MiniMax不藏了,大秀視頻/語音/文本全模態(tài)模型家族,“每天與世界交互30億次”
Intelligence with Everyone
明敏 衡宇 發(fā)自 凹非寺
量子位 | 公眾號 QbitAI
終于,MiniMax不藏了。
首次正式公開亮相,最強(qiáng)大模型、最亮眼產(chǎn)品戰(zhàn)績,全部對外展示。

模型全家桶最新版齊上陣,從文本、語音到視頻覆蓋全模態(tài)——達(dá)成如此豐富模態(tài)且同步開放,屬實(shí)是國產(chǎn)創(chuàng)業(yè)公司中首位。
尤其是視頻模型如期發(fā)布,兌現(xiàn)了7月WAIC上創(chuàng)始人兼CEO閆俊杰放出的承諾。
旗下產(chǎn)品最新戰(zhàn)績也正式公開:
每天30億次交互量。
其中生成文本量3萬億文本tokens,生成圖片2000萬張、生成語音7萬小時(shí)。
什么概念?
- 30億次文本交互=3000人一輩子的文本處理量;
- 2000萬張圖片=400座故宮的畫作收藏量;
- 7萬小時(shí)語音=讀完7000本書。
而3萬億文本tokens這個(gè)數(shù)據(jù)處理量,在第一梯隊(duì)其它友商披露出5千到1萬億tokens日處理量的當(dāng)下,也有斷層優(yōu)勢。
需要注意的是,這些數(shù)據(jù),都是1天時(shí)間內(nèi)在MiniMax產(chǎn)品上產(chǎn)生的。

一直以來,無論技術(shù)、產(chǎn)品還是融資,MiniMax一有風(fēng)吹草動(dòng),都會(huì)引發(fā)海內(nèi)外各界關(guān)注。但他們始終保持著悶聲搞事的路線。模型發(fā)布、產(chǎn)品上線總是讓人猝不及防,公開的大型活動(dòng)更是幾乎沒有。
成立近1000天,MiniMax到底想做什么?外界的好奇,早已呼之欲出。
終于,帶著最能證明實(shí)力的技術(shù)和產(chǎn)品,閆俊杰站在自家聚光燈下給出回答。
Intelligence with Everyone
這是MiniMax的愿景,更是路徑。
初創(chuàng)公司中首先拿下全模態(tài)
MiniMax想要做什么?
先來看最新技術(shù)進(jìn)展——
本次活動(dòng)上一共發(fā)布了4種模態(tài)大模型,分別是:
- 視頻模型,abab-video-1
- 音樂模型,abab-music-1
- 語音模型,abab-speech-1
- 文本萬億多模態(tài)模型,abab-7
這些模型,支撐起了全國最大的AI交互量,在一年前的今天,當(dāng)時(shí)的交互時(shí)長大約只有ChatGPT的3%;到了今天,交互時(shí)長已經(jīng)超過了其50%。
也構(gòu)筑起了MiniMax的堅(jiān)實(shí)壁壘——放眼國內(nèi)AI大模型初創(chuàng)公司,MiniMax率先完成了全模態(tài)模型的研發(fā)和開放。
實(shí)力不可謂不雄厚。
其中最值得說道說道的,是MiniMax視頻模型abab-video-1以及語音大模型abab-speech-1。
視頻模型abab-video-1
視頻模型是今年自Sora發(fā)布以來最熱門的模型選手。
從文生圖時(shí)代一路傳承下來的宇航員騎馬,也成為了各家視頻模型小試牛刀的必考題。
我們自然也沒放過MiniMax家的abab-video-1(手動(dòng)狗頭):

不只是我們,哪怕是在X上,網(wǎng)友們也已經(jīng)玩瘋了!
AI電影人迫不及待用abab-video-1做出了超越自己前作的電影《地獄之地》。

還有些網(wǎng)友腦洞大開,想出的提示詞都別具一格:
一位留著長胡子的標(biāo)志性亞洲美女,身穿比基尼,沿著海岸線向鏡頭跑去。夕陽透過云層在背景中閃爍,所有這些都以慢動(dòng)作捕捉。
但abab-video-1壓根沒在怕的:

