
挑戰(zhàn)強化學(xué)習(xí)后訓(xùn)練霸權(quán)!全新無監(jiān)督方法僅需1條數(shù)據(jù)+10步優(yōu)化
無需標注、拋棄復(fù)雜獎勵設(shè)計
Ubiquant團隊 投稿
量子位 | 公眾號 QbitAI
無需標注數(shù)據(jù)、無需繁瑣獎勵設(shè)計,只用10步就能見效——「熵最小化」或許比強化學(xué)習(xí)更適合大語言模型快速升級。
強化學(xué)習(xí)(RL)近年來在大語言模型(LLM)的微調(diào)中大獲成功,但高昂的數(shù)據(jù)標注成本、復(fù)雜的獎勵設(shè)計和漫長的訓(xùn)練周期,成為制約RL進一步應(yīng)用的瓶頸。
Ubiquant研究團隊提出了一種極為簡單有效的無監(jiān)督方法——One Shot熵最小化(Entropy Minimization,EM),僅用一條無標簽數(shù)據(jù),訓(xùn)練10步內(nèi)即可顯著提升LLM性能,甚至超過使用成千上萬數(shù)據(jù)的RL方法。

一、從RL到EM:LLM微調(diào)的困境與新思路
當前,大語言模型(LLM)在經(jīng)過海量數(shù)據(jù)預(yù)訓(xùn)練后,展現(xiàn)出了驚人的通用能力。然而,要讓模型在特定、復(fù)雜的推理任務(wù)(例如數(shù)學(xué)、物理或編程)上達到頂尖水平,后訓(xùn)練(post-training)主流后訓(xùn)練方法是采用強化學(xué)習(xí)(RL),特別是結(jié)合可驗證獎勵的強化學(xué)習(xí)(RLVR)。
盡管基于RL的微調(diào)在提升模型性能上取得了顯著進展,但其過程卻面臨著一系列明顯的弊端,使得這種方法成本巨大且過程繁瑣。
RL,特別是RLVR,對大規(guī)模高質(zhì)量標注數(shù)據(jù)的依賴性極強。其次,RL方法的成功在很大程度上取決于復(fù)雜且精心的獎勵函數(shù)設(shè)計。
這需要專家知識來最大化優(yōu)勢信號并防止模型“獎勵作弊”。此外,許多常用的RL算法(如PPO)需要額外的獎勵模型,這不僅增加了算法復(fù)雜性,并且大量的大量的訓(xùn)練步驟和漫長的采樣過程帶來了巨額的計算開銷。
相較之下,熵最小化(EM)提出了一種全新的思路。EM的核心理念是無需任何標注數(shù)據(jù)或外部監(jiān)督來訓(xùn)練模型。它僅依賴模型自身預(yù)測分布的熵(entropy)進行優(yōu)化。
具體而言,EM訓(xùn)練模型將其概率質(zhì)量更多地集中在其最自信的輸出上。EM背后的核心思想基于一個關(guān)鍵假設(shè)和一個簡單直覺:如果一個模型本身足夠有能力,那么當它對其預(yù)測結(jié)果更“自信”時,它也更有可能是正確的。
換句話說,正確答案通常比錯誤答案具有更低的熵值。通過優(yōu)化目標來降低模型生成序列的熵,EM促使模型變得更加“自信”,從而強化其在預(yù)訓(xùn)練階段已經(jīng)獲得的能力
二、熵最小化(EM)到底怎么做?
