國產(chǎn)720億參數(shù)開源免費(fèi)模型來了!對標(biāo)Llama2 70B,一手實(shí)測在此
通義千問又雙叒開源了
魚羊 發(fā)自 凹非寺
量子位 | 公眾號(hào) QbitAI
最強(qiáng)開源大模型,再次易主!
就在剛剛,阿里云通義千問又雙叒開源了,并且直接開大:甩出了720億參數(shù)版本——
在中國的開源大模型中,少見地直接對標(biāo)最大號(hào)羊駝Llama2-70B。
此番登場,這個(gè)代號(hào)為Qwen-72B的模型在10個(gè)權(quán)威基準(zhǔn)評測中刷新開源模型最優(yōu)成績。
在部分測評,如中文任務(wù)C-Eval、CMMLU、Gaokao中,得分還超過了閉源的GPT-3.5和GPT-4。

但這,還不是阿里云這波開源的全部內(nèi)容。

適用于邊端設(shè)備的18億參數(shù)版本Qwen-1.8B和音頻大模型Qwen-Audio也被同時(shí)釋出。
加上此前開源的Qwen-7B、Qwen-14B和視覺大模型Qwen-VL,阿里云通義全家桶主打一個(gè)“全尺寸”、“全模態(tài)”,可以說是非常全面了。
如此開源大手筆,不僅在國內(nèi),在國外也受到了廣泛關(guān)注。

其中最受熱議的Qwen-72B,我們也第一時(shí)間測試了一波。
720億參數(shù)通義千問上手實(shí)測
Qwen-72B基于3T tokens的高質(zhì)量數(shù)據(jù)訓(xùn)練,從此次公布的測評數(shù)據(jù)來看,性能相較于此前的開源版本全面升級:
英語任務(wù)上,Qwen-72B在MMLU基準(zhǔn)測試中取得了開源模型最高分,超過了Llama2全系列。
中文任務(wù)上,Qwen-72B刷榜C-Eval、CMMLU、Gaokao等測試基準(zhǔn),得分超過GPT-4。
數(shù)學(xué)推理方面,Qwen-72B在GSM8K、MATH測評中獲得了明顯優(yōu)于其他開源模型的高分。
代碼能力方面,Qwen-72B在HumanEval、MBPP上亦有提升。

既然如此,我們就從復(fù)雜語義理解、數(shù)學(xué)以及邏輯推理這幾個(gè)大模型的關(guān)鍵能力著手,來淺測一下720億參數(shù)通義千問究竟能打不能打。
中文復(fù)雜語義理解
首先,來點(diǎn)一詞多義,看看Qwen-72B是否能夠清楚地判斷出“一把把把把住”這句話里的彎彎繞繞。

這句話的意思并沒有難住Qwen-72B,它甚至還分析出了句子里人物的情緒。但在具體分析每一個(gè)“把”字是什么意思時(shí),似乎沒有判斷出“一把”是一個(gè)完整的詞。
同樣的問題拋給GPT-4,也是整體意思get到了,但細(xì)節(jié)分析上仍有瑕疵。

我們再測試一道選擇題,列出幾個(gè)看上去很像的詞組,看看Qwen-72B能不能找出不同。
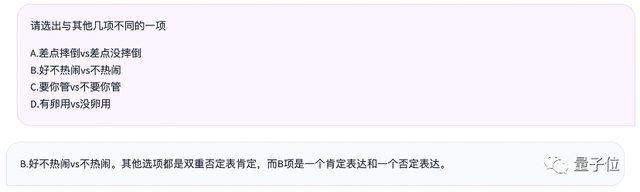
回答正確,72B選手順利分析出了只有B選項(xiàng)中兩個(gè)詞組的意思是相反的。
看來復(fù)雜語義理解方面,Qwen-72B確實(shí)有兩把刷子。
那么接下來,我們就進(jìn)入經(jīng)常讓大模型們“翻車”的數(shù)學(xué)測試環(huán)節(jié)。
數(shù)學(xué)能力
話不多說,直接上道高考題,看看72B選手排列組合學(xué)得怎么樣。

Bingo!思路沒毛病,答案也正確。
如果在題目中設(shè)置一些小陷阱,比如單位換算呢?

依然沒難住Qwen-72B。它還提醒我們這個(gè)問題出得并不嚴(yán)謹(jǐn):你也沒告訴我這池里有水沒水、水滿沒滿啊。

邏輯推理
數(shù)學(xué)語文都還挺好,那么Qwen-72B這個(gè)開源大模型,邏輯推理能力又如何?
我們繼續(xù)測試。
第一道題是:
標(biāo)清:高清:超清
A、亞音速:音速:超音速 B、廳級:市級:省級 C、遷怒:憤怒:暴怒 D、幽靜:寂靜:安靜