據(jù)了解,abab-video-1畫質(zhì)方面最高支持1280*720的25fps,“擁有電影感鏡頭移動(dòng)”,并且支持帶文字元素。
目前AI視頻時(shí)長最高6秒,未來或支持10秒。
除了現(xiàn)有的文生視頻功能,未來還將推出圖生視頻和文圖結(jié)合生成視頻的能力。
綜合官方demo和人肉測試,MiniMax視頻模型有兩個(gè)非常顯著的特點(diǎn),一個(gè)是一致性連貫性方面,視頻中所有的畫面主體,幾乎不會(huì)發(fā)生劇烈形變或崩壞的情況。

另一個(gè)是視覺呈現(xiàn)方面,所有生成視頻內(nèi)容整體畫面色彩偏鮮艷。

劃重點(diǎn):限時(shí)免費(fèi)。
官方口吻是,今后新版本達(dá)到滿意狀態(tài)后,考慮開啟商業(yè)化計(jì)劃。
視頻生成的復(fù)雜度遠(yuǎn)高于文本,包括處理長上下文、巨大的存儲(chǔ)需求以及基礎(chǔ)設(shè)施升級等問題,同時(shí)視頻背后的存儲(chǔ)量很大,100個(gè)文字可能不到1k,但5秒視頻占據(jù)幾兆之多。
不過閆俊杰表示:
我們確實(shí)在視頻模型生成方面取得很大的進(jìn)展,根據(jù)內(nèi)部評測以及跑分,我們比其他模型的(生成視頻)效果都要好。
相比已經(jīng)在國際市場上打響名聲的國內(nèi)視頻模型先頭兵快手可靈,MiniMax的視頻生成模型推出時(shí)間晚了一兩個(gè)月。
閆俊杰說,這是因?yàn)閳F(tuán)隊(duì)一直在解決更具挑戰(zhàn)性的技術(shù)問題,特別是如何訓(xùn)練算力較高的內(nèi)容。

語音模型abab-speech-1
接著來聊一聊MiniMax的語音模型。
只需要20秒真人語音作為語料數(shù)據(jù),喂給abab-speech-1,幾乎只用眨一次眼睛的時(shí)間,AI語音就熱乎出爐了。
如果要用一組詞來形容abab-speech-1的特色,那大概可以是不同音色、飽滿情緒、多種語言、輕松生成。
而且,是超擬人的那種。
具體來看,它能支持多種語言的語音,譬如中文、英文、西語、日語,國內(nèi)方言如粵語也不在話下。
聽起來也真的很去“AI味”,跟真人發(fā)送的語音消息一般無二。
有實(shí)例為證——之前央視節(jié)目《嗨!AI-音樂季》中,MiniMax語音大模型對歌手龔琳娜的語料進(jìn)行采集、分析、模擬。
然后AI龔琳娜語音和其母親打了個(gè)電話,完全沒有被識(shí)破。
雖然叫“語音大模型”,但其實(shí)它兼具音樂生成的能力。
只需經(jīng)歷輸入靈感——生成歌詞——選擇風(fēng)格——生成歌曲四個(gè)簡簡單單的步驟。
曲風(fēng)上面,不管是節(jié)奏布魯斯、說唱還是電子,都輕松拿捏。
別看它剛剛亮相,但其實(shí)MiniMax的語音大模型從去年11月開始就已經(jīng)上崗就業(yè)。
迄今為止,它服務(wù)了近500家企業(yè)用戶,在語言學(xué)習(xí)、PC語音助手、語音聲聊唱聊、超擬人情感配音等十余種場景都有落地案例。