具體來說,熵最小化方法的核心公式為:
設(shè)表示一個預(yù)訓(xùn)練自回歸語言模型pθ的詞匯表,該模型由參數(shù)θ定義。給定一個輸入提示x(例如一個問題或問題描述),模型根據(jù)其當前策略自回歸地生成一個響應(yīng)序列 y=(y1,y2,…,yT)

其中T是生成序列的長度。核心思想是通過在每一步生成時最小化標記級別的熵,來減少模型對其自身預(yù)測的不確定性。時間步t的條件熵定義為:
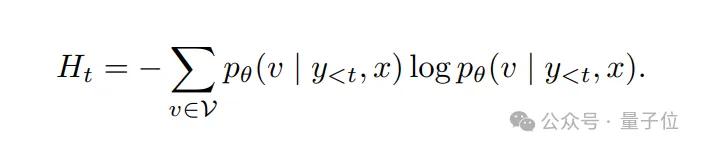
單個輸入x的總體EM損失由以下公式給出:

簡單而言,這個損失函數(shù)鼓勵模型提高對自身預(yù)測的信心,無需依賴外部監(jiān)督信號或獎勵函數(shù)。由于其完全依賴于模型本身而非外部信號,和預(yù)訓(xùn)練目標完全兼容,在有效簡化優(yōu)化過程的同時可能帶來潛在對于模型內(nèi)一致性的破壞。
三、為何只用一條示例就足夠?
熵最小化的成功高度依賴示例的選擇。熵最小化(EM)依賴于模型的預(yù)測不確定性可以作為有意義的訓(xùn)練信號。
然而,并非所有輸入提示在這方面都同樣具有信息量。
因而研究者采用了一種基于模型表現(xiàn)方差的示例篩選方法:通過計算模型多次生成結(jié)果的準確性方差,挑選那些模型表現(xiàn)不穩(wěn)定的示例進行訓(xùn)練。
這種方差量化了模型對給定輸入的預(yù)測不一致性。低方差意味著要么對正確性有高度信心(接近完美的成功),要么對失敗有高度信心(完全錯誤)。
相反,表現(xiàn)方差大的示例更能有效驅(qū)動模型降低熵值、明確決策邊界。這也是為何只用一條高質(zhì)量示例,就能快速推動模型的推理性能。
研究人員使用的唯一一條樣本如下:
Problem: The pressure P exerted by wind?on?a sail varies jointly as the area A of the sail and the cube of the wind’s velocity V. When the velocity is?8?miles per hour, the pressure?on?a sail of?2?square feet is?4?pounds. Find the wind velocity when the pressure?on?4?square feet of sail is?32?pounds.
Solution:?12.8四、實驗結(jié)果:以小博大,性能媲美甚至超越RL
研究人員在多個數(shù)學(xué)推理任務(wù)上測試了熵最小化(EM)的效果。結(jié)果顯示,僅一條示例、10步訓(xùn)練,EM方法即大幅提高了Qwen2.5-Math-7B的性能:

- MATH500測試集:
- 準確率從53%提升到78.8%,提升25.8個百分點;
- Minerva Math測試集:
- 準確率從11%提升到35.3%,提升24.3個百分點;
- AMC23測試集:
- 準確率從44.1%提升到70.3%,提升26.2個百分點。
更令人矚目的是,即使只使用一個示例和極少的訓(xùn)練步驟(僅僅10步),EM方法極大地縮小了Qwen2.5-Math-7B與Prime-Zero-7B和RLVR-GRPO等先進的基于RL的模型之間的差距。
特別是在AMC23基準測試中,經(jīng)過EM增強的Qwen2.5-Math-7B達到了具有競爭力的70.3分,逼近領(lǐng)先的RL模型這些結(jié)果清晰地表明,熵最小化(EM),盡管比典型的強化學(xué)習(xí)方法更簡單、數(shù)據(jù)效率更高,但在增強基礎(chǔ)語言模型在數(shù)學(xué)推理任務(wù)上的性能方面,具有巨大的潛力。那么為什么熵最小化能這么有效果呢?熵在模型的訓(xùn)練和推理過程中起到什么樣的作用呢?
