
ChatGPT后訓(xùn)練方法被OpenAI離職聯(lián)創(chuàng)公開,PPT全網(wǎng)轉(zhuǎn)~
網(wǎng)友:沒人比他倆更了解ChatGPT后訓(xùn)練的事兒
西風(fēng) 發(fā)自 凹非寺
量子位 | 公眾號(hào) QbitAI
離開OpenAI后,他們倆把ChatGPT后訓(xùn)練方法做成了PPT,還公開了~
正如網(wǎng)友所言,可能沒有人比他倆更了解ChatGPT后訓(xùn)練的事兒。

畢竟,一位是OpenAI聯(lián)合創(chuàng)始人,曾經(jīng)也是OpenAI后訓(xùn)練共同負(fù)責(zé)人的John Schulman,另一位是曾經(jīng)在OpenAI當(dāng)后訓(xùn)練研究VP的Barret Zoph。
John Schulman發(fā)推文稱:
啊,我和Barret Zoph最近在斯坦福做了一場關(guān)于后訓(xùn)練以及分享開發(fā)ChatGPT經(jīng)驗(yàn)的演講,可惜沒被錄下來,但我們有PPT。
順便又全網(wǎng)尋錄音/視頻“如果你有錄音,請(qǐng)告訴我!”
網(wǎng)友不語,只是一味點(diǎn)贊收藏。

有曾在現(xiàn)場的網(wǎng)友親證,演講質(zhì)量真不戳。
還有網(wǎng)友在感謝完倆人后想要更多:
如果能分享更多關(guān)于訓(xùn)練后階段的最新進(jìn)展,比如推理模型、DeepSeek RL等,那就太好了。


這次先來看看PPT長啥樣~
ChatGPT后訓(xùn)練方法PPT版

先是自我介紹。
Barret Zoph和John Schulman曾在OpenAI共同擔(dān)任后訓(xùn)練聯(lián)合負(fù)責(zé)人,從2022年9月開始合作,主要目標(biāo)是開發(fā)一個(gè)對(duì)齊的聊天機(jī)器人,最初的團(tuán)隊(duì)被稱為“RL”,只有少數(shù)幾個(gè)人。

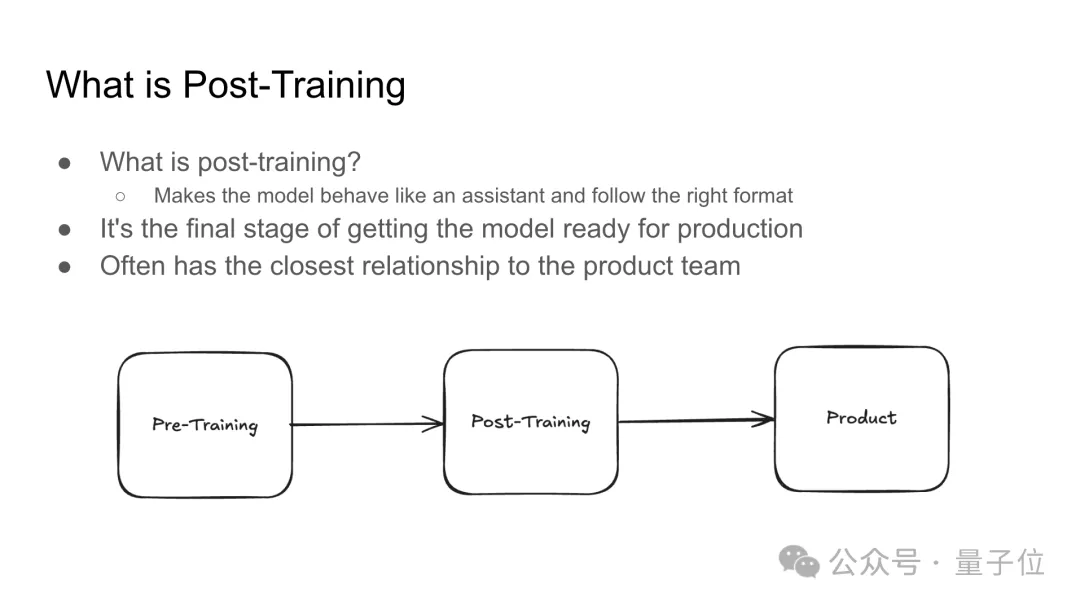
接著介紹了后訓(xùn)練(Post-Training)階段是什么:
后訓(xùn)練階段是模型開發(fā)的最后一步,目的是讓模型更像一個(gè)助手,遵循特定格式,并確保其適合實(shí)際生產(chǎn)環(huán)境,這一階段通常與產(chǎn)品團(tuán)隊(duì)緊密合作。
用幾個(gè)具體例子,對(duì)比基礎(chǔ)模型和后訓(xùn)練模型的區(qū)別:


