
快慢思考不用二選一!華為開(kāi)源7B模型實(shí)現(xiàn)自由切,精度不變思維鏈減近50%
引入模式自動(dòng)切換并未犧牲精度
允中 發(fā)自 凹非寺
量子位 | 公眾號(hào) QbitAI
國(guó)產(chǎn)自研開(kāi)源模型,讓模型不用在快思考和慢思考間二選一了!
華為最新發(fā)布openPangu-Embedded-7B-v1.1,參數(shù)只有7B,卻身懷雙重“思維引擎”。
要知道,長(zhǎng)期以來(lái),大模型快思考與慢思考模式不可兼得,這成為業(yè)界的一大痛點(diǎn)。在當(dāng)前大模型混戰(zhàn)中,各家巨頭都在尋求破局之道,但此前開(kāi)源領(lǐng)域一直缺乏一款可自由切換快慢思維模式的模型。
要快,還是要慢?AI在面對(duì)不同難度的問(wèn)題時(shí)也有“選擇困難癥”。

而現(xiàn)在,openPangu-Embedded-7B-v1.1,通過(guò)漸進(jìn)式微調(diào)策略和獨(dú)特的快慢思考自適應(yīng)模式,既支持手動(dòng)切換“快思考”或“慢思考”模式,也能根據(jù)問(wèn)題難度自動(dòng)在兩種思維模式間無(wú)縫轉(zhuǎn)換。
簡(jiǎn)單問(wèn)題它秒答如飛,復(fù)雜任務(wù)它深思熟慮,一舉填補(bǔ)了開(kāi)源大模型在這一能力上的空白,讓效率與準(zhǔn)確率實(shí)現(xiàn)雙贏。
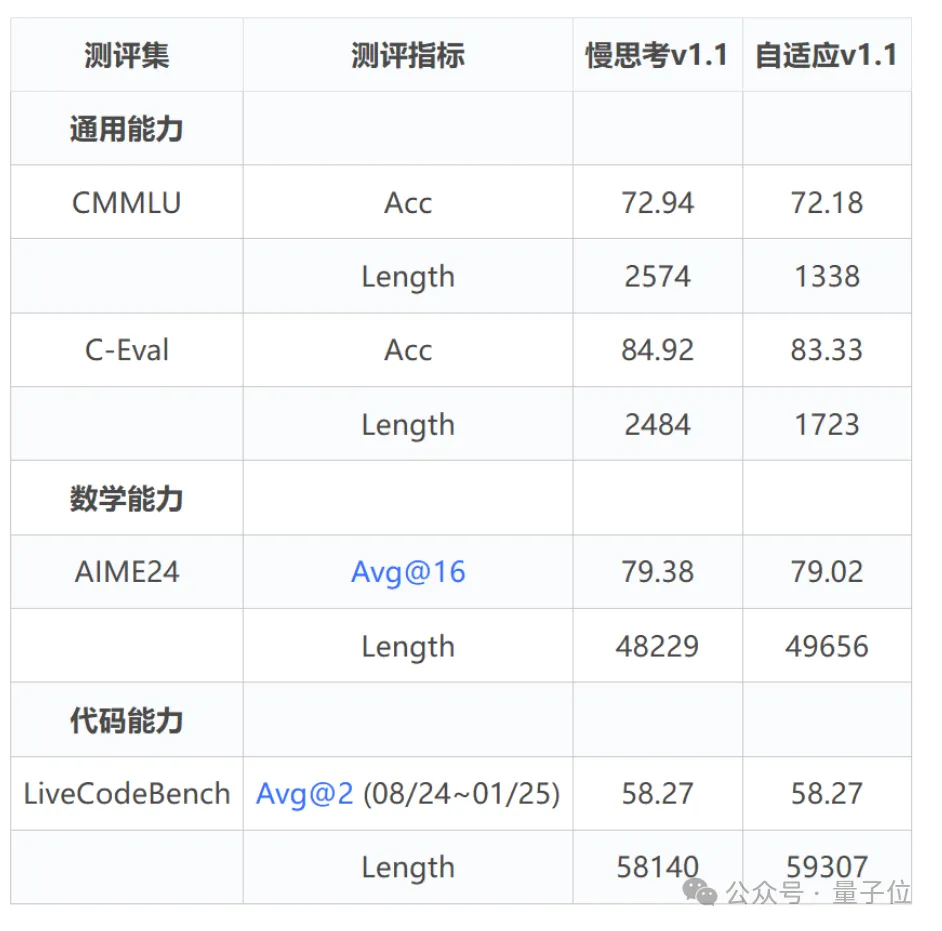
在通用、數(shù)學(xué)、代碼等多個(gè)權(quán)威評(píng)測(cè)中,該模型精度相較于此前模型大幅提升,且引入模式自動(dòng)切換并沒(méi)有犧牲精度。在CMMLU等基準(zhǔn)中,openPangu-Embedded-7B-v1.1保持精度的同時(shí),平均思維鏈長(zhǎng)度縮短近50%。
模型現(xiàn)已在GitCode開(kāi)源。
所以,openPangu-Embedded-7B-v1.1究竟是如何做到的?華為盤(pán)古團(tuán)隊(duì)在模型訓(xùn)練策略上又有哪些創(chuàng)新?
漸進(jìn)式微調(diào)策略:像人一樣“進(jìn)階”學(xué)習(xí)
眾所周知,大模型往往需要海量訓(xùn)練才能具備強(qiáng)大的推理能力。然而,openPangu團(tuán)隊(duì)并未采取一味“填鴨式”的訓(xùn)練方式,而是采用了一種漸進(jìn)式微調(diào)(SFT,Iterative Distillation)策略,模擬人類(lèi)逐步進(jìn)階的學(xué)習(xí)過(guò)程。
通過(guò)精心設(shè)計(jì)的迭代訓(xùn)練,讓模型在每一步都處于“適度挑戰(zhàn)”的學(xué)習(xí)區(qū)間,能力穩(wěn)步提升。