五、EM vs. RL:深入分析“置信度”與“Logits偏移”
大語言模型在生成每個token時,會先產(chǎn)生一組未經(jīng)歸一化的分數(shù),稱為Logits。這些Logits隨后通過 Softmax 函數(shù)轉(zhuǎn)換為概率分布,決定了下一個token的選擇。
因此,Logits的分布形態(tài)直接反映了模型對其預(yù)測的“置信度”和對不同token的偏好。這項研究通過對模型Logits分布的深入分析發(fā)現(xiàn),熵最小化(EM)和強化學(xué)習(xí)(RL)對模型內(nèi)部置信度的影響方向截然相反。
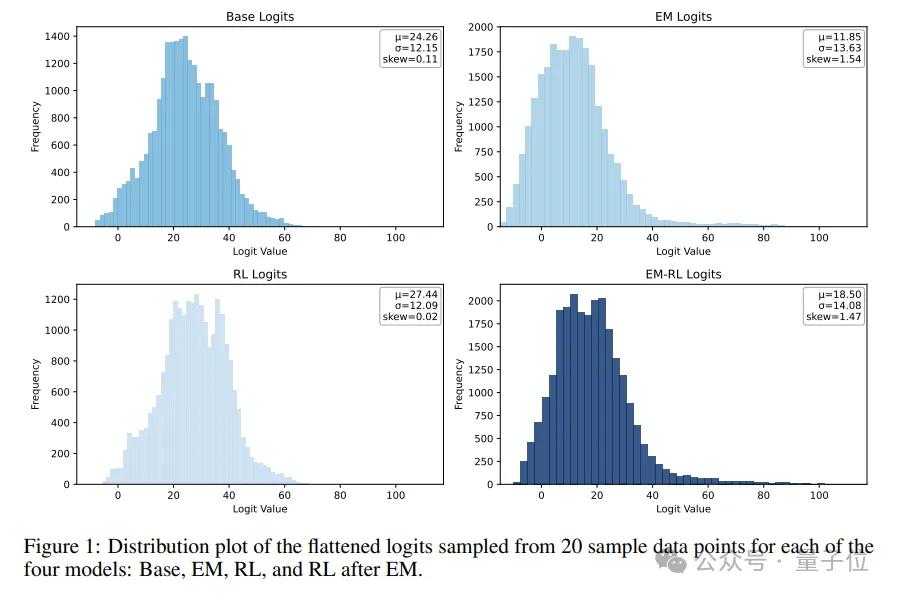
EM:向右偏移,強化自身自信
研究表明,經(jīng)過EM訓(xùn)練的模型,其Logits分布會顯著地向右偏移。這種右移意味著模型在生成過程中,會反復(fù)強化自身的預(yù)測置信度。模型將更多的概率質(zhì)量集中在少數(shù)它認為“確定”的token上,使得原本高概率的區(qū)域進一步向高分區(qū)間擴展。
直觀來說,這讓模型對其最看好的答案變得更加“自信”。
在生成和采樣時,這種向右的 Logits 偏移是有益的。它增加了高概率的候選 token 數(shù)量,擴展了模型能夠遵循的“高概率路徑”,從而潛在地增強了模型的整體生成能力。
實驗中,EM 訓(xùn)練后的模型在評估時表現(xiàn)出與采樣溫度的相反趨勢:隨著溫度升高,性能下降。這可以用貪婪解碼(即總是選擇概率最高的token)來解釋——因為 EM 訓(xùn)練將概率質(zhì)量高度集中在少數(shù)確定性token上,貪婪解碼在這種分布下變得非常有效。
RL:向左偏移,受真實信號引導(dǎo)
與EM不同,經(jīng)過RL訓(xùn)練的模型則表現(xiàn)出Logits分布向左偏移的趨勢。研究者推測,這是受到訓(xùn)練過程中“真實”(ground-truth)信號的影響2。
RL通過外部獎勵函數(shù)來調(diào)整模型的行為,它會懲罰那些模型預(yù)測概率很高但與地面真實不符的token。
通過對這些高概率但不正確的token進行降權(quán)(reranking),RL降低了它們的排序,從而導(dǎo)致整體Logits分布向左偏移。RL 訓(xùn)練后,即使經(jīng)過 reranking,這些原本低概率的token往往只占據(jù)概率分布中的中間位置,需要更高的采樣溫度才能被選中。
因此,RL訓(xùn)練的模型表現(xiàn)出與EM相反的趨勢:性能隨著采樣溫度的升高而提升。
