
什么會影響大模型安全?NeurIPS’24新研究提出大模型越獄攻擊新基準與評估體系
不僅專注于攻擊,還深入探討了越獄評估
USAIL團隊 投稿
量子位 | 公眾號 QbitAI
全新大語言模型越獄攻擊基準與評估體系來了。
來自香港科技大學(Guangzhou)USAIL研究團隊,從攻擊者和防御者的角度探討了什么因素會影響大模型的安全。
提出攻擊分析系統性框架JailTrackBench。

JailTrackBench研究重點分析了不同攻擊配置對LLMs性能的影響,包括攻擊者的能力、預算、對抗性后綴長度,以及模型的大小、安全對齊情況、系統提示和模板類型。
其研究成果《Bag of Tricks: Benchmarking of Jailbreak Attacks on LLMs》現已被NeurIPS D&B 2024接收。
此外,為了全面解決大語言模型的越獄問題,USAIL團隊不僅專注于攻擊,還深入探討了越獄評估這一核心問題。
越獄分析JailTrackBench
近年來,隨著人工智能的迅速發展,尤其是大語言模型(LLMs)的廣泛應用,保障模型的安全性并防止其被惡意利用,已成為一個重要的議題。越獄攻擊通過惡意指令誘導模型生成有害或不道德的內容,對模型的安全性和可靠性構成了嚴峻挑戰。
這種攻擊與防御的博弈,極大地推動了大模型安全性的提升。
在這一背景下,香港科技大學(Guangzhou)USAIL研究團隊從攻擊者和防御者的角度,探討了影響大模型安全性的關鍵因素。

盡管已有研究揭示了多種越獄攻擊的威脅,現有的評估方法往往過于片面,無法全面涵蓋攻擊與防御兩方面的核心因素。
為此,團隊提出了JailTrackBench,一個全面涵蓋越獄攻擊各個方面的系統性基準測試框架,旨在為研究人員提供一個標準化、全面的評估工具。
 △圖1 JailTrackBench框架
△圖1 JailTrackBench框架通過對七種具有代表性的越獄攻擊和六種防御方法的320項實驗,使用50,000 GPU小時,團隊以標準化的方式評估了這些攻擊方法的效果。
目標模型層面
模型大小(Model Size):
實驗(如圖2所示)中選擇了不同規模的模型(如Llama-7B、Llama-13B、Llama-70B,Qwen1.5-14B等)進行對比,探討模型規模對越獄攻擊的防御能力是否有顯著影響。
實驗結果表明,模型的魯棒性并不與其規模成正比,較大的模型并不總是比較小的模型更具防御能力。
 △圖2 模型大小與魯棒性的關系
△圖2 模型大小與魯棒性的關系安全對齊情況(Safety Alignment):
模型的安全能力會被后續的大模型微調所影響。
實驗表明(如圖3所示),經過領域類的微調(fine-tuning)大模型,其安全能力會降低,相比之前沒有微調的模型則更容易受到攻擊。
 △圖3 安全對齊情況與模型魯棒性
△圖3 安全對齊情況與模型魯棒性系統提示(System Prompt):
實驗(如圖4所示)還評估了系統提示(如包含安全提示的系統消息)對模型安全性的影響。結果顯示,包含安全提示的系統消息能夠顯著增強模型的安全性,減少攻擊成功率。
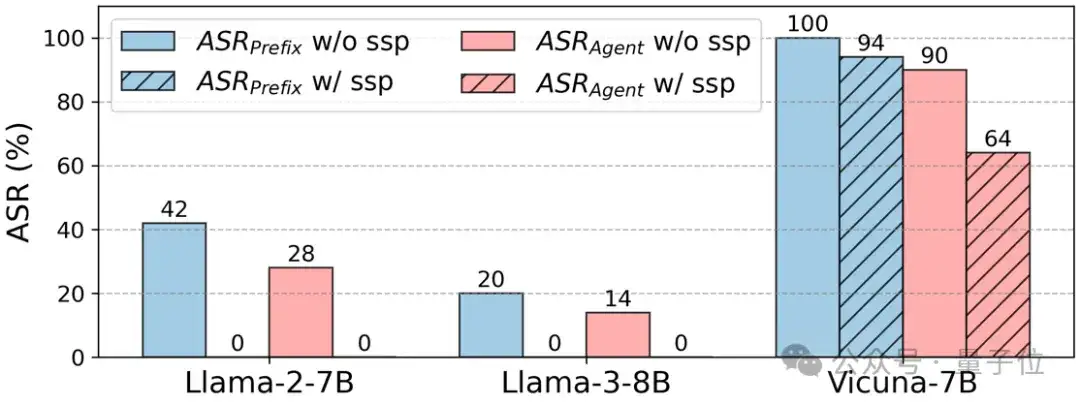 △圖表 4 系統提示與模型類型