上述所有的一切,都基于MiniMax的技術(shù)底座構(gòu)建。
在底層技術(shù)上,MiniMax核心關(guān)注3方面:
- 持續(xù)降低模型錯(cuò)誤率
- 無限長輸入輸出
- 多模態(tài)
這是模型之上的產(chǎn)品,能夠更快更強(qiáng)的關(guān)鍵要素。
閆俊杰認(rèn)為,大語言模型領(lǐng)域,兩個(gè)模型性能相似,一定是速度更快的那個(gè)模型更容易帶來產(chǎn)品數(shù)據(jù)增長。就好像Scaling Law一樣,算法相同情況下,訓(xùn)練數(shù)據(jù)量更大的模型往往會(huì)取得更好效果。
在如何讓模型變得更快上,MiniMax做了兩次重大的技術(shù)變革:第一是MoE,第二是Linear Attention。
這兩者,都集中體現(xiàn)在數(shù)周后將正式對外的多模態(tài)模型abab-7身上,沒錯(cuò),就是使用MoE+Linear Attention技術(shù)的那種。
首先是在MoE(混合專家模型)尚未形成共識(shí)時(shí),就已經(jīng)決心押注,并且身體力行地在路上。
展開來說,今年1月,MiniMax發(fā)布了國內(nèi)首個(gè)MoE大語言模型abab-6;又很快地在4月推出了abab-6.5系列。
基于這個(gè)結(jié)構(gòu),模型可以處理復(fù)雜任務(wù),同時(shí)提升計(jì)算效率,在單位時(shí)間內(nèi)訓(xùn)練更多(多到“足夠多”)的數(shù)據(jù)。
MiniMax官方表示,其MoE模型取得了比Dense模型快3-5倍的速度。
具體在模型表現(xiàn)上,abab-6.5s在1秒內(nèi)可以處理近3萬字的文本。

