1.5B刷新數學代碼SOTA!快手&清華精細化Token管理,LLM推理能力飆升
“怎么學”可能比“學了多少”更重要
Archer團隊 投稿
量子位 | 公眾號 QbitAI
當大模型在數學題和代碼任務里“卷”參數規模時,一支來自快手和清華的團隊給出了不同答案——
他們用1.5B參數的小模型,在多個推理基準上干過了同量級SOTA。
秘密在于給模型的“學習過程”做了精細化管理:讓該記牢的知識穩住,讓該靈活的推理放開。
在多個挑戰性的數學、代碼評測基準上,該團隊提出的Archer方法都展現出了強大的實力。
目前,Archer的代碼已開源,詳細鏈接可見文末。

“兩難”:知識和推理難兼顧
通過預訓練,LLM能記住海量的知識。但要讓這些知識轉化為解決數學題、寫復雜代碼的推理能力,還得靠后續的強化學習(RL)優化。
其中,帶可驗證獎勵的強化學習(RLVR)是當前的主流方法——簡單地說,就是讓模型不斷嘗試解題,通過“是否做對”的反饋調整行為,有點像人類“做題糾錯”。
但問題來了:模型輸出的內容里,有些是“知識型”的(比如“1+1=2”這類事實),有些是“推理型”的(比如“先算括號里,再算乘除”這類邏輯規劃步驟)。
過去的RLVR方法要么“一視同仁”,給所有內容用一樣的訓練信號;要么“粗暴分割”,用梯度屏蔽把兩類內容拆開訓練。
結果往往是:要么知識逐漸變差(比如把公式記錯),要么推理放不開(比如總用老套思路解題)。
快手和清華團隊發現:這兩類內容在模型里其實有明顯特征:
- 低熵Token
- (確定性高):比如“3.14”、“def函數”,對應事實性知識,訓練時不能亂改;
- 高熵Token
- (不確定性高):比如“因此”、“接下來”、“循環條件”,對應邏輯推理,需要多嘗試。
但關鍵在于,這兩類Token在句子里是“綁在一起”的——比如解數學題時,“因為2+3=5(低熵),所以下一步算5×4(高熵)”,拆開會破壞語義邏輯。
Archer:給Token“差異化訓練”
團隊提出的Archer方法,核心是“雙Token約束”——不拆分Token,而是給它們定制不同的訓練規則。
簡單說就是兩步:
1.先給Token“貼標簽”:用熵值分類型
通過計算每個Token的熵值(不確定性),自動區分“知識型”和“推理型”:
- 高熵Token:比如數學推理里的“接下來”、“綜上”,代碼里的“循環”、“判斷”,是邏輯轉折點;
- 低熵Token:比如“123”、“print”,是必須準確的事實性內容。
團隊用“句子級熵統計”替代傳統的“批次級統計”——比如同一道數學題,不同解法的Token熵分布不同,按句子單獨劃分,避免把“關鍵推理Token”誤判成“知識Token”。
2.再給訓練“定規矩”:差異化約束
對貼好標簽的Token,用不同的規則訓練:
- 推理型(高熵)Token:松約束。用更高的裁剪閾值(允許更大幅度調整)和更弱的KL正則(減少對原始策略的依賴),鼓勵模型多嘗試不同推理路徑;
- 知識型(低熵)Token:緊約束。用更低的裁剪閾值和更強的KL正則,讓模型“死死記住”正確知識,避免越訓越錯。
這樣一來,知識和推理既能同步更新,又不互相干擾——就像老師教學生:基礎公式要背牢,解題思路可以大膽試。
從數學到代碼:全面碾壓同量級模型
在最考驗推理能力的數學和代碼任務上,Archer的表現都很出色。
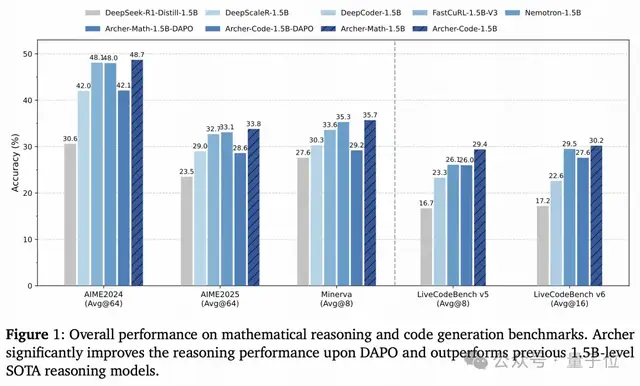
數學推理:解題正確率大幅提升
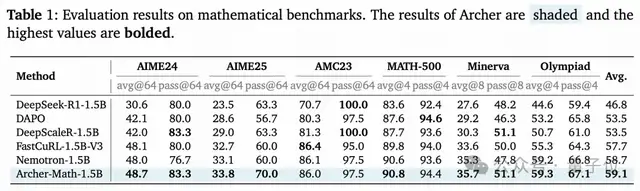
在AIME 2024/2025、Minerva等硬核數學基準上:
- 相比同基座的原始模型,Archer在AIME24上正確率提升18.1%,AIME25提升10.3%;
- 對比當前SOTA方法DAPO,Archer在AIME24上多對6.6%的題,AIME25多對5.2%;
- 1.5B參數的Archer-Math,直接超過了FastCuRL、Nemotron等同量級SOTA模型,平均正確率登頂。
代碼生成:刷題能力顯著增強
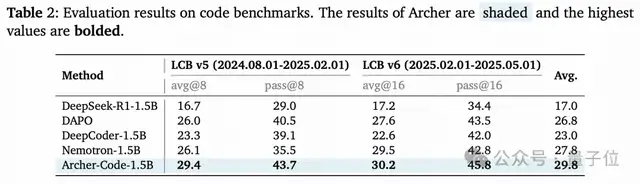
在LiveCodeBench(主流代碼生成基準)v5/v6上:
- 相比DAPO,Archer在v5上正確率提升3.4%,v6提升2.6%;
- 超過了專門優化代碼的DeepCoder-1.5B,成為同量級最佳代碼生成模型之一。