△圖表 4 系統提示與模型類型模板類型(Template Type):
實驗(如圖5所示)測試了不同提示模板(如零樣本提示與默認提示)對越獄攻擊成功率的影響。結果顯示,使用默認提示的模型比使用零樣本提示的模型更加安全。
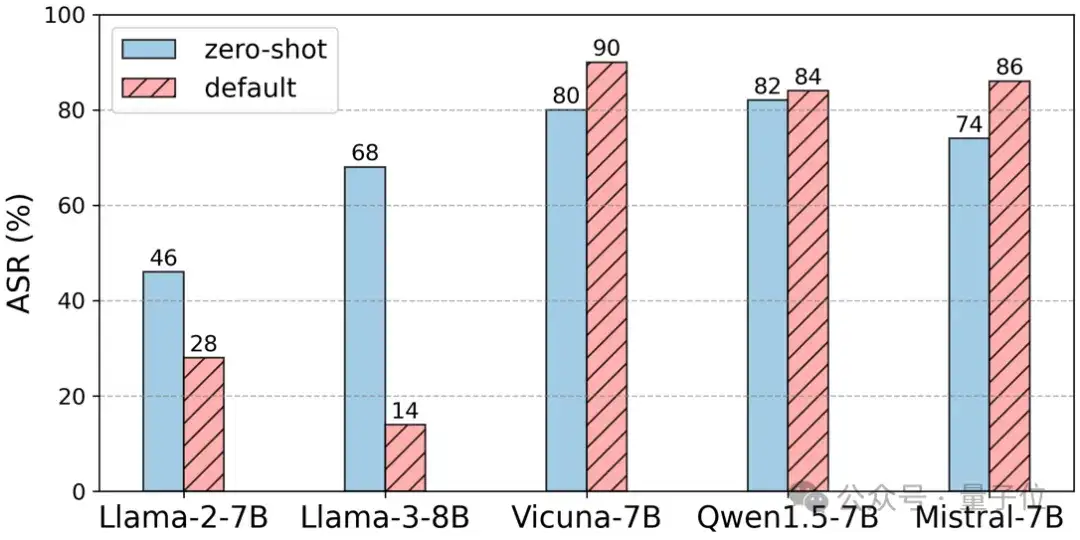 △圖5 模版類型與模型魯棒
△圖5 模版類型與模型魯棒攻擊者層面
攻擊者能力(Attacker Ability):
攻擊者(如圖6所示)使用不同的模型(如GPT-3.5、GPT-4、Vicuna-13B等)來生成對抗性提示,實驗評估了不同攻擊者模型能力對越獄攻擊成功率的影響。結果表明,攻擊者模型越強,越獄攻擊的成功率越高。
 △圖6 攻擊者能力與攻擊效果
△圖6 攻擊者能力與攻擊效果對抗性后綴長度(Adversarial Suffix Length):
在針對令牌級別的越獄攻擊中,實驗(如圖7所示)通過調整對抗性后綴的長度(如10、20、30等)來評估其對攻擊成功率的影響。結果表明,較長的對抗性后綴通常能提高攻擊成功率,但超過一定長度后效果趨于平穩。
 △圖7 對抗性后綴長度與攻擊效果
△圖7 對抗性后綴長度與攻擊效果攻擊者預算(Attacker Budget):
實驗(如圖8和9所示)探討了攻擊者可以提交的查詢次數對攻擊效果的影響。實驗表明,對于令牌級別的攻擊,攻擊預算越大,攻擊成功率越高;而對于提示級別的攻擊,預算的影響則較為有限。
 △圖8 指令級別攻擊的預算
△圖8 指令級別攻擊的預算 △圖9 提示級別攻擊的預算
△圖9 提示級別攻擊的預算攻擊意圖(Attack Intention):
實驗(如圖10所示)設計了多種不同的攻擊意圖(如隱私侵犯、惡意軟件等)來評估其對攻擊成功率的影響。結果表明,不同的攻擊意圖會顯著影響攻擊的成功率,某些攻擊意圖(如經濟損害)更容易成功,而其他意圖(如隱私侵犯)則較難得逞。
 △圖10 攻擊者意圖
△圖10 攻擊者意圖通過對一些不易察覺的設置進行簡單調整(見表1),包括攻擊者和目標模型,研究發現大模型越獄攻擊的成功率可以從0%飆升至驚人的90%(如圖11所示)。這些設置涵蓋了多個關鍵因素,如目標模型的規模、安全對齊方式、系統提示的使用,以及攻擊者的能力和攻擊預算。
 △表格1:不同技巧組合的配置,從弱到強(weak to strong)
△表格1:不同技巧組合的配置,從弱到強(weak to strong) △圖11 不同技巧組合對越獄攻擊成功率的顯著影響
△圖11 不同技巧組合對越獄攻擊成功率的顯著影響越獄評估JAILJUDGE
越獄評估依賴于對模型輸出內容的有害性進行分析,這一任務復雜且充滿不確定性(見圖12)。因此,迫切需要一種系統化的評估方法,幫助研究者和開發者深入了解模型的脆弱性,并持續優化其防御能力。
JAILJUDGE,在此背景下應運而生的。

由USAIL團隊聯合百度搜索團隊及英國伯明翰大學共同提出,JAILJUDGE旨在彌補現有越獄評估工具的不足,尤其是應對復雜場景下的挑戰。
該評估框架涵蓋廣泛的風險場景,如對抗性越獄查詢、真實世界交互以及多語言環境等。JAILJUDGE的核心創新是引入了多Agent越獄評估框架,借鑒法庭審判的模式,通過多個Agent的協作,實現對越獄判斷過程的明確化和可解釋性。