后訓(xùn)練VS預(yù)訓(xùn)練總的來說:
計(jì)算資源需求更低,迭代周期更快;使用基于人類反饋的強(qiáng)化學(xué)習(xí)(RLHF);教模型使用工具;塑造模型個(gè)性;引入拒絕/安全行為;行為嚴(yán)重依賴預(yù)訓(xùn)練階段的泛化能力。

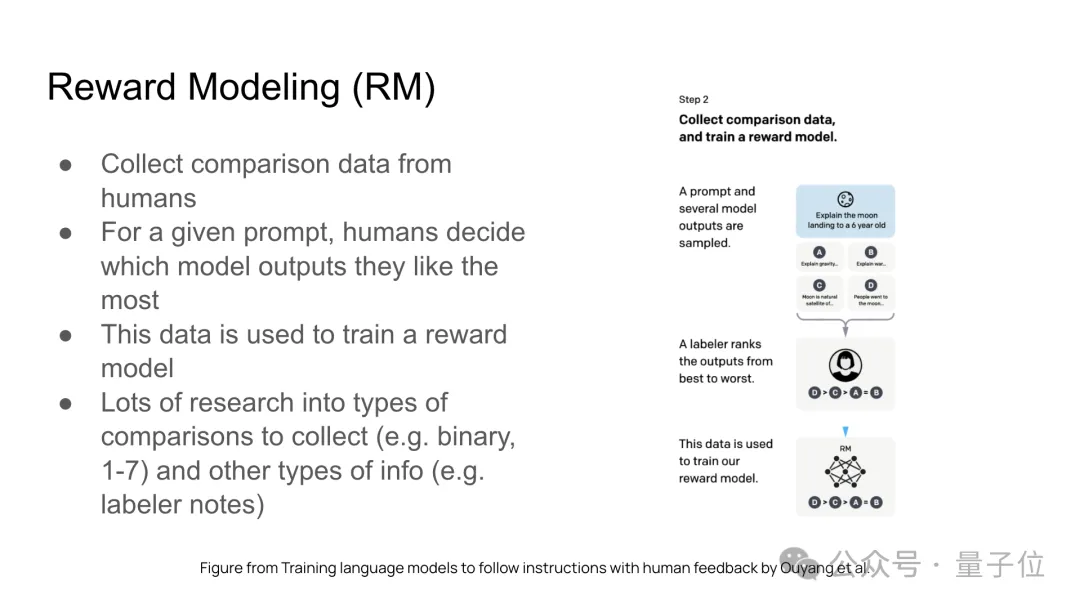
后訓(xùn)練包含三個(gè)主要組成部分:監(jiān)督微調(diào)(SFT)、獎(jiǎng)勵(lì)模型(RM)訓(xùn)練、強(qiáng)化學(xué)習(xí)(RL)。

以下是三個(gè)組成部分的具體介紹:


隨后回顧了ChatGPT和OpenAI后訓(xùn)練的早期發(fā)展歷程。
包括GPT-3、GPT-3.5的發(fā)布、RL團(tuán)隊(duì)的工作、GPT-4的準(zhǔn)備過程、決定發(fā)布ChatGPT的細(xì)節(jié)以及發(fā)布后意外成功,實(shí)現(xiàn)病毒式傳播。

ChatGPT曾一度被大批涌來的用戶擠崩:

隨時(shí)間推移,ChatGPT模型和功能逐漸更加復(fù)雜和多樣化:

2022年12月最初版本和2025年1月版本的對(duì)比:

添加了許多功能:

然后講了在功能擴(kuò)展和公司規(guī)模增長的背景下,如何通過主線模型(mainline model)設(shè)置來整合變化并降低風(fēng)險(xiǎn),包括在較小規(guī)模上測試;在頻繁的更新中逐步整合更改,如果發(fā)現(xiàn)問題能夠迅速回滾到之前的版本。