效率方面,Archer只用單階段訓練、1900?H800 GPU小時(對比Nemotron的16000 H100小時),就實現了這些提升。
沒有復雜的多輪訓練,達到了“花小錢辦大事”的效果。
關鍵在“平衡”
Archer的核心洞察是:LLM推理能力不是“死記硬背”或“盲目試錯”,而是知識穩定性和推理探索性的平衡。
團隊通過實驗驗證了這種平衡的重要性:

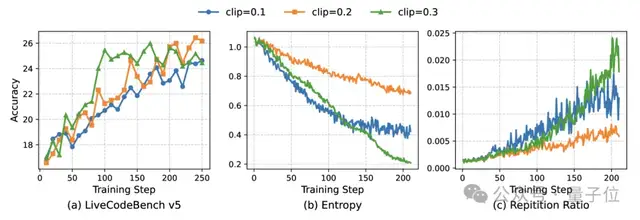
- 若不給低熵Token加約束(KL=0),模型會很快“記混知識”,輸出重復內容,性能崩塌;
- 若給高熵Token加嚴約束(裁剪閾值太小),模型推理“放不開”,學不到新方法;
- 只有讓知識Token“穩”、推理Token“活”,才能既不丟基礎,又能提升邏輯能力。
這種思路也解釋了為什么小模型能逆襲——大模型的參數優勢能堆出更多知識,但如果訓練時“管不好”知識和推理的關系,能力提升反而受限。
Archer用精細化的Token管理,讓小模型的每一個參數都用在刀刃上,學會如何更好的組織使用已有的知識。
論文鏈接:http://arxiv.org/abs/2507.15778
GitHub:https://github.com/wizard-III/ArcherCodeR
- AI芯片獨角獸一年估值翻番!放話“三年超英偉達”,最新融資53億2025-09-18
- 李飛飛發布世界模型新成果:一個提示,生成無限3D世界2025-09-17
- 奧特曼“續命”大計:押注讓大腦變年輕的藥物,預計年底臨床試驗2025-09-16
- DeepMind哈薩比斯最新認知都在這里了2025-09-15