具體來(lái)說(shuō),團(tuán)隊(duì)將漸進(jìn)式微調(diào)劃分為三個(gè)循序漸進(jìn)的階段,每一步都讓模型獲得針對(duì)性的提升:
第一步:合理選題,保持適度挑戰(zhàn)
在每一輪訓(xùn)練迭代中,模型會(huì)根據(jù)自身當(dāng)前能力對(duì)候選訓(xùn)練樣本進(jìn)行難度評(píng)分,優(yōu)先挑選難度適中、不偏易也不偏難的題目來(lái)訓(xùn)練。這樣確保模型始終在與能力相匹配的挑戰(zhàn)中學(xué)習(xí),既不會(huì)因過(guò)于簡(jiǎn)單停滯不前,也不會(huì)因過(guò)難而無(wú)法收獲,步步為營(yíng)拓展能力邊界。
第二步:歸納總結(jié),穩(wěn)固已有知識(shí)
完成一輪訓(xùn)練后,產(chǎn)生的多個(gè)模型版本(不同檢查點(diǎn))不會(huì)簡(jiǎn)單取舍,而是通過(guò)參數(shù)增量融合(inter-iteration merging)合并成統(tǒng)一的模型。這一步相當(dāng)于將新學(xué)到的知識(shí)與原有能力進(jìn)行“匯總?cè)诤稀保屇P偷恼J(rèn)知更加穩(wěn)固,避免遺忘過(guò)去學(xué)到的本領(lǐng)。
第三步:持續(xù)提升,擴(kuò)展能力邊界
隨著上述循環(huán)不斷進(jìn)行,模型積累的知識(shí)與技能越來(lái)越豐富,自身能力水漲船高,能夠勝任更復(fù)雜的數(shù)據(jù)訓(xùn)練。這時(shí),它進(jìn)入了更高水平的“拉伸區(qū)”,可以挑戰(zhàn)此前無(wú)法解答的難題。模型能力的提升又反過(guò)來(lái)推動(dòng)下一輪更高難度的數(shù)據(jù)選擇,形成一個(gè)不斷進(jìn)化的良性循環(huán)。
通過(guò)這樣的漸進(jìn)式訓(xùn)練方式,openPangu-Embedded-7B-v1.1不再是被動(dòng)接受知識(shí)的“填鴨式”學(xué)習(xí)者,而是化身為一個(gè)能夠持續(xù)進(jìn)化的學(xué)習(xí)者。實(shí)驗(yàn)結(jié)果表明,這一策略讓模型的推理過(guò)程更加穩(wěn)定,泛化表現(xiàn)更加強(qiáng)勁。
快慢自適應(yīng)機(jī)制:兩階段課程,從“手動(dòng)擋”進(jìn)階“自動(dòng)擋”
相比之前開(kāi)源的openPangu-Embedded-7B-v1,此次開(kāi)源的openPangu-Embedded-7B-v1.1模型最大的亮點(diǎn),就是引入了獨(dú)特的快慢思考自適應(yīng)模式,使得模型可以自動(dòng)根據(jù)任務(wù)難度選擇使用快思考還是慢思考進(jìn)行解答。
相比4月先行披露的技術(shù)報(bào)告,團(tuán)隊(duì)的快慢思考切換訓(xùn)練方案進(jìn)行了大幅升級(jí),不但從方案上演進(jìn)為了數(shù)據(jù)質(zhì)量驅(qū)動(dòng)的學(xué)習(xí)策略,快慢思考切換的范圍也從數(shù)學(xué)任務(wù)擴(kuò)展到了一般任務(wù)。

