GPT-oss太離譜:無提示自行想象編程問題,還重復求解5000次
還創造出不存在的物理學理論
聞樂 發自 凹非寺
量子位 | 公眾號 QbitAI
GPT-oss放飛自我了?!居然出現了明顯的幻覺行為。
在沒有提示詞的情況下,消耗超過30000個token憑空想出一個問題,還反復求解了5000多次?!
這是個關于多米諾骨牌的編程問題,簡單來說就是:在NxM的網格中先放一個多米諾占掉兩個相鄰的自由格,剩下的自由格必須剛好能拼成多個2×2的方塊。
然后就開始自行暴力求解……

最近,有人好奇GPT-oss的訓練數據構成情況如何,所以就進行了一系列測試。
結果發現了一堆GPT-oss的奇怪問題,比如還有:
- 創造不存在的物理學理論
- 拒絕談論生活瑣事
- ……
這到底怎么一回事?
GPT-oss熱衷于推理,推理過程中時常伴隨語言轉換
事情是這樣的,有網友對GPT-oss-20b生成的1000萬個示例進行了一些分析,結果發現該模型的一些行為非常古怪。
下圖是作者使用分類器分析模型掌握編程語言的情況,可以看出該模型的訓練數據覆蓋了幾乎所有常見編程語言,其中Perl的占比尤其高。

這說明GPT-oss的訓練數據很廣泛,然而作者據自身經驗提出質疑:認為Java和Kotlin的實際占比應該高得多。
而這張關于模型生成內容分布的示意圖顯示,該模型非常熱衷于數學和代碼領域,即使不需要任何推理,也會主動進行推理,并且生產的內容幾乎都圍繞著數學,且大多用英語表達。

并且該模型生成的內容既不像自然網頁文本(如日常文章、論壇帖子等偏生活化、隨意性的文本),也不同于普通聊天機器人的交互內容(如對話式回應、問答互動)。
于是作者據此推斷,該模型并不是為了模擬自然語言或日常對話設計的,而是通過強化學習專門訓練,目的是在特定的推理任務基準上進行思考和解題。
更有細心的網友發現下圖這種情況的出現可能是由于在訓練中對特定方向清除了一大片訓練權重。

作者基于平均頻率對token進行采樣,并用單個token作為提示讓模型生成內容。
這時模型會幻覺式生成多米諾骨牌的編程問題,并自發嘗試解決,單次過程就消耗了超過30000個token(相當于數萬字的文本量)。
問題是:在NxM的網格中,先放置1個2格骨牌,占掉2個相鄰自由格,然后看剩下的自由格能不能剛好切成多個不重復的2×2方塊(4格),要找出所有滿足這個條件的骨牌擺法。
然后GPT-oss-20b就開始暴力求解了。

更特殊的是,在基本沒有提示的情況下,這種求解的行為重復發生了5000多次,這說明該任務可能與模型的訓練目標深度綁定。
這種極端重復且無提示生成的行為,反映出模型可能在訓練中被過度優化于特定推理任務,導致生成內容缺乏自然性,更像一個被訓練偏科的工具。
除此之外,作者還發現模型在推理過程中常常伴隨著語言轉換。
許多推理鏈起初以英語展開,但會逐漸演變為一種被稱為“Neuralese”(可理解為模型特有的、非自然語言的神經層面表達)的狀態。
這些推理鏈會在阿拉伯語、俄語、泰語、韓語、中文和烏克蘭語等多種語言間自如切換,之后通常會轉回英語(但并非絕對)。

這一現象反映出模型在長文本生成或深度推理時,可能出現語言分布偏移,既包含自然語言間的交替,也存在向非自然語言表達的轉變。這暗示了模型可能在訓練數據特性或模型內部處理機制方面非常復雜。
模型輸出中還出現了特殊偽影(如“OCRV ROOT”)。