雖然RL的目標是提升模型性能,但其導(dǎo)致的Logits左移被認為對大語言模型的生成過程有害,因為它減少了采樣時的高概率路徑數(shù)量,可能會削弱模型的整體性能。
這種Logits偏移的差異,通過分析Logits分布的偏度(Skewness)得以量化。
EM訓(xùn)練顯著提高了Logits分布的偏度,呈現(xiàn)右偏;而RL訓(xùn)練則顯著降低了偏度,甚至導(dǎo)致左偏。即使在EM后再進行RL訓(xùn)練,Logits分布的偏度也會從EM后的高值有所下降,遵循RL的趨勢。
這樣的差異和塑造了EM和RL完全不同的推理采樣策略。

在評估階段,隨著采樣溫度的升高,EM模型在四個數(shù)學(xué)推理基準測試上的平均表現(xiàn)持續(xù)下降。
這一趨勢與上圖中展示的經(jīng)過強化學(xué)習(xí)(RL)訓(xùn)練的模型形成鮮明對比,后者在更高的采樣溫度下往往表現(xiàn)更佳。EM更像是一個分布塑造工具(distribution shaping tool),通過強化模型自身的內(nèi)在一致性來提升置信度,從而重塑了現(xiàn)有知識的分布。
六、“過度自信”的陷阱與隨機性
研究也揭示了這種高效性背后隱藏的“陷阱”——即“過度自信”現(xiàn)象。
訓(xùn)練初期,EM訓(xùn)練損失迅速下降,模型的數(shù)學(xué)推理性能也隨之提升然而,大約在訓(xùn)練進行到10步左右時,模型的性能達到了頂峰。令人意外的是,即使EM訓(xùn)練損失繼續(xù)下降,模型的數(shù)學(xué)推理性能反而開始下降。
這種“過度自信”被認為是由于持續(xù)的EM訓(xùn)練過度放大了模型在推理過程中對其自身生成token的置信度。持續(xù)的EM訓(xùn)練可能會過度強化模型已有的先驗偏差,導(dǎo)致輸出結(jié)果過度集中于狹窄、過度自信的token分布,從而加劇算法偏差并導(dǎo)致輸出顯著偏離正確路徑,最終損害了模型的實際推理性能。

熵最小化的不穩(wěn)定性和過度自信的損害也體現(xiàn)在訓(xùn)練時的溫度上。經(jīng)過EM訓(xùn)練的模型在四個數(shù)學(xué)推理基準上的平均性能隨著生成溫度的升高總體呈現(xiàn)上升趨勢。
平均性能的最大值最初增加,隨后在溫度約為0.5時開始下降。較高的溫度帶來更好的平均推理能力,而適中的溫度(如0.5)則導(dǎo)致更大的性能波動,從而為更高的峰值性能創(chuàng)造了機會。
EM訓(xùn)練同時展現(xiàn)出顯著的隨機性,即便設(shè)置完全相同,四個數(shù)學(xué)推理基準測試的平均得分也會因種子不同而相差高達兩倍。

七、EM適合哪些場景?
