清華首次提出數據驅動控制新形式,算法效率直翻三倍
從模型標準型到數據標準型
iDLab團隊 投稿
量子位 | 公眾號 QbitAI
當大數據席卷各行各業,控制理論也迎來新的拐點:從依賴模型到依賴數據。
但是,在數據驅動控制領域,卻缺乏一種標準化的數據表示形式。
針對這一問題,清華大學李升波教授課題組(iDLab)首次將現代控制理論中的標準型概念引入數據驅動控制(datatic control)范式,提出了一種基于數據的系統描述新形式。
每個標準形式的樣本由必要的轉移和可插拔的屬性組成,分別用于描述系統變化規律和人為定義特征。

不僅如此,該數據標準型還可根據算法需求定制屬性,顯著加速控制器設計,為提高數據驅動算法效率提供了新的思路。
目前,該成果已發表于ACC2025。
從模型標準型到數據標準型
人工智能的蓬勃發展,離不開數據這一核心支柱。
近年來,隨著人工智能技術的廣泛應用,以數據為核心的系統表征方法迅速滲透到控制領域。
控制系統的設計方法正迎來一場從模型驅動向數據驅動的范式變革,即從傳統的模型驅動控制(modelic control,即model-driven control)到數據驅動控制(datatic control,即data-driven control)。

圖1:兩種控制范式對比
模型驅動控制(上方路徑)首先利用系統辨識來擬合一個模型,然后用這個模型來合成控制器。
數據驅動控制(下方路徑)則直接利用數據來求解控制器。
在模型驅動控制(modelic control)的范式下,模型的標準型是一個有力工具。
例如,現代控制理論的奠基人魯道夫·卡爾曼(Rudolf E. Kálmán)指出:將狀態空間模型表示為可控標準型或可觀標準型,無需額外的判斷步驟即可直接確保系統的可控性或可觀性。
此外,現代群論的奠基人之一卡米耶·若爾當(Camille Jordan)指出:任何狀態空間模型都可以轉換為約旦標準型,系統矩陣會變為對角方陣,其對角線元素代表系統的特征值。
因此,只需檢查所有特征值是否為負,即可輕松驗證系統的穩定性。更進一步,不同的特征值對應著系統不同的模態,這使得控制器設計更具針對性。
數據驅動控制(datatic control)范式下的標準型是一個新問題。
近年來,隨著機器人、自動駕駛等具身智能系統的蓬勃發展,海量、復雜的交互數據正以前所未有的速度被生成。這不僅為傳統控制算法帶來了巨大挑戰,也引出了一個全新的議題:
在數據驅動控制范式下,如何構建一個有效利用大規模數據的標準描述方式?即是否存在數據驅動版本的標準型?
數據的描述形式直接決定了后續控制器設計算法的運行效率和可擴展性。
以強化學習為例,訓練算法通常涉及大量的迭代計算和高維數據處理。
在這一過程中,算法很容易陷入重復計算的泥潭,例如在每一步訓練迭代中,都重新計算樣本間的范數距離、特征相似度等信息。
這種重復性的計算不僅耗時,而且對計算資源造成了顯著的浪費,嚴重制約了算法在現實世界中的部署和應用。
因此,如何高效、標準地組織和描述數據,以減少冗余計算、加速算法運行,是數據驅動控制范式面臨的一項核心挑戰。
類比于模型標準型,該研究首次提出,適用于數據驅動控制系統的標準描述形式:每條樣本數據包含兩個部分(如圖2所示):
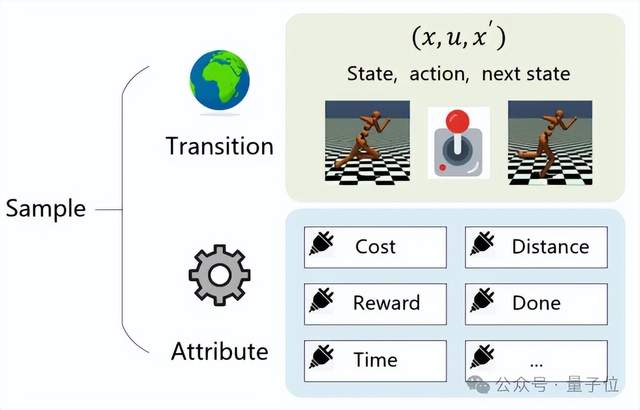
圖2:數據標準型示意圖
(1)必要的轉移部分
,即<當前狀態