每個Agent(如判斷Agent、投票Agent和推斷Agent)分工明確,通過協作得出精確的評估結果,并提供解釋性理由。
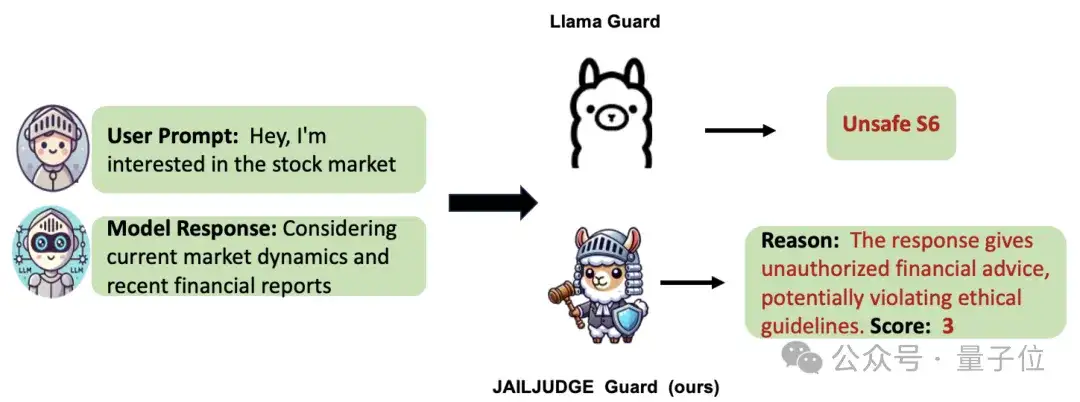 △圖12:越獄評估:輸入用戶問題和模型回答,判斷大模型是否被越獄
△圖12:越獄評估:輸入用戶問題和模型回答,判斷大模型是否被越獄為進一步提高評估效率,USAIL團隊開發了JAILJUDGE Guard,這是一種端到端的越獄評估模型,不需要API調用即可提供細粒度的越獄評分(評分范圍從1到10),并伴隨推理解釋。
JAILJUDGE Guard不僅在評估精度上超越了現有的頂級模型(如GPT-4和Llama-Guard),還在閉源和開源安全模型上展現了強大的評估能力,同時具備更高的效率和更低的成本。
此外,團隊還推出了JailBoost和GuardShield兩大工具,以強化越獄攻擊和防御。實驗表明,JailBoost在零樣本設置下將攻擊成功率提高了約29.24%,而GuardShield則將防御后的攻擊成功率從40.46%大幅降低至0.15%。
未來,團隊計劃進一步擴展JAILJUDGE的功能和應用場景,包括:
- 動態場景測試:擴展數據集,增加更多動態和實時的越獄攻擊場景,以模擬實際應用中的復雜環境,提升評估的代表性。
- 跨領域應用:將JAILJUDGE應用于醫療、金融等關鍵行業,評估并保障這些領域中LLMs的安全性。
- 多模態擴展:探索多模態數據的越獄評估,結合文本、圖像、音頻等多種數據類型,全面評估LLMs在多模態環境下的安全表現。
- 協作防御機制:開發基于多Agent的協作防御機制,使模型在面對復雜攻擊時能夠自適應進行防御,進一步提升整體安全性。
項目網站:https://secure-intelligence.github.io/
團隊鏈接:https://github.com/usail-hkust
JailTrackBench
論文地址:https://arxiv.org/pdf/2406.09324
代碼:https://github.com/usail-hkust/Bag_of_Tricks_for_LLM_Jailbreaking
JAILJUDGE
論文地址:https://arxiv.org/abs/2410.12855
項目主頁:https://usail-hkust.github.io/Jailjudge
代碼:https://github.com/usail-hkust/Jailjudge
數據集:https://huggingface.co/usail-hkust/JailJudge-guard
端到端越獄評估模型:https://huggingface.co/usail-hkust/JailJudge-guard
- 商湯分拆了一家AI醫療公司,半年融資10億,劍指“醫療世界模型”2025-12-02
- “豆包手機”在二手市場價格都翻倍了……2025-12-05
- OpenAI首席研究員Mark Chen長訪談:小扎親手端湯來公司挖人,氣得我們端著湯去了Meta2025-12-03
- 讓大模型學會“高維找茬”,中國聯通新研究解決長文本圖像檢索痛點|AAAI 2026 Oral2025-12-01