其次是對Linear架構(gòu)的選擇。
過去的線性注意力存在缺陷,建模效果遜于標(biāo)準(zhǔn)注意力,速度也不如標(biāo)準(zhǔn)注意力,且召回能力有限,使得復(fù)雜推理能力偏弱。
針對這些問題,MiniMax設(shè)計(jì)了全新的Linear架構(gòu),在保證精度和效率的同時(shí),解決了Linear Attention召回能力弱的問題,使得新架構(gòu)可以適用于復(fù)雜推理任務(wù)。
在Benchmark上,新Linear架構(gòu)達(dá)到相同效果所需訓(xùn)練算力減少了三成;推理側(cè),尤其是長文推理成本顯著降低,128k窗口推理成本下降到二分之一,10M窗口推理成本甚至降低了85%。
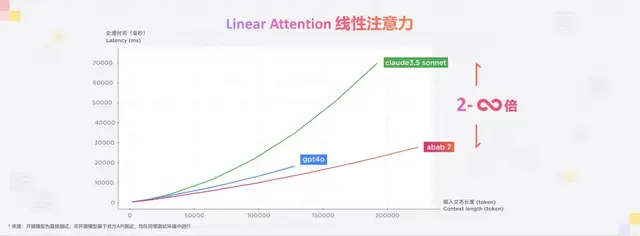
另外,面對快速增長的推理壓力,MiniMax一邊進(jìn)行上下文緩存持久化(即把對話歷史的LLM Attention kv cache持久化/半持久化保存下來、持續(xù)復(fù)用)和多階段推理(即在容器層面保持單一用途),提升性能和資源的利用效率。
另一邊,MiniMax的模型背后是超大的推理集群,支持海量高并發(fā)吞吐,以此支撐將各個(gè)版本、各個(gè)模態(tài)的模型應(yīng)用于大規(guī)模用戶產(chǎn)品中。
不難看出,算力實(shí)力打底,全模態(tài)多點(diǎn)開花,作為國內(nèi)最早入局大模型創(chuàng)業(yè)的公司之一,MiniMax憑借著自己雄厚的研發(fā)實(shí)力穩(wěn)步向前。
大模型每天30億次交互
所有的技術(shù)積淀,都只為了一個(gè)目的:
Intelligence with Everyone。
目前,MiniMax旗下主要有四款產(chǎn)品:星野、Talkie、海螺AI和開放平臺(tái)。
前三者主打2C,開放平臺(tái)更多面向開發(fā)者。
2C不難理解,這代表了更廣闊的市場。不過為什么要做這么多產(chǎn)品?
一方面,從觸及所有人的目標(biāo)出發(fā),多個(gè)不同定位的產(chǎn)品,能更快速觸達(dá)更多用戶。
另一方面,站在初創(chuàng)公司內(nèi)部視角來看,多嘗試才能找到真正正確的答案。與此同時(shí),閆俊杰認(rèn)為對于初創(chuàng)公司,如果沒有足夠好的產(chǎn)品能力來承接技術(shù),那么哪怕取得了一定的技術(shù)進(jìn)展,這些東西最終也不是你的。
但如今,行業(yè)對于大模型的商業(yè)化路徑都還模棱兩可。技術(shù)和產(chǎn)品之間該如何平衡,哪個(gè)更重要?
在閆俊杰的最新分享中給出了回答:以Intelligence with Everyone為起點(diǎn),技術(shù)和產(chǎn)品密不可分。
產(chǎn)品是技術(shù)落地的平臺(tái),它能直接體現(xiàn)技術(shù)的價(jià)值,也是實(shí)現(xiàn)AGI愿景的必要路徑。技術(shù)是產(chǎn)品前進(jìn)的核心驅(qū)動(dòng)力。如何抵達(dá)Intelligence with Everyone的終局,核心只有兩點(diǎn):
- 怎樣提升用戶的滲透率
- 怎樣提高用戶的使用深度
我們認(rèn)為提升這兩點(diǎn)只能通過一件事來完成,一句話總結(jié):科學(xué)技術(shù)是第一生產(chǎn)力。
比如,如何提高滲透率。轉(zhuǎn)化到技術(shù)角度,應(yīng)該考慮的是如何持續(xù)降低模型錯(cuò)誤率、無限長度的輸入和輸出以及多模態(tài)。
降低模型錯(cuò)誤率是為了讓模型能處理更復(fù)雜的任務(wù),這是增加用戶使用深度的核心手段。
讓模型的輸入輸出盡可能長,則是讓AI更進(jìn)一步像人。
考慮到人類社會(huì)中,文字信息的占比非常小,更多信息交流是通過語音、圖文、視頻來傳遞,所以多模態(tài)也很重要。
基于這些產(chǎn)品方面提出的要求,MiniMax提出了“快就是好”,通過技術(shù)創(chuàng)新,來讓模型變得更快、更好,這一點(diǎn)在他們的最新技術(shù)成果MoE+Linear Attention架構(gòu)中也已全面展示。