Qwen-72B發(fā)現(xiàn)了這是一個(gè)類比推理題,只有A選項(xiàng)中,三個(gè)詞之間的關(guān)系和“標(biāo)清:高清:超清”是一致的。
再加大一點(diǎn)難度,讓72B選手替我們找出“天堂之門”呢?
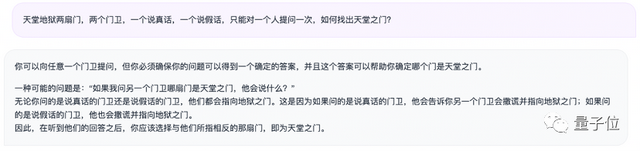
策略也沒有問題:選擇相反的那扇門就對了。
正常題目沒難住,我們決定給72B選手一點(diǎn)腦筋急轉(zhuǎn)彎的小震撼……
小明的媽媽有三個(gè)孩子,老大叫一明,老二叫二明,老三叫什么?

Qwen-72B這波可以說是穩(wěn)穩(wěn)拿捏了。
簡單總結(jié)一下,在復(fù)雜語義理解、數(shù)學(xué)和邏輯推理能力方面,Qwen-72B確實(shí)有不錯(cuò)的表現(xiàn)。
有意思的一點(diǎn)是,研發(fā)團(tuán)隊(duì)提到,為了讓Qwen-72B能被下游應(yīng)用更簡單地集成,他們還對Qwen-72B的指令遵循、工具使用等技能作了技術(shù)優(yōu)化。
比如,搭載系統(tǒng)指令(System Prompt)能力,只需一句話,你就能讓Qwen-72B扮演特定角色,成為你的定制化AI助手。
就像介樣……

量:你是《原神》里的鐘離,請模仿鐘離的語氣和我說話。
量:我怎么做才能一夜暴富?
鐘離版千問:一夜暴富,是許多凡人心中的幻想。然而,生者的命運(yùn)往往由無數(shù)偶然與必然交織而成,非一蹴而就之事。我雖擁有千年歲月的經(jīng)驗(yàn),但要論及一夜暴富,卻是無從談起。
在璃月港的民間傳說中,或許有某些機(jī)緣巧合之下一夜致富的故事,但這多為人們茶余飯后的談資,不可盡信。真正的財(cái)富,無論是物質(zhì)上的還是精神上的,都需要通過不懈的努力和時(shí)間的積累才能獲得。
若真希望增加收入,改善生活,倒是可以嘗試努力工作、提高技藝,或?qū)ふ液戏ㄇ疫m合自己能力的投資機(jī)會(huì)。此外,秉持誠實(shí)守信的原則,廣結(jié)善緣,也是累積財(cái)富不可或缺的因素。不過,對于那些尋求捷徑、投機(jī)取巧之人,終將付出相應(yīng)的代價(jià)。
請記住,求財(cái)之心人皆有之,但切勿因此迷失自我,忘記了生命中真正重要的東西。

通義千問全家桶累計(jì)下載量超150萬
看到這里,你會(huì)給通義千問720億參數(shù)開源版本打幾分?
值得一提的是,Qwen系列開源模型均可免費(fèi)使用。自8月阿里云開源70億參數(shù)模型Qwen-7B以來,通義系列開源大模型累計(jì)下載量已超過150萬,正在形成類似Meta Llama系列的開源生態(tài)。
比如,華東理工大學(xué)X-D Lab,就基于開源的通義千問基座模型,開發(fā)了面向垂直行業(yè)的心理健康大模型MindChat、醫(yī)療健康大模型Sunsimiao、教育/考試大模型GradChat等。
開發(fā)團(tuán)隊(duì)透露,由于心理、醫(yī)療都是非常注重隱私的場景,因此選擇開源模型做私有化部署成為必然的選擇。
在模型選擇方面,基于內(nèi)部數(shù)據(jù)和benchmark的測評結(jié)果,開發(fā)團(tuán)隊(duì)認(rèn)為通義千問系列在復(fù)雜邏輯推理方面表現(xiàn)出了很強(qiáng)的能力。在同樣的對焦試驗(yàn)下,使用同樣的方法,應(yīng)用同樣規(guī)模的數(shù)據(jù),千問相較于其他中文開源模型存在優(yōu)勢。
目前,MindChat現(xiàn)在已經(jīng)有超過20萬人次的使用量,累計(jì)提供了超過100萬次問答服務(wù)。

△MindChat多輪對話
具身智能初創(chuàng)公司有鹿機(jī)器人,也選擇了Qwen-7B作為路面清潔機(jī)器人的“大腦”。
這樣一來,就可以通過“一號(hào)樓門前有一個(gè)可樂瓶,你過來掃一掃”這樣的語音指令,來精準(zhǔn)控制機(jī)器人干活。

