
京東AI一攬子開源!超多核心項目全開源,GitHub萬star項目也有新進展了
從大模型到Agent平臺,開源的好徹底
超越DeepMind的Langfun、抱抱臉的Smolagent等,國產智能體位列全球智能體第一梯隊!
GitHub明星開源項目、行業首個100%開源的企業級智能體JoyAgent,迎來重要更新——
進一步開源DataAgent和DCP數據治理模塊,加速企業級落地。
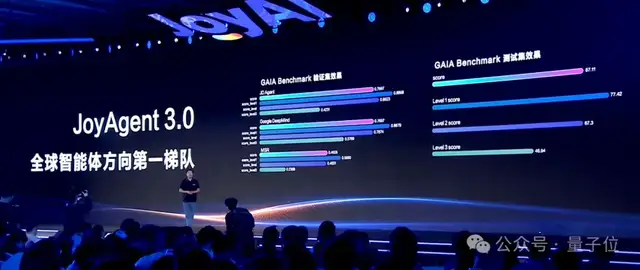
升級后的JoyAgent,在全球權威智能體評測榜單GAIA,Validation集準確率77%,Test集準確率超67%,相較于此前成績實現穩步提升。
該項目在GitHub的熱度也順勢走高,Star數迅速過萬,截至發稿已達10.1k。

有意思的是,其背后團隊京東云,不打算讓JoyAgent的突破成為孤例。
就在最近,京東亮劍,系統性將其歷經內部復雜場景錘煉的系列AI能力,從大模型到Agent,從推理框架到模型安全,悉數開源。
其中就包括行業首個突破可信推理與全模態能力的開源醫療大模型京醫千詢2.0、GAIA評測得分59.14的OxyGent多智能體框架……
開發者無需從零開始,開箱即可基于京東驗證過的技術快速創新。

開源Agent“雙子星”
先來看JoyAgent,自7月份在WAIC上作為首個100%開源企業級智能體亮相后,便廣受關注。
它的開創性在于,當市面上大多數Agent還停留在僅開源SDK或者框架時,它直接將前后端、框架、引擎、核心子智能體等在內的完整產品能力全部開放,企業無需二次開發,可直接本地部署、開箱即用。
這種徹底的開放性,讓它在開發者社群中迅速積累起好口碑。

而現在,這一項目升級為JoyAgent 3.0。
此番升級,沒有停留在小修小補,而是直指企業AI落地深水區——數據利用難題。
許多智能體在對答時表現驚艷,但一旦需要連接企業內部的工作流、理解結構化的數據庫或半結構化的知識庫,往往就束手無策。
JoyAgent 3.0的突破正在于此。

JoyAgent 3.0進一步開源數據分析智能體DataAgent和DCP數據治理模塊。據稱,這也是行業首個集成數據治理DGP協議及智能問數、診斷分析能力的開源項目。
與市場上其他方案相比,JoyDataAgent的“端到端開箱即用”特性顯得尤為突出。
當前一些競品或不支持深度數據治理,或缺乏診斷分析能力,或核心代碼并未開放。而JoyDataAgent將數據治理DGP協議、智能問數、診斷分析和工作建議等能力完整開源,形成了一個通用框架。
企業開發者只需按照DGP協議對數據表進行治理即可。