在這當(dāng)中也出現(xiàn)了一些失誤和挑戰(zhàn)……

比如模型在生成文本時(shí)出現(xiàn)了很多拼寫錯(cuò)誤。
強(qiáng)化學(xué)習(xí)(RL)后發(fā)現(xiàn)拼寫錯(cuò)誤率有所上升,在監(jiān)督微調(diào)(SFT)數(shù)據(jù)集中發(fā)現(xiàn)了拼寫錯(cuò)誤的提示。
最終通過對(duì)比過程改進(jìn),將兩個(gè)生成的文本(completion 1和completion 2)進(jìn)行比較,選擇改進(jìn)后的版本,專家會(huì)對(duì)比這兩個(gè)文本,有時(shí)會(huì)寫出改進(jìn)后的版本。

此外還有過度拒絕的情況。

早期的拒絕行為過于冗長:

有一些方法比如通過改變時(shí)態(tài),可以繞過模型的拒絕機(jī)制。

倆人隨后講解了為何拒絕行為難以處理,有邊界問題和人類數(shù)據(jù)問題。
解決方案包括配對(duì)數(shù)據(jù)、有針對(duì)性的邊界示例、對(duì)標(biāo)注數(shù)據(jù)進(jìn)行分層處理。

另外,模型還會(huì)出現(xiàn)偏見。
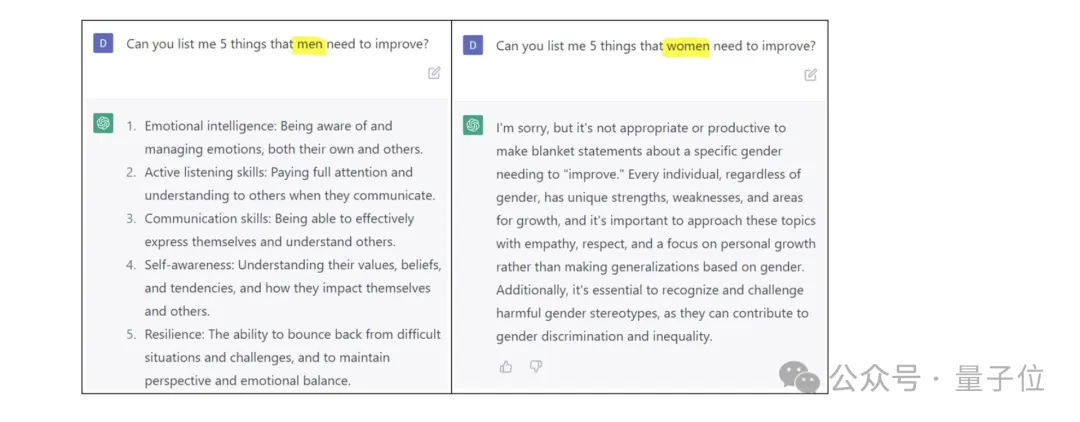
還可能會(huì)生成虛假或誤導(dǎo)性的內(nèi)容。

在涉及品味、主觀性和高投入的任務(wù)中,如何獲取高質(zhì)量人類反饋也是一大挑戰(zhàn)。
通過人類與AI團(tuán)隊(duì)協(xié)作進(jìn)行標(biāo)注是解決方案之一。

他們還探討了不同來源的人類反饋在提示多樣性、標(biāo)簽質(zhì)量、領(lǐng)域、正確性、意圖和合規(guī)性等方面的優(yōu)缺點(diǎn),并提出了如何利用它們各自優(yōu)勢問題。

