
李飛飛團隊實現(xiàn)“隔空建模”,透過遮擋物還原完整3D人體模型
遮擋部分建模質(zhì)量接近翻倍
克雷西 發(fā)自 凹非寺
量子位 | 公眾號 QbitAI
注意看,這個男人搬著一個長長的柜子,畫面中半個人都被遮擋住了。
但即使有這樣的遮擋,男人的整個身體在AI面前依然是無所遁形。

哪怕是蹲在椅子背后只露出頭,依然可以被模型完整還原。

從遮擋物背后把人“揪”出來的,是李飛飛團隊推出的人體建模新工具Wild2Avatar(本文簡稱W2A)。
只要一段4秒左右的的單角度視頻,就能構(gòu)建出完整的3D模型,有遮擋也不怕。

相比此前的SOTA方法,Wild2Avatar在人體建模上可謂是實現(xiàn)了質(zhì)的飛躍。
建模效果完勝Vid2Avatar
從下面的對比圖中(從左到右依次為帶遮擋原圖、Vid2Avatar提取結(jié)果和W2A提取結(jié)果)可以看到,作為baseline的Vid2Avatar方法只能大概描繪出人的輪廓,遮擋物直接被“拍扁”到了人物身上,而且輪廓看上去也不夠準(zhǔn)確。
而W2A提取出的人物不僅輪廓更加精確,看上去也更具立體感,關(guān)鍵是遮擋物被完美地去除,顯現(xiàn)出了完整的人物結(jié)構(gòu)。

對遮擋物的去除,W2A操作得也更為徹底,沒有留下多余的痕跡。

而baseline中部分結(jié)構(gòu)缺失的現(xiàn)象,在W2A中也沒有發(fā)生,人物的結(jié)構(gòu)十分完整。

而且,W2A的人物建模是動態(tài)的,視頻畫面中,就算整個人都藏在椅子后面,依然可以輸出人物模型。

和另一baseline OccNeRF相比,W2A只需100幀的訓(xùn)練視頻就能復(fù)原出完整干凈的結(jié)構(gòu),但后者用了500幀的系列視頻后不僅結(jié)構(gòu)缺陷極大,還存在許多“鬼影”。

測試數(shù)據(jù)也表明,對于陌生場景,W2A的提取質(zhì)量和完整性(comp.)都比V2A有所提升,特別是對遮擋(llm)部分,合成質(zhì)量得分接近翻番。

和OccNeRF相比,W2A與500幀訓(xùn)練數(shù)據(jù)的OccNeRF整體成績接近,但遮擋部分仍然是有明顯增強。

那么,Wild2Avatar是如何實現(xiàn)的呢?
人物與遮擋分層處理
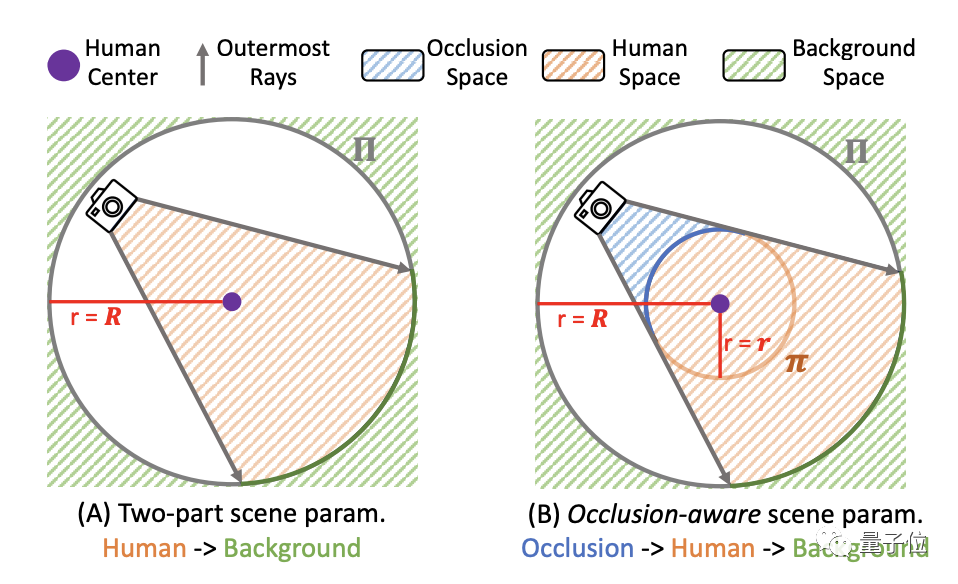
工作過程中,W2A將整個場景分成了遮擋物、人物本體和背景三部分。
這三個部分由獨立的NeRF網(wǎng)絡(luò)分別預(yù)測特征,渲染圖像時再將三個部分的輸出拼合。

這種做法的主要目的是為了避免遮擋被誤當(dāng)成人體的一部分,出現(xiàn)Video2Avatar那樣把遮擋物合成進人物的情況。
具體來說,李飛飛團隊將圖像映射到一個球空間,背景位于球外,人物和遮擋物則分別位于球空間內(nèi)部的不同位置。
遮擋空間是通過內(nèi)部采樣點的坐標(biāo)和距離來構(gòu)造的。用于遮擋部分的生成網(wǎng)絡(luò)與背景共享,可以預(yù)測遮擋空間樣本點的顏色和密度值。
而人體部分的處理則是使用SMPL的參數(shù)化方式,通過正向和反向皮膚擬合,先將人體變形到一個姿態(tài)不變的坐標(biāo)空間,再輸入神經(jīng)網(wǎng)絡(luò)進行學(xué)習(xí)。
為了增強任務(wù)模型的完整性,李飛飛團隊還設(shè)計了新的損失計算方式。
首先利用現(xiàn)成的分割模型輸出人體的二值分割掩碼,并掩碼取反得到“非人體”區(qū)域的掩碼,即為可能的遮擋區(qū)域。
同時,從W2A渲染的三個部分中遮擋部分的密度圖,然后根據(jù)提取結(jié)果再分離出人體部分。
其中人體部分與前面得到的“非人體”掩碼進行與非運算,得到的結(jié)果再和遮擋部分的密度圖做二值交叉熵運算,就得到了遮擋解耦損失Locc。

Locc會與像素重構(gòu)損失、場景分解損失等其他損失參數(shù)一并納入到整個網(wǎng)絡(luò)的端到端訓(xùn)練過程,用于優(yōu)化更新網(wǎng)絡(luò)參數(shù)。
論文地址:
https://arxiv.org/abs/2401.00431
- 14歲華人小孩,折個紙成美國天才少年2025-12-06
- 智能體A2A落地華為新旗艦,鴻蒙開發(fā)者新機遇來了2025-12-06
- 《三體》“宇宙閃爍”成真!免佩戴裸眼3D屏登Nature2025-12-06
- ROCK & ROLL!阿里給智能體造了個實戰(zhàn)演練場 | 開源2025-11-26
相關(guān)閱讀