業務人員可以直接用自然語言提問“去年比前年銷售額同比增加多少?”“2024年上海的銷售額變化趨勢如何?”,系統便能自動查詢數據庫、定位問題并生成分析洞察。
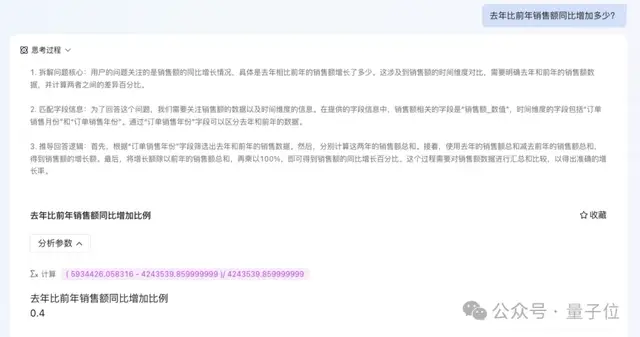
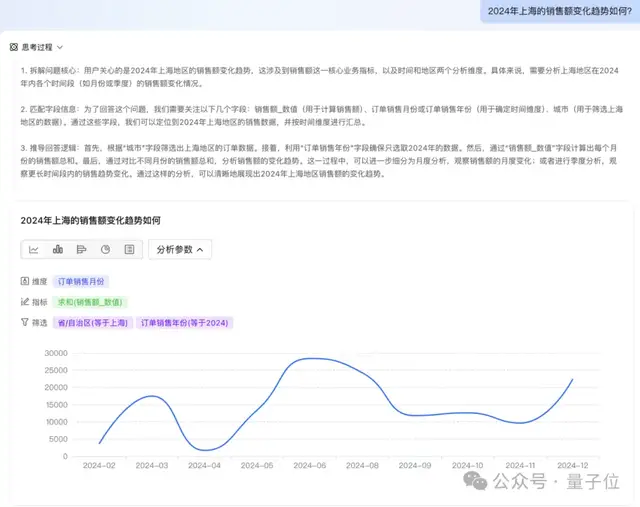
這背后是兩階段動態選表、細粒度查詢拆解等先進的TableRAG技術,以及支持趨勢、周期、異常歸因等多種方法的診斷分析引擎。
尤為重要的是,它能處理那些“沒有固定答案”的復雜問題,通過SOPPlan模式和智能分析,為業務決策提供全新的視角洞察。
JoyAgent 3.0的全面開放還體現在支持MCP、A2A等主流協議,企業開發者自己開發的智能體可以無縫加入到JoyAgent中,參與統一調度與協同工作;JoyAgent的智能體也能被輕松發布成標準服務,像插件一樣嵌入到企業現有的各類業務系統里。
這種開放性,使得它能夠靈活適配千行百業的獨特流程,而非讓企業去適應一個固化的平臺。
為降低開發門檻,平臺還提供了豐富的開箱即用工具集。
例如,京東自研的NL2Workflow功能,允許用戶用自然語言直接生成可編輯、可執行的工作流。

其效果也直接反映在GAIA榜單結果上——JoyAgent在驗證集準確率77%,測試集突破67%,躋身全球第一梯隊。
同時在權威自然語言轉SQL評測基準BIRD-Bench上,JoyDataAgent-SQL Test集準確率75.74%,Dev集準確率74.25%。