研究表明,熵最小化(EM)尤其適合:
尚未進行大量RL調(diào)優(yōu)的基礎(chǔ)模型或僅經(jīng)過SFT的模型:
研究在多個不同的基礎(chǔ)模型上評估了One-shot EM的效果,結(jié)果表明,僅通過單個示例和極少的訓(xùn)練步數(shù),EM能夠持續(xù)且顯著地提升這些模型在數(shù)學(xué)推理基準測試上的性能。
然而,研究也發(fā)現(xiàn),當應(yīng)用于已經(jīng)過大量RL廣泛微調(diào)的模型(如 SimpleRL-Zoo)時,One-shot EM反而可能導(dǎo)致性能下降5。這與在RL之后應(yīng)用EM可能鎖定狹窄、過度自信的輸出模式并損害性能的發(fā)現(xiàn)一致。
需要快速部署、沒有充足標注數(shù)據(jù)或資源有限的場景。
EM的核心優(yōu)勢在于其極高的效率和對數(shù)據(jù)的極低需求,研究發(fā)現(xiàn),One-shot EM實際上比Multi-shot EM表現(xiàn)出更好的性能和更強的泛化能力。
盡管Multi-shot使用了更多的示例,但One-shot EM通過單個示例實現(xiàn)了更穩(wěn)定和細致的優(yōu)化。有效減少了樣本偏差并縮小了輸出方差。這進一步強化了 EM 在數(shù)據(jù)極度稀缺場景下的吸引力。
無代價能力增強:
熵最小化(EM)可以作為現(xiàn)有后訓(xùn)練范式的有力補充甚至起點。將EM 應(yīng)用在RL之前能夠帶來有效增益,使其成為RL的有效“啟用基礎(chǔ)”。
EM 通過其獨特的Logits 右偏移效應(yīng)提升模型的自信度,增強模型的推理能力,并可能促進后續(xù) RL 訓(xùn)練的更快收斂和更穩(wěn)定優(yōu)化。
對于已經(jīng)深度調(diào)優(yōu)過的RL模型,再使用EM反而可能帶來性能的下降。
八、行業(yè)前景與未來研究
One-shot EM的成功,不僅在于其驚人的數(shù)據(jù)和計算效率,還在于它為LLM后訓(xùn)練提供了一種完全無監(jiān)督的、可落地的替代方案,它不需要人工標注數(shù)據(jù),不需要構(gòu)建復(fù)雜的獎勵模型,極大地降低了后訓(xùn)練的門檻和成本。這項研究同樣為未來的探索打開了廣闊的空間:
訓(xùn)練穩(wěn)定性與魯棒性:
One-shot EM雖然高效,但也伴隨超參數(shù)敏感性和一定的訓(xùn)練不穩(wěn)定性。研究發(fā)現(xiàn),持續(xù)的EM訓(xùn)練可能會導(dǎo)致模型“過度自信”,反而損害性能。未來的工作需要探索早停標準或自適應(yīng)調(diào)度機制,以及減少訓(xùn)練的隨機性,以進一步穩(wěn)定和提升EM的效果。
泛化能力與跨領(lǐng)域應(yīng)用:
EM在數(shù)學(xué)推理任務(wù)上表現(xiàn)出色,但它能否泛化到對話、摘要、代碼生成等其他領(lǐng)域?這需要進一步的實驗驗證。同時,當前EM在Token級別操作,未來的研究可以探索在序列或語義單元上應(yīng)用結(jié)構(gòu)化熵,或引入任務(wù)特定先驗知識和自適應(yīng)熵正則化,以釋放更多潛力。
與現(xiàn)有技術(shù)的融合:
EM作為一種分布塑造工具,與SFT、RLHF等現(xiàn)有后訓(xùn)練技術(shù)概念上正交。研究發(fā)現(xiàn),在RL之前應(yīng)用EM可以帶來有益的對數(shù)分布偏移。
未來的工作可以系統(tǒng)地研究不同的EM與RL結(jié)合的時間表、課程策略及其相互作用,探索構(gòu)建更強大混合方法的可能性。EM甚至可以作為SFT或RLHF過程中的一種正則化策略,或作為現(xiàn)有模型的“信心壓縮”層。
研究人員對置信度校準的深入研究結(jié)果還暗示,EM通過強化高概率推理路徑來增強模型的置信度。
這表明EM可能是一種輕量級的信心校準方法。未來的研究需要開發(fā)更精確的評估協(xié)議來量化EM的校準效應(yīng),深入理解其背后的機制。
(本文內(nèi)容參考自論文《One-shot Entropy Minimization》,詳細實驗與數(shù)據(jù)參見原文。)
— 完 —
相關(guān)閱讀


人形AI捉迷藏驚煞網(wǎng)友:飛檐走壁純靠自學(xué),表情豐富還會合作,姚班學(xué)霸吳翼參與
網(wǎng)友:OpenAI是一家動畫公司吧