第一階段:教會(huì)模型區(qū)分快慢。
在這個(gè)“低難度課程”階段,研究團(tuán)隊(duì)首先通過(guò)數(shù)據(jù)構(gòu)造,讓模型明確什么是“快思考”、什么是“慢思考”。
他們精心構(gòu)建了一個(gè)混合訓(xùn)練數(shù)據(jù)集:在用戶提問(wèn)(Prompt)中附加特殊的標(biāo)識(shí)符,直接告訴模型該用快思考還是慢思考來(lái)回答。通過(guò)在這個(gè)帶有明確指示信號(hào)的數(shù)據(jù)上訓(xùn)練,模型學(xué)會(huì)將特定輸入模式與對(duì)應(yīng)的思維方式、回答風(fēng)格建立關(guān)聯(lián)。
可以說(shuō),這一步猶如給模型裝上“手動(dòng)變速箱”,明確劃定了兩種思考模式的界限,是一堂扎實(shí)的“熱身課”,確保模型具備基本的快慢思維切換意識(shí)。
第二階段:自主學(xué)會(huì)切換。
當(dāng)模型已經(jīng)掌握了顯式控制的本領(lǐng)后,就進(jìn)入更具挑戰(zhàn)性的“進(jìn)階課程”。這一階段不再提供外部快/慢提示,而是要求模型根據(jù)問(wèn)題本身自行判斷何時(shí)該快、何時(shí)該慢。
從簡(jiǎn)單樣本過(guò)渡到復(fù)雜樣本,團(tuán)隊(duì)設(shè)計(jì)了一套數(shù)據(jù)質(zhì)量驅(qū)動(dòng)的自優(yōu)化訓(xùn)練策略:先用第一階段訓(xùn)練好的模型作為“教練”,為同一問(wèn)題生成多樣化的解答鏈路,然后從中挑選質(zhì)量最高的解答,再以這些優(yōu)質(zhì)解答來(lái)有選擇地微調(diào)模型。
通過(guò)這種“從優(yōu)錄取”的訓(xùn)練方式,模型逐漸學(xué)會(huì)了從復(fù)雜問(wèn)題中自主推斷最優(yōu)思考路徑,無(wú)需明確指令就能自動(dòng)在快/慢模式間切換。可以說(shuō),這一步為模型裝上了智能“自動(dòng)變速箱”——它告別了對(duì)外部指令的依賴,實(shí)現(xiàn)了內(nèi)在驅(qū)動(dòng)的決策。這一階段的訓(xùn)練難度顯著高于第一階段,因?yàn)槟P托枰I(lǐng)悟更深層的隱含邏輯,而不再是簡(jiǎn)單遵循提示符號(hào)。
經(jīng)過(guò)兩個(gè)階段環(huán)環(huán)相扣的“課程學(xué)習(xí)”,openPangu-Embedded-7B-v1.1完成了從外部信號(hào)驅(qū)動(dòng)的顯式切換到內(nèi)部能力驅(qū)動(dòng)的隱式切換的蛻變,大幅提升了模型在復(fù)雜推理任務(wù)中的靈活性與自主性。
最終,經(jīng)過(guò)這一套訓(xùn)練流程,新模型成功解鎖了快慢思考模式的雙模式切換——既支持用戶手動(dòng)指定思考模式,也能在無(wú)需人為干預(yù)下自動(dòng)選擇最合適的推理方式。
快慢自適應(yīng)減少簡(jiǎn)單任務(wù)Token量三到五成
如此復(fù)雜的訓(xùn)練設(shè)計(jì),最終效果如何?openPangu-Embedded-7B-v1.1在多個(gè)權(quán)威評(píng)測(cè)上交出了令人欣喜的答卷。
首先是精度的大幅提升。相較前代模型v1版本,新模型在通用、數(shù)學(xué)、代碼等各類(lèi)數(shù)據(jù)集上全面超越了自己過(guò)去的成績(jī)。其中在最棘手的數(shù)學(xué)難題數(shù)據(jù)集(如AIME挑戰(zhàn))上,v1.1版本取得了遠(yuǎn)超v1的領(lǐng)先表現(xiàn)。