憑借在京東內部超3萬個智能體的實踐錘煉,JoyAgent 3.0已然成為一個生產級智能體平臺。

如果說JoyAgent是京東為企業端準備的一份“精裝解決方案”,那么開源OxyGent多智能體框架,則是給開發者們的一座“樂高工廠”。

它的設計理念極其簡潔:用純Python,像搭積木一樣組裝你的AI團隊。
開發者無需面對冗余代碼和令人頭疼的YAML配置。該框架將工具、模型、智能體統統抽象為標準的Oxy原子組件。開發者用純Python即可像拼裝樂高一樣自由組合,代碼即插即用。
OxyGent的獨特之處,在于其切面設計理念。無論何種AI原子應用,都統一繼承Oxy算子的生命周期。更值得一提的是,官方提供強大的推理可視化能力,如同為AI思維裝上“X光”,一眼洞察瓶頸。未來,當Agent、MCP、LLM成為歷史,新生的AI應用仍將成為新的“Oxy原子”,生長于OxyGent這個始終進化、面向未來的框架之中。
在GAIA評測中,OxyGent拿下59.14分,緊追開源標桿OWL(60.8分)。
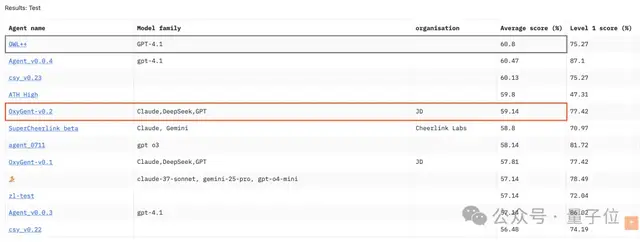
至此,京東Agent的開源格局清晰可見,JoyAgent向下扎根,解決企業“數據最后一公里”的現實難題;OxyGent向上生長,賦予開發者像搭積木一樣創造AI團隊的無限可能。
“全景式”開源,瞄準產業痛點
除了重頭戲Agent,縱觀京東開源全貌,打滿兩個關鍵詞:徹底、全覆蓋。
瞄準產業痛點,京東目前已經實現大模型產品和服務的全棧覆蓋——
不僅包含上層的Agent應用開發環節,其開源體系更是已經延伸至底層基礎設施與中間層的模型服務和工具。
先說大熱的AI健康領域,面向復雜專病診療,京東健康開源行業首個突破可信推理及全模態能力的醫療大模型——京醫千詢2.0。

眾所周知,作為相對嚴肅的醫學領域,AI問診的最大痛點難點就在于準確性問題。
為此,京醫千詢2.0會嚴格模擬醫生臨床診療思維路徑,深度融合醫學知識體系與真實診療邏輯,模型可在推理過程中主動引入并對齊外部的循證醫學證據(即基于科學研究和臨床實踐的可靠醫學數據和研究成果),以確保推理符合醫學共識。
據介紹,為了實現可信推理,團隊做了兩項努力:
- 構建高質量長序列推理訓練數據:讓模型學習處理連續復雜的推理過程,而不僅僅是簡單片段化的信息。
- 建立基于人類偏好的持續學習閉環:這個閉環會根據人類專家的反饋,對模型輸出進行糾正和強化,讓模型的決策更加符合人類專家的標準。
在此基礎上,京醫千詢2.0還實現了對文本、影像、檢驗報告等多模態醫學數據的深度融合解析。
為什么要多模態?答案顯而易見。
和其它領域一樣,多模態也是醫療大模型真正走入臨床應用的必經之路。有了這一能力,模型不僅能夠理解醫學語言、提取關鍵臨床信息,還能夠精準解析影像資料,自動識別并描述感興趣區域的位置特征與性質信息。
如此一來,模型就能建立起跨越不同數據模態的“思維鏈”,實現多步、多源信息融合推理。
在涵蓋醫學影像病灶分割、報告生成、文檔理解等5大能力的21項評測中,京醫千詢2.0的綜合表現展現出領先優勢。

可信推理+多模態,當模型的診療過程更貼近真實場景時,落地才變得更加可能。
實際上,自2023年推出并于今年2月全面開源以來,京醫千詢已在多家醫院、健康管理中心、醫藥零售企業、體檢中心以及養老機構得到應用。此次升級和持續開源無疑也會加速這一進程。
再來看基礎設施方面,京東開源了自研的、專為國產芯片優化的xLLM推理框架,提供企業級的服務部署,使得性能更高、成本更低。
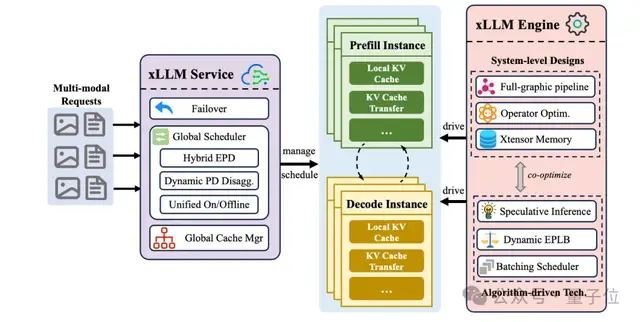
作為一個端云一體的大模型推理架構,它采用服務-引擎分離的模式來提升推理效率。
- 服務層(主要負責處理各種請求):包括在離線請求彈性調度、動態PD分離、EPD混合機制及高可用容錯設計;
- 引擎層(主要負責實際運算):包括多流并行計算、圖融合優化、投機推理、動態負載均衡及全局KV緩存管理。