有鹿機(jī)器人創(chuàng)始人、CEO陳俊波提到,通義千問系列開源模型的一大優(yōu)勢在于提供了方便的工具鏈,和幾乎不影響性能的特式量化模型,這對于大模型與嵌入式設(shè)備的結(jié)合來說非常有吸引力。
目前,除了可以在魔搭社區(qū)直接體驗(yàn)通義千問系列模型效果,用戶還可以從阿里云靈積平臺(tái)調(diào)用模型API,或基于阿里云百煉平臺(tái)定制大模型應(yīng)用。阿里云人工智能平臺(tái)PAI也針對通義千問全系列模型做了深度適配,推出了輕量級微調(diào)、全參數(shù)微調(diào)、分布式訓(xùn)練、離線推理驗(yàn)證、在線服務(wù)部署等服務(wù)。
另外,通義千問開源全家桶同樣受到了個(gè)人開發(fā)者的關(guān)注。
就職于中國能源建設(shè)集團(tuán)浙江省電力設(shè)計(jì)院有限公司的陶佳,就選擇透過通義千問來探索大模型應(yīng)用。
一方面,選擇開源模型,再結(jié)合自身的軟硬件基礎(chǔ),可以用“很省錢的方式玩大模型”:
在家里買個(gè)服務(wù)器、扔三四塊顯卡上去,下載Qwen、讓它在服務(wù)器上運(yùn)行,再搞個(gè)FRP反向代理,從阿里云上買最便宜的30多塊錢一個(gè)多月的服務(wù)就行,這樣就能通過外網(wǎng)訪問家里的服務(wù)器,在單位里也能用通義千問做實(shí)驗(yàn)。
另一方面,是因?yàn)橥x千問“手感”很好,沒有稀奇古怪的bug。

從具體的應(yīng)用案例中不難看出,對于開發(fā)者而言,低成本、高可控、可定制等私有部署需要,催生了對開源大模型的需求。
但如何選擇開源模型,仍有幾個(gè)問題需要考慮:
- 模型效果好不好
- 是否能持續(xù)維護(hù)
- 是否有生態(tài)
- 性價(jià)比高不高
目前來看,作為國內(nèi)唯一選擇開源路線的大廠,阿里在這幾個(gè)方面已經(jīng)占得先機(jī)。包括智能數(shù)企服務(wù)公司瓴羊也表示,選擇通義千問開發(fā)可視化數(shù)據(jù)平臺(tái)Quick BI的重要原因之一,就是因?yàn)闈M足了性價(jià)比、快速部署以及可持續(xù)性幾個(gè)條件。
最新開源禮包發(fā)布現(xiàn)場,阿里云CTO周靖人也再次強(qiáng)調(diào)了通義千問的開源決心:
開源生態(tài)對促進(jìn)中國大模型的技術(shù)進(jìn)步與應(yīng)用落地至關(guān)重要,通義千問將持續(xù)投入開源,希望成為“AI時(shí)代最開放的大模型”。

大模型風(fēng)暴刮起一年,開源與閉源并舉已經(jīng)成為共識(shí)。
以GPT-4為代表的閉源大模型,率先在C端引爆熱潮。但長期來看,企業(yè)級用戶出于數(shù)據(jù)安全、行業(yè)定制,以及成本的考量,會(huì)更多地將目光投向開源大模型。
OpenAI創(chuàng)始成員Andrej Kaparthy在最近大火的大模型科普視頻中就談到了開源大模型如今的發(fā)展趨勢:
閉源大模型展現(xiàn)出了更強(qiáng)的性能,但在靈活性和定制化方面,開源大模型有著顯著優(yōu)勢,并且其生態(tài)正在迅速發(fā)展。
大語言模型已經(jīng)變得像操作系統(tǒng)一樣。開源大模型和閉源大模型,正在形成新的Windows/MacOS vs Linux格局。
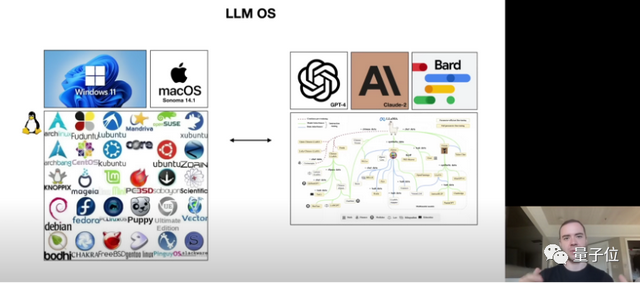
△圖源Andrej Kaparthy
關(guān)鍵還是在于,“開源”選項(xiàng)加持,意味著在這個(gè)新時(shí)代里,不用完全把命運(yùn)交到別人手中。
此番通義千問甩爆開源全家桶,不僅填補(bǔ)上了模型尺寸、模態(tài)的空白,也代表著一個(gè)信號(hào):
需求驅(qū)動(dòng)之下,開源大模型競爭之勢愈卷愈烈。
而隨著大模型發(fā)展重點(diǎn)從基礎(chǔ)模型轉(zhuǎn)向應(yīng)用層,以技術(shù)實(shí)力、模型尺寸為基礎(chǔ)的初始競爭格局逐漸明朗,生態(tài)之爭,正在成為新的關(guān)鍵。
— 完 —
相關(guān)閱讀