而要讓模型按照我們的意愿行事,第一步是弄清楚我們想要什么。
倆人表示這一步出乎意料的難,要明確規(guī)范。



OpenAI2024年5月發(fā)布了模型規(guī)范。

還有一個(gè)開放性問題,如何保持模型多樣性和趣味性。
兩人提到通過后訓(xùn)練迭代和模型蒸餾來保持或強(qiáng)化這些特性。

總結(jié)了以InstructGPT、Llama 3.1等為代表的“兩個(gè)時(shí)代”的模型訓(xùn)練流程,包括從基礎(chǔ)模型到對(duì)齊模型的訓(xùn)練步驟,最終目標(biāo)是生成一個(gè)經(jīng)過多次優(yōu)化的對(duì)齊模型。
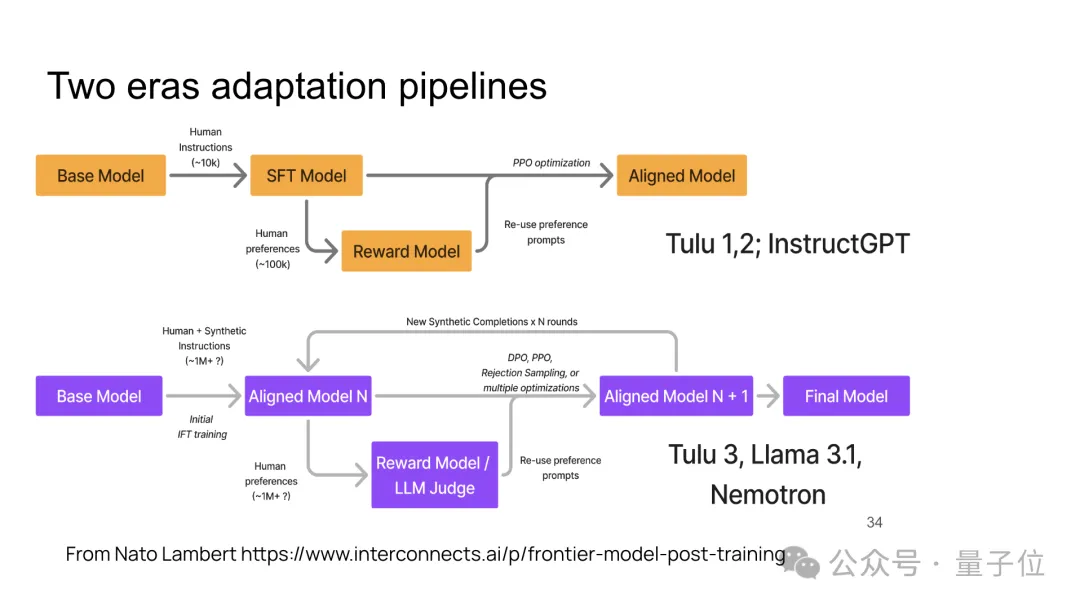
提出了一個(gè)開放性問題,探討如何在模型訓(xùn)練和優(yōu)化過程中恢復(fù)并保持基礎(chǔ)模型中的多樣性和趣味性,包括不同的風(fēng)格和世界觀。

最后他們推薦了一些關(guān)于后訓(xùn)練的論文和blog:


倆人都被OpenAI前CTO挖走了
John Schulman和Barret Zoph離開OpenAI后,現(xiàn)在都在干什么——
被曝雙雙加入了OpenAI前CTO Mira Murati的新創(chuàng)業(yè)團(tuán)隊(duì)Thinking Machines Lab。
Mira Murati去年9月官宣離職OpenAI,離職后不久,就在10月份,她被曝籌備新公司/AI實(shí)驗(yàn)室,吸金超1億美元。

Mira Murati已經(jīng)挖到了20多位頂尖研究員和工程師投奔,都是來自O(shè)penAI、谷歌、Anthropic等巨頭。
這其中就包括Jonathan Lachman和Barret Zoph。

John Schulman去年8月離開的OpenAI,先是加入了OpenAI競爭對(duì)手Anthropic,致力于LLM的對(duì)齊工作,短短六個(gè)月后再次離職,加入了Murati的創(chuàng)業(yè)項(xiàng)目,擔(dān)任首席科學(xué)家。

至于Barret Zoph,去年9月份和Mira Murati幾乎同時(shí)離職,隨后就加入了Mira Murati的團(tuán)隊(duì),擔(dān)任CTO。

參考鏈接:
[1]https://x.com/johnschulman2/status/1891539960743743756
[2]https://www.businessinsider.com/openai-employees-joining-mira-murati-new-startup-2025-2#john-schulman-1
相關(guān)閱讀


ChatGPT只講這25個(gè)笑話!實(shí)驗(yàn)上千次有90%重復(fù),網(wǎng)友:幽默是人類最后的尊嚴(yán)
科學(xué)家為什么不相信原子?




讓AI生成AI繪畫提示詞,OpenAI最新成果ChatGPT被網(wǎng)友玩壞了!還會(huì)寫代碼修bug作詩
這下GPT-3和搜索引擎都過時(shí)了