目前該架構已支持包括大模型、多模態大模型、生成式推薦等場景在國產芯片上的高效部署。
2025京東全球科技探索大會期間,Oxygen-9N-xLLM大模型推理引擎也正式官宣開源。這一推理引擎實現了服務-引擎分離的創新架構,在推理效能上取得進展,幫助京東零售業務實現5倍效率提升和90%成本優化,推動國產AI Infra從跟隨國際開源框架到定義新一代推理標準。

隨著AI深入業務核心,安全防線上亦不容有失。
京東還開源JoySafety大模型安全,提供從輸入到輸出的全鏈路防護。
其以可插拔的安全原子能力與DAG策略編排為核心,企業可根據自身業務需求,自定義安全策略,實現從通用防御到智能精準防護的升級。
具體來說,它內置了從敏感詞識別到提示詞注入檢測等多維度的安全能力,獨到之處在于“流式輸出檢測+撤回”機制,能在AI回答的過程中進行毫秒級風險判斷,一旦發現有問題可立即中斷。
經京東內部復雜業務驗證,它能將惡意攻擊和提示詞注入成功率降低95%以上,并且支持Docker一鍵部署,讓企業分鐘級就能獲得生產級的安全防護。

此外,加上京東已開源的向量數據庫Vearch、跨端開發框架Taro等,這些開源技術并非孤立存在,而是共同圍繞AI落地過程中的實際需求展開。
京東開源,意在何方?
京東這次如此大規模、成體系地開源其核心AI技術,背后的邏輯遠不止于技術分享,而是直指AI落地最難啃的骨頭——如何讓前沿技術真正在千行百業中用得起、用得好。
當前,企業面對AI時往往陷入兩難:
一方面,誰都害怕錯過AI大模型的歷史性機遇,迫切希望擁抱變革;但另一方面,具體到自身業務,究竟該如何下手、如何見效,又常常感到無從下手。動輒數百萬的試錯成本,以及高技術門檻和不確定的回報,讓許多企業望而卻步。
而京東的選擇,是換一種思路破局,將自身在復雜業務場景中錘煉出的產業實踐——包括工程技術、算法模型與落地經驗——通過開源的方式,變成整個行業的“公共基礎設施”。
這步棋,首先為開發者掃清了障礙。以往需要重金投入才能觸及的企業級AI能力,如今得以“開箱即用”。開發者可以零成本直接基于這些久經考驗的代碼進行創新,這將激發來自社區的應用靈感與創新活力。
而當無數開發者基于京東的開源項目進行構建時,一種更深層的價值開始浮現——生態的協同與標準的形成。比如京東通過在開源項目中推動如DGP數據治理協議等技術標準,有助于推動形成統一、互操作的技術規范。
最終,這一切也將回饋于京東自身。
通過開源吸引全球開發者參與共建,京東能持續反哺自身技術迭代。當越來越多的企業選擇基于這套“京東系”開源技術來構建其核心AI應用時,一個以京東為核心的繁榮技術生態便水到渠成。
在通往AGI的道路上,單一公司的技術突破存在天花板,而生態的繁榮則能集行業共智。
京東這步棋,下的正是未來。
GitHub地址:https://github.com/jd-opensource
- 梁文鋒,Nature全球年度十大科學人物!2025-12-09
- 英偉達巧用8B模型秒掉GPT-5,開源了2025-12-06
- SpaceX估值8000億美元超OpenAI,IPO就在明年2025-12-06
- 騰訊發布EdgeOne Pages正式版:國內首個邊緣全棧開發平臺,內測階段用戶突破15萬2025-12-05