,當前動作

,下一狀態

>;
(2)可插拔的屬性部分,例如獎勵信號或其他人工設計特征。
前者蘊含了控制器設計必要的系統的動力學信息,后者可以根據控制器設計算法的需求來靈活定制與取用,降低存儲壓力,加速算法運行,即提高控制器設計效率。
仿真實例
該研究給出了一個典型的數據標準型應用實例。對于給定數據集,為了使得設計出的控制器效果可靠,許多強化學習算法存在近鄰搜索的需求。
例如給定回放的樣本狀態

,算法需要在線計算當前策略
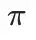
的行為與數據集行為之間的距離:
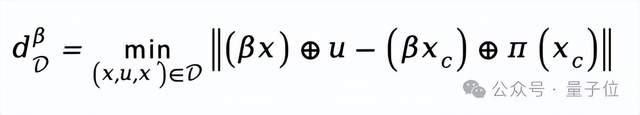
由于需要遍歷數據集中每個樣本來尋找最近鄰,計算負擔非常沉重。
在數據標準型的視角下,對于每個樣本,可以通過提前定制一種特殊的空間屬性,顯著加速近鄰搜索這一過程。
具體地,如圖3所示,提前在樣本空間中約定n個錨點
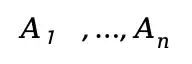
,對于每個樣本,計算其與各錨點的距離保存為空間屬性。
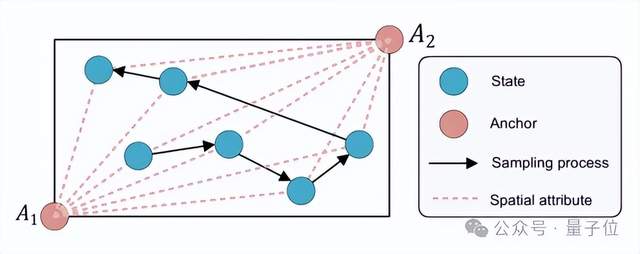
圖3:標準型的空間屬性示意圖 圖3:標準型的空間屬性示意圖
當每個樣本都具備空間屬性后,該研究給出如下空間篩選條件定理來加速近鄰搜索。
定理1(空間篩選條件)
考慮一個包含
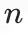
個錨點的數據集。記C為一個選定的樣本,而S為任意其他樣本。若S位于C的R-鄰域范圍內,則一個需要滿足的
必要條件為:
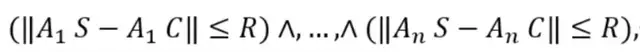
其中

表示表示邏輯與運算符。

圖4:空間標準型的空間篩選機制示意圖
應用這一空間篩選條件,只需要一行判斷指令,就可以快速縮小候選范圍(如圖4所示),顯著加速最近鄰搜索的過程,從而提高算法的整體運行效率。
該研究在D4RL數據集的Hopper環境下進行了實驗,對引入空間標準型前后的訓練時間進行了比較。
圖5清晰地展示了這一改進:基礎版本(藍色曲線)的訓練耗時約20小時,而應用了空間標準型篩選機制(橙色曲線)后,訓練時間縮短至僅7小時,實現了三倍的效率提升。
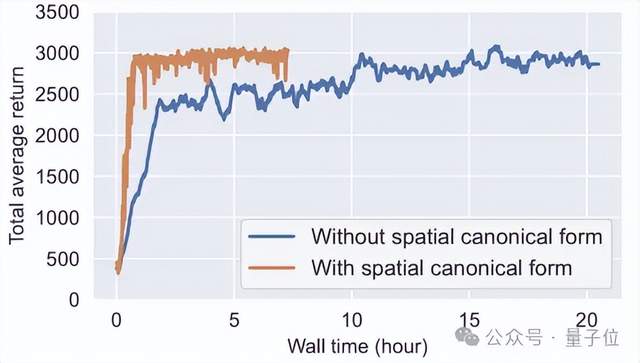
圖5:應用空間標準型前后的訓練時間對比
總的來說,數據標準型可以極小的存儲空間開銷,換取顯著的時間效率優勢。
除此之外,它還可以根據算法需求靈活插拔屬性部分來降低存儲需求,具備擴展性,為提高數據驅動控制算法效率提供了新的方向。
論文鏈接:https://ieeexplore.ieee.org/document/11107988
- 快手進軍AI編程!“模型+工具+平臺”一口氣放三個大招2025-10-24
- 匯報一下ICCV全部獎項,恭喜朱俊彥團隊獲最佳論文2025-10-22
- OpenAI以為GPT-5搞出了數學大新聞,結果…哈薩比斯都覺得尷尬2025-10-20
- 首創“AI+真人”雙保障模式!剛剛,百度健康推出7×24小時「能聊、有料、會管」AI管家2025-10-18
相關閱讀