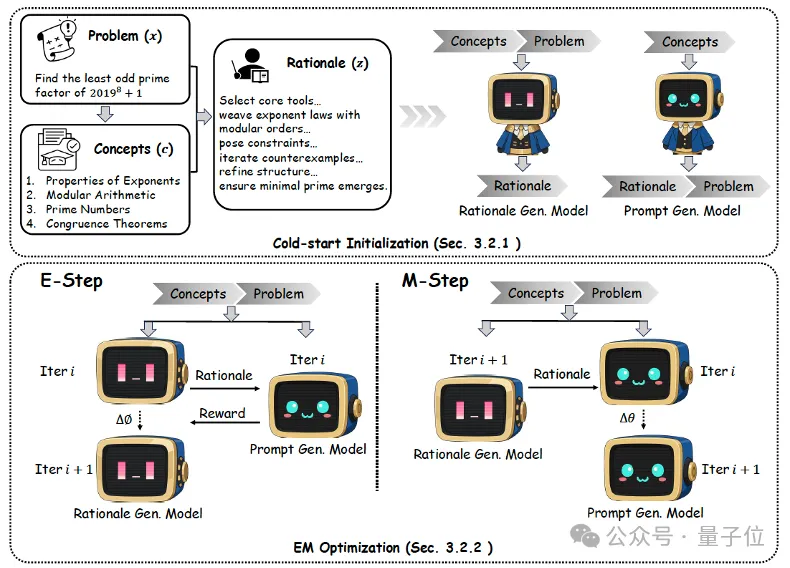
在后訓練上,除了SFT,PromptCoT 2.0采用了一種強化學習方法。在給定獎勵信號的情況下,PromptCoT 2.0從合成問題出發,讓強基線模型通過自我探索推理路徑來進行學習。實際優化兼容PPO、GRPO、DPO等各種在線離線強化學習方法。
這里PromptCoT 2.0對獎勵信號要求較低,只要相對易得,可以包含一定噪音(實驗中采用對數學代碼分別采用的是GPT-OSS-120B和Qwen3-32B)。在這種情況下,強基線模型就可以通過自博弈方式從自我經驗中進行學習提升。
面向未來:從Reasoners走向Agents——問題合成×環境合成×多模態
盡管實現了大幅升級,但從任務合成來看,PromptCoT 2.0仍只是起點。下一步,PromptCoT將會考慮幾個方向:
1、Agentic環境合成。不僅出題,還要“造環境”(網頁、API、GUI、代碼沙盒、對話場景),讓模型在可交互、可驗證的世界里學會規劃、操作與反思。
2、多模態任務合成。把圖像/視頻/表格/語音等信息納入“概念→邏輯→任務”的模式,催生跨模態推理與工具使用。
3、自獎勵和對局式自進化。 在社區中,已有一些自獎勵以及基于“兩方博弈”的自進化探索,例如“出題者–解題者”或“執行者–評審者”的對抗協作模式。這些探索為大模型發展提供了很好的思路,但卻沒法實現強基座模型下的SOTA效果。
那么,如果PromptCoT和自獎勵相結合,或者EM內循環與博弈式外循環相結合,有沒有可能進一步提升模型上限呢?
時間很緊,可做的卻很多,在PromptCoT 2.0發布之際,下一個PromptCoT也已經在路上了。
該工作的第一作者為香港大學計算機系博士生趙學亮,目前在螞蟻技術研究院通用人工智能中心實習。螞蟻技術研究院通用人工智能中心自然語言組武威、關健、龔卓成為共同貢獻者。
論文鏈接:https://arxiv.org/abs/2509.19894
Github鏈接: https://github.com/inclusionAI/PromptCoT
- 商湯分拆了一家AI醫療公司,半年融資10億,劍指“醫療世界模型”2025-12-02
- “豆包手機”在二手市場價格都翻倍了……2025-12-05
- OpenAI首席研究員Mark Chen長訪談:小扎親手端湯來公司挖人,氣得我們端著湯去了Meta2025-12-03
- 讓大模型學會“高維找茬”,中國聯通新研究解決長文本圖像檢索痛點|AAAI 2026 Oral2025-12-01