
Q*項目公開發布!研究團隊并非OpenAI
百倍提升小模型推理能力
昆侖萬維 投稿
量子位 | 公眾號 QbitAI
Q*項目公開發布,可讓小模型達到參數量比其大數十倍、甚至上百倍模型的推理能力。

自去年11月伴隨著OpenAI內訌,其神秘Q*項目被爆出后,業內對OpenAI?Q*的討論和猜測就沒停過,而OpenAI這邊一直避而不談。
在當時,一些人就從名字猜測Q*可能與Q-Learning有關,例如Meta科學家田淵棟提出Q*可能是Q-learning和A*的結合:

而現在,一項名為Q*的項目突然公開發布,而且真的和Q-Learning、A*有關。

不過,研究團隊并非OpenAI,更不是DeepMind(相傳,OpenAI的Q*項目前身是GPT-Zero,由Ilya Sutskever發起,名字致敬了DeepMind的Alpha-Zero)。
而是來自國內昆侖萬維顏水成團隊與新加坡南洋理工大學的一項新工作。
團隊表示,希望Q*算法能夠打破OpenAI的封鎖,提升現有開源模型的推理能力。實驗中,Q*算法的表現也很給力:
- 在GSM8K數據集上,Q*幫助Llama-2-7b提升至80.8%的準確率,超越了ChatGPT;
- 在MATH數據集上,Q*幫助DeepSeek-Math-7b提升至55.4%的準確率,超越了Gemini Ultra;
- 在MBPP數據集上,Q*幫助CodeQwen1.5-7b-Chat提升至77.0%的準確率,縮小了與GPT-4的編程水平差距。
網友看到這項工作后一時間炸開了鍋,研究命名無疑成為了討論的一大焦點,網友的評論卻很一致:
這就是Q*。

雖然不是那個Q*,但卻是真正的Q*:

誰讓OpenAI至今不發布任何名為Q*的工作:
拋開命名,從研究本身來講,有網友看過論文后感嘆這項研究真不簡單:
越思考,就越覺得Q*的這個方法是正確的。

甚至有網友認為有種AGI的感覺:

那么,Q*到底長啥樣?
復雜推理任務全盤規劃

最后利用A*搜索算法對狀態進行最佳優先搜索,實現了對復雜推理任務的全盤規劃,從而提升開源模型在推理任務上的性能。
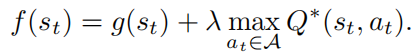




隨后,研究團隊通過一系列實驗,證實了Q*框架可以顯著提升LLM的推理能力。
如開頭所述,在GSM8K數據集上,Q*幫助Llama-2-7b提升至80.8%的準確率,超越了ChatGPT;在MATH數據集上,Q*幫助DeepSeek-Math-7b提升至55.4%的準確率,超越了Gemini Ultra; 在MBPP數據集上,Q*幫助CodeQwen1.5-7b-Chat提升至77.0%的準確率,縮小了與GPT-4的編程水平差距。
具體結果見下圖:

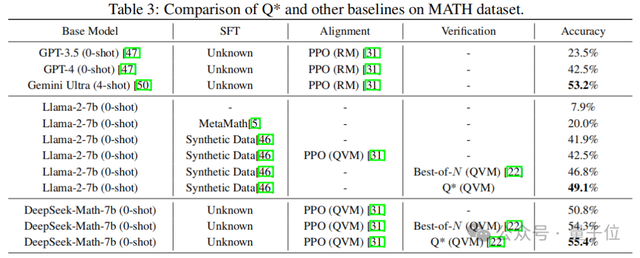

Q*能夠幫助參數量僅為7b的小模型達到參數量比其大數十倍甚至百倍模型的推理能力,大幅提升模型的性能,并顯著降低了計算資源的需求。
不過,昆侖萬維團隊也表示,Q*的研究尚在初級階段,算法在各個環節還有進一步的改進空間。
未來,會繼續深入此項研究,不斷提升國產開源模型推理能力,打破OpenAI閉源封鎖,為AI前沿技術發展帶來全新可能。
更多細節,感興趣的家人們可以查看原論文~
論文鏈接:https://arxiv.org/abs/2406.14283
- 商湯分拆了一家AI醫療公司,半年融資10億,劍指“醫療世界模型”2025-12-02
- “豆包手機”在二手市場價格都翻倍了……2025-12-05
- OpenAI首席研究員Mark Chen長訪談:小扎親手端湯來公司挖人,氣得我們端著湯去了Meta2025-12-03
- 讓大模型學會“高維找茬”,中國聯通新研究解決長文本圖像檢索痛點|AAAI 2026 Oral2025-12-01
相關閱讀