更難得的是,在采用自適應(yīng)快慢思考模式下,新模型在復(fù)雜任務(wù)上的準(zhǔn)確率依然保持與純“慢思考”情況下幾乎相同的水準(zhǔn),即引入自動(dòng)切換并沒(méi)有犧牲精度。
其次在響應(yīng)效率上,成果同樣令人眼前一亮。對(duì)于簡(jiǎn)單問(wèn)題,openPangu-Embedded-7B-v1.1能夠自動(dòng)切換為快思考模式,大幅縮短不必要的冗長(zhǎng)推理過(guò)程。
在某些基準(zhǔn)測(cè)試中(例如中文綜合知識(shí)測(cè)試集CMMLU),新模型在保持精度基本不變的前提下,將平均輸出的思維鏈長(zhǎng)度減少了近50%!也就是說(shuō),同一道簡(jiǎn)單題,它給出的解釋步驟幾乎縮短了一半,直接帶來(lái)響應(yīng)效率的翻倍提升。
與此同時(shí),對(duì)于諸如AIME、LiveCodeBench這類(lèi)復(fù)雜度極高的難題,模型依然會(huì)老老實(shí)實(shí)“慢思考”、給出詳盡的逐步推理,從而確保精度與只用慢思考模型相當(dāng)。簡(jiǎn)單題不啰嗦、難題不放棄,這種智能切換讓模型在速度和精度之間取得了很好的平衡。
邊緣AI部署利器:1B小模型性能拉滿
值得驚喜的是,openPangu系列近期不僅升級(jí)了7B模型,還推出了一款專為邊緣AI部署優(yōu)化的輕量級(jí)模型——openPangu-Embedded-1B。
顧名思義,它只有十億參數(shù),但卻通過(guò)多項(xiàng)技術(shù)加持,實(shí)現(xiàn)了“小體量也有大能量”。
在軟硬件協(xié)同設(shè)計(jì)方面,openPangu-Embedded-1B針對(duì)華為昇騰端側(cè)AI硬件進(jìn)行了架構(gòu)優(yōu)化,充分利用芯片特性,大幅降低推理延遲、提升資源利用率。
與此同時(shí),華為團(tuán)隊(duì)采用多階段訓(xùn)練策略(包括從零開(kāi)始的預(yù)訓(xùn)練、多樣化數(shù)據(jù)的課程式微調(diào)、離線同策略知識(shí)蒸餾以及多源獎(jiǎng)勵(lì)的強(qiáng)化學(xué)習(xí)等),全面挖掘模型潛力,顯著增強(qiáng)了模型在各類(lèi)任務(wù)上的表現(xiàn)。
得益于以上創(chuàng)新,這款僅10億參數(shù)的小模型取得了性能與效率的高度協(xié)同,在多個(gè)權(quán)威評(píng)測(cè)中成績(jī)亮眼。
據(jù)公開(kāi)數(shù)據(jù)顯示,openPangu-Embedded-1B創(chuàng)下了國(guó)內(nèi)1B級(jí)模型的新標(biāo)桿,其整體平均成績(jī)不僅全面領(lǐng)先其他同規(guī)模模型,甚至追平了更大參數(shù)模型Qwen3-1.7B的水平。
這充分體現(xiàn)了出色的參數(shù)級(jí)性能比:用更小的模型實(shí)現(xiàn)了媲美大模型的效果,為國(guó)產(chǎn)自研大模型在資源受限場(chǎng)景下的探索提供了新的方向。

綜上,華為 openPangu-Embedded-7B-v1.1 的發(fā)布為當(dāng)前熱度較高的大模型領(lǐng)域帶來(lái)了不一樣的思路。作為參數(shù)規(guī)模為 7B 的輕量級(jí)模型,它通過(guò)漸進(jìn)式微調(diào)和雙階段訓(xùn)練方法,實(shí)現(xiàn)了快慢思考模式的自由切換,在效率與精度之間找到了較好的平衡點(diǎn)。
無(wú)論是面向邊緣部署需求的小模型,還是追求復(fù)雜推理能力的通用模型,盤(pán)古系列的持續(xù)演進(jìn)都展現(xiàn)出國(guó)產(chǎn)大模型的創(chuàng)新活力。
未來(lái),這一具備“快慢思考”特性的模型,有望在更多實(shí)際應(yīng)用場(chǎng)景中發(fā)揮價(jià)值。
項(xiàng)目已在GitCode開(kāi)源:https://gitcode.com/ascend-tribe/openpangu-embedded-7b-v1.1
相關(guān)閱讀

給ChatGPT小費(fèi)真的好使!10塊或10萬(wàn)效果拔群,但給1毛不升反降
量力而行,“小心AGI覺(jué)醒后要欺詐補(bǔ)償”


大模型自信心崩塌!谷歌DeepMind證實(shí):反對(duì)意見(jiàn)讓GPT-4o輕易放棄正確答案
GPT-4o、Gemma 3等大語(yǔ)言模型有“固執(zhí)己見(jiàn)”和“被質(zhì)疑就動(dòng)搖”并存的沖突行為

微軟推出iPhone能跑的ChatGPT級(jí)模型,網(wǎng)友:OpenAI得把GPT-3.5淘汰了
3.8B小模型截胡Llama 3 8B





