
「灌籃高手」模擬人形機器人,一比一照搬人類籃球招式,看一遍就能學會,無需特定任務的獎勵
投籃運球手指轉球,人類會的它都會
西風 發自 凹非寺
量子位 | 公眾號 QbitAI
投籃、運球、手指轉球…這個物理模擬人形機器人會打球:

會的招數還不少:

一通秀技下來,原來都是跟人學的,每個動作細節都精確復制:

這就是最近的一項名為PhysHOI的新研究,能夠讓物理模擬的人形機器人通過觀看人與物體交互(HOI)的演示,學習并模仿這些動作和技巧。
重點是,PhysHOI無需為每個特定任務設定具體的獎勵機制,機器人可以自主學習和適應。
而且機器人的身上總共有51×3個獨立控制點,所以模仿起來能做到高度逼真。

一起來看具體是如何實現的。
模擬人形機器人變身「灌籃高手」
這項工作由來自北京大學、IDEA研究院、清華大學、卡內基梅隆大學的研究人員共同提出。

經研究人員介紹,此前大多數類似工作,存在模仿動作孤立、需特定任務的獎勵、未涉及靈巧的全身運動等局限。

而他們提出的PhysHOI,應用動作捕捉技術提取HOI數據,然后使用模仿學習來學習人體運動和物體控制,解決了這些問題。
其中,HOI數據重要組成部分之一是涵蓋了人體運動、物體運動、相對運動的運動學數據(Kinematic Data),記錄了位置、速度、角度等信息。
另外,動態數據(Dynamic Data)反映了運動過程中的實時變動和更新,也很重要。

為了彌補HOI數據中動態信息的不足,研究人員引入了接觸圖(contact graph,CG)。

CG的節點由機器人的肢體部件和物體組成;每條邊則是一個二進制接觸標簽,只表達“接觸”或“不接觸”兩種狀態。
此外,還可以將多個肢體部件放到一個節點中,形成一個聚合CG(Aggregated CG)。
具體來說,PhysHOI方法是:
首先通過運動捕捉獲取參考HOI狀態序列,包含人體運動、物體運動、交互圖和接觸圖。
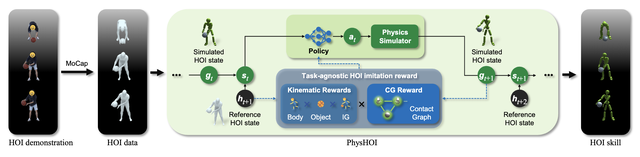
然后用第一幀的信息初始化物理模擬環境,構建包含當前模擬狀態和下一個參考狀態的系統狀態。
接下來輸入策略網絡生成的動作控制人形機器人,物理模擬器根據動作更新場景中人體和物體的狀態,計算包含運動匹配、接觸圖等多個方面的獎勵。
利用獎勵、狀態和動作樣本優化策略網絡,采用更新后的策略網絡開始新一輪的模擬過程,如此循環直至網絡收斂,最終獲得能夠重現參考HOI技能的控制策略。
值得一提的是,研究人員在這當中設計了一個與任務無關的HOI模仿獎勵,無需針對不同任務自定義獎勵函數,包括體現運動匹配度的身體和物體獎勵、反映接觸正確性的接觸圖獎勵,避免了使用錯誤身體部位接觸物體等局部最優解。
接觸圖獎勵是關鍵
研究人員在兩個HOI數據集上測試了PhysHOI。
其中引入了BallPlay數據集,包含多種全身籃球技能。

研究人員在GRAB數據集的S8子集中選擇了5個抓取案例,以及BallPlay數據集的8個籃球技能。
以此前的DeepMimic、AMP等方法作為基線,為公平比較,研究人員將其做了修改,以適應HOI模仿任務。

結果顯示,以往只使用運動學獎勵的方法無法準確復現交互,球會掉落或抓握失敗。
而在接觸圖的指導下,PhysHOI成功進行了HOI模仿。
PhysHOI在兩個數據集上都獲得最高的成功率,分別為95.4%和82.4%,同時也取得最低的運動誤差,顯著優于其它方法。

消融研究表明,接觸圖獎勵能有效避免只使用運動信息的方法陷入局部最優,指導機器人實現正確接觸。

如果沒有接觸圖獎勵,人形機器人可能無法控制球,或者錯誤地使用身體其它部位控制球:

論文鏈接:https://arxiv.org/abs/2312.04393
- 商湯分拆了一家AI醫療公司,半年融資10億,劍指“醫療世界模型”2025-12-02
- “豆包手機”在二手市場價格都翻倍了……2025-12-05
- OpenAI首席研究員Mark Chen長訪談:小扎親手端湯來公司挖人,氣得我們端著湯去了Meta2025-12-03
- 讓大模型學會“高維找茬”,中國聯通新研究解決長文本圖像檢索痛點|AAAI 2026 Oral2025-12-01