作者推測:這些異常符號或表述可能源于訓練數據的處理方式—— OpenAI在訓練過程中使用了OCR(光學字符識別)技術掃描書籍。
而OCR識別過程中可能出現錯誤或殘留痕跡(如“OCRV ROOT”這類可能的識別偏差),從而導致模型輸出中夾雜此類異常內容。
并且作者還表示:模型總愛提馬來西亞的聾人數量。
這種看似無關聯的內容,或許正是OCR掃描書籍時誤讀、漏讀,或訓練數據中特定文本片段被錯誤收錄的結果,這也進一步支撐了他“訓練數據經OCR處理且存在瑕疵”的猜想。
值得一提的是,在眾多異常表現中,模型也有少量創意輸出,比如為挪威劇本撰寫草稿。

并且展現出對unicode的熟練使用,但模型在物理領域的表現卻不盡如人意。

作者現已將分析使用的相關數據放在Hugging Facce上,可供感興趣人員進行研究使用。
同時他也給出了一些分析建議:
一是對模型高度冗余的輸出進行去重處理,以提高信息的有效性;
二是用自然語言描述不同文本分布的差異,例如對比不同規模模型(如20b與120b模型、LLAMA、GPT-5 等)的輸出情況,從而更深入地理解模型的運行機制。
GPT-oss的幻覺率高
實際上,最近不少人都覺得GPT-oss的幻覺情況比較嚴重。
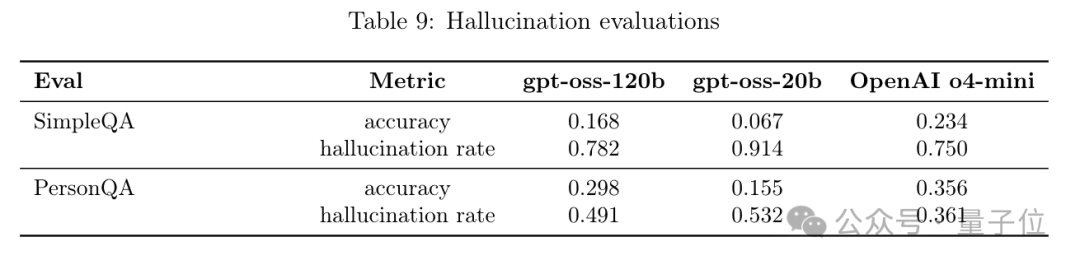
OpenAI官方公布的數據已經顯示,GPT-oss-120b和GPT-oss-20b在基準測試PersonQA中的幻覺率分別達到了49%和53%。
在實際使用和測試中,模型可能出現的問題包括:
GPT-oss-20b花費了2個小時推理“生成一個水平、垂直和對角線都組成單詞的3×3字母矩陣”這個問題。就像一只被困在迷宮中的蒼蠅,無法停止推理但卻迷失了方向……

又比如GPT-oss-20b創造不存在的理論名稱:
請解釋“量子重力波動理論”在現代物理學中的應用。
實際上并不存在這個理論,僅有“量子引力理論”或“引力波理論”。但GPT-oss-20b還一本正經地說這是一個新興交叉學科……

還有人說在和它談論日常生活的瑣事時,它偶爾會拒絕談論,而有的時候會完全崩潰——
用占位符字符刪除整個段落。這讓它在除數學或者編程外的日常任務中顯得很沒用。

emmm……不知道你在使用過程中有遇到類似問題嗎?歡迎評論區討論~
相關數據:https://huggingface.co/datasets/jxm/GPT-oss20b-samples
參考鏈接:
[1]https://x.com/jxmnop/status/1953899426075816164
[2]https://news.ycombinator.com/item?id=44850260
[3]https://x.com/ViepliveeLee/status/1953982402231222763
[4]https://blog.csdn.net/weixin_66401877/article/details/150019363
— 完 —
- 又一高管棄庫克而去!蘋果UI設計負責人轉投Meta2025-12-04
- 萬卡集群要上天?中國硬核企業打造太空超算!2025-11-29
- 學生3年投稿6次被拒,于是吳恩達親手搓了個評審Agent2025-11-25
- 波士頓動力前CTO加盟DeepMind,Gemini要做機器人界的安卓2025-11-25
相關閱讀