每當(dāng)模型有重大提升后,MiniMax也能直接從用戶層面得到反饋。比如使用深度顯著變高,也會(huì)遇到對話量顯著下滑的事故。而這也更進(jìn)一步驗(yàn)證了在AI領(lǐng)域里,技術(shù)和產(chǎn)品之間密不可分的關(guān)系。
目前,MiniMax的產(chǎn)品每天可產(chǎn)生30億次交互,積累用戶超過6000萬。
其中有諸多企業(yè)客戶,比如快遞100、智聯(lián)招聘。MiniMax的模型可以完成客服服務(wù)、地址補(bǔ)全、甚至是OKR調(diào)整等任務(wù)。
更多的是廣大普通用戶,他們每天在星野、海螺AI上與AI對話。AI創(chuàng)造的形象、智能體也成為了他們?nèi)粘I畹囊徊糠帧?/p>
不鳴則已
成立996天,MiniMax終于自己搭建了舞臺(tái),完成了對外首秀。
為什么要等這么久?
畢竟,MiniMax從不缺關(guān)注度。明星創(chuàng)始團(tuán)隊(duì)、熱門AI應(yīng)用、一筆又一筆大額融資……只用跨一步,MiniMax就能完成華麗的登臺(tái)亮相。
等到現(xiàn)在,或許是公司策略上的考量,或許是團(tuán)隊(duì)個(gè)性使然。
一方面,MiniMax似乎更愿意用實(shí)績說話。
產(chǎn)品每天30億次交互、3萬億token處理量,大概已是國內(nèi)公司中的No.1,“并且可能比第二名多2-3倍”。底層MoE模型,在性能和效率上都已驗(yàn)證實(shí)力,6000萬用戶就是最好的證明。以及率先達(dá)成全模態(tài)能力,不發(fā)模型則已,一發(fā)就是視頻語音音樂全都來。
更重要的是,MiniMax的路線已被驗(yàn)證。
Intelligence with Everyone。技術(shù)和產(chǎn)品并駕齊驅(qū),讓MiniMax能更快從用戶側(cè)得到反饋,在技術(shù)上進(jìn)行提升、產(chǎn)品上進(jìn)行優(yōu)化。重2C但是也做2B,滿足普通用戶和開發(fā)者的需求,當(dāng)然也是更健康的商業(yè)模式。
最關(guān)鍵的是,帶著這樣一份亮眼的成績單首秀,MiniMax的實(shí)力不言而喻。
另一方面,MiniMax絕對稱得上是一家有個(gè)性的初創(chuàng)公司。
大模型目前仍舊是一個(gè)非共識(shí)議題,技術(shù)路線的選擇一定程度上決定公司的生死。
閆俊杰曾直言,自己選了一條非常激進(jìn)的路線。
去年,在其他公司還在迭代稠密模型時(shí),閆俊杰轉(zhuǎn)去賭MoE路線。大模型趨勢日新月異,幾個(gè)月時(shí)間里別人都在快速進(jìn)步,但MiniMax把80%以上的算力和研發(fā)資源都用來做MoE,且沒有Plan B。
過程中,前后失敗了兩次。模型訓(xùn)了半個(gè)月,指標(biāo)離前期估測越來越遠(yuǎn)。背后不僅是團(tuán)隊(duì)精力、時(shí)間、資金的巨大投入,也是對信心的考驗(yàn)。
換來的是,MiniMax成為國內(nèi)首個(gè)推出MoE大模型的公司。也剛好和OpenAI走在了同一條路線上。
從外部視角來看,有能力、有個(gè)性是MiniMax最為鮮明的特點(diǎn)。
而從內(nèi)來看,閆俊杰表示,MiniMax的內(nèi)核要素還有最重要的一點(diǎn):樂觀。
我們對技術(shù)的進(jìn)步充滿了樂觀,對用戶充滿了樂觀,對產(chǎn)品的迭代效率充滿了樂觀。
盡管有時(shí)候會(huì)遇到很多挑戰(zhàn),但是我覺得我們可能是大模型里面能夠最堅(jiān)持往前來迭代技術(shù),最堅(jiān)持跟用戶互動(dòng)的大模型公司,也是最國際化的一家大模型公司。
悲觀者正確,樂觀者永遠(yuǎn)勇于前行。
完成首秀后,MiniMax的腳步也一點(diǎn)不停歇。
在活動(dòng)上,閆俊杰放出重磅預(yù)告,最新一代旗艦?zāi)P蚢bab-7即將正式亮相。
結(jié)合最近OpenAI風(fēng)聲不斷,新一代模型呼之欲出。
那么國內(nèi),誰能是最快追趕的呢?有好戲看了。
相關(guān)閱讀

AI玩推理桌游一眼識(shí)破騙局!清華通院聯(lián)合推出心智理論新框架,6個(gè)指標(biāo)評估表現(xiàn)均明顯優(yōu)于思維鏈
AI學(xué)會(huì)“三思而后行”和“換位思考”