萬億大模型究竟怎么用?達摩院&浙大&上海人工智能實驗室聯手推出洛犀平臺:大小模型端云協同進化
須彌藏芥子,芥子納須彌
魚羊 發自 凹非寺
量子位 | 公眾號 QbitAI
AI領域這股大模型之風,可謂是席卷全球,越吹越勁。
單說2021年下半年,前有微軟英偉達聯手推出5300億參數NLP模型,后又見阿里達摩院一口氣將通用預訓練模型參數推高至10萬億。
而就在最近,扎克伯格還宣布要豪砸16000塊英偉達A100,搞出全球最快超級計算機,就為訓練萬億參數級大模型。
大模型正當其道,莫非小模型就沒啥搞頭了?

就在“中國工程院院刊:信息領域青年學術前沿論壇”上,阿里巴巴達摩院、上海浙江大學高等研究院、上海人工智能實驗室聯手給出了一個新的答案:
須彌藏芥子,芥子納須彌。
大小模型協同進化,才能充分利用大模型應用潛力,構建新一代人工智能體系。
此話怎講?
這就得先說說大模型“軍備競賽”背后的現實困境了。
大小模型協同進化
核心問題總結起來很簡單,就是大模型到底該怎么落地?
參數規模百億、千億,乃至萬億的大模型們,固然是語言能力、創作能力全面開花,但真想被部署到實際的業務當中,卻面臨著能耗和性能平衡的難題。
說白了,就是參數量競相增長的大模型們,規模太過龐大,很難真正在手機、汽車等端側設備上被部署應用——
要知道,1750億參數的GPT-3,模型大小已經超過了700G。
達摩院2022年十大科技趨勢報告中也提到,在經歷了一整年的參數競賽模式之后,在新的一年,大模型的規模發展將進入冷靜期。

不過在這個“陣痛期”,倒也并非沒有人試吃“大模型工業化應用”這只螃蟹。
比如,支付寶搜索框背后,已經試點集成業界首個落地的端上預訓練模型。
當然,不是把大模型強行塞進手機里——
來自阿里巴巴達摩院、上海浙江大學高等研究院、上海人工智能實驗室的聯合研究團隊,通過蒸餾壓縮和參數共享等技術手段,將3.4億參數的M6模型壓縮到了百萬參數,以大模型1/30的規模,保留了大模型90%以上的性能。
具體而言,壓縮后的M6小模型大小僅為10MB,與開源的16M ALBERT-zh小模型相比,體積減少近40%,并且效果更優。難得的是,10MB的M6模型依然具有文本生成能力。

在移動端排序模型部署方面,這支研究團隊同樣有所嘗試。
主流的模型壓縮、蒸餾、量化或參數共享,通常會使得到的小模型損失較大精度。
該團隊發現,把云上排序大模型拆分后部署,可形成小于10KB的端側精細輕量化子模型,即保證端側推理精度無損失,同時實現了輕量級應用端側資源。這也就是端云協同推理。
在阿里的應用場景下,研究團隊基于這樣的協同推理機制,結合表征矩陣壓縮、云端排序打分作為特征、實時序列等技術和信息,構建了端重排模型。
該技術試點部署在支付寶搜索、淘寶相關應用中,取得了較為顯著的推理效果提升,且相關百模設計解決了在不犧牲熱門用戶服務體驗的同時,最大化冷門用戶體驗的難題。

從以上的案例中,不難總結出大模型落地應用的一條可行的途徑:
取大模型之精華,化繁為簡,通過高精度壓縮,將大模型化身為終端可用的小模型。
這樣做的好處,還不只是將大模型的能力釋放到端側,通過大小模型的端云協同,小模型還可以向大模型反饋算法與執行成效,反過來提升云端大模型的認知推理能力。
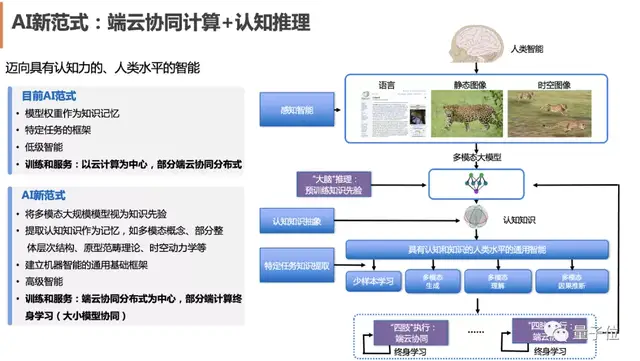
達摩院、浙大和上海人工智能實驗室,還進一步將這一技術路線總結為端云協同AI范式:
云端大模型作為超級大腦,擁有龐大的先驗知識,能進行深入的“慢思考”。
而端側小模型作為四肢,能完成高效的“快思考”和有力執行。
兩者共同進化,讓AI向具有認知力和接近人類水平的智能邁進。
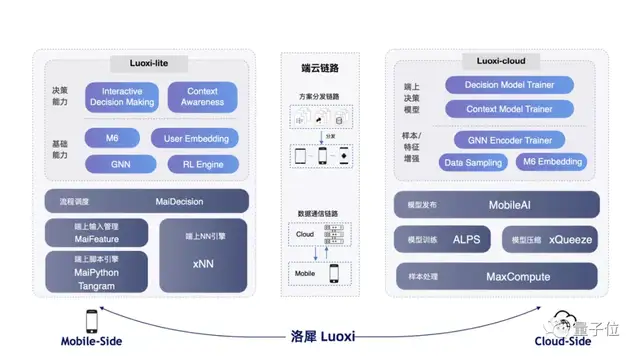
基于這樣的思考和實踐經驗,三方聯合研究團隊最新推出了端云協同平臺洛犀。
該平臺旨在將端云兩側的最佳實踐以文檔、算法組件、平臺服務的形式沉淀下來,為開發者提供一站式端云協同模型訓練、部署、通信能力。
具體而言,洛犀平臺可拆解為端側、云側、端云鏈路三部分。
其中,端側以Python/js package的形式提供服務,稱為Luoxi-lite,包含表征、文本理解、圖計算等能力。
端云鏈路側,平臺提供實現端云協同關鍵的通信能力,包括方案分發鏈路、數據通信鏈路。
端云協同的模型訓練沉淀在云端,稱為Luoxi-cloud,包含端模型訓練等。
目前,除了前文提到的部署于搜索場景的M6模型、排序模型,研究團隊還借助洛犀完成了圖神經網絡、強化學習等技術在端云協同范式下的部署。
值得一提的是,1月12日,洛犀平臺中云上大模型核心技術“超大規模高性能圖神經網絡計算平臺及其應用”,獲得了2021年中國電子學會科學技術進步獎一等獎。
芥子納須彌,加速大模型落地應用
說了這么多,簡單總結一下就是,大模型展現的效果再怎么驚艷,對于業界而言,終歸是落地應用方為真。
因此,對于大模型發展的下一階段來說,比拼的將不僅僅是誰燒的GPU更多、誰的模型參數規模更大,更會是誰能把大模型的能力充分應用到具體場景之中。
在這個大模型從拼“規模”到拼“落地”的過渡時期,達摩院、浙大、上海人工智能實驗室三方此番提出的“須彌藏芥子、芥子納須彌”的思路,便格外值得關注。
“龐大的須彌山如何納入極微小的種子中?”
對于當下大模型、小模型的思辨而言,解決了這樣一個問題,也就在充分利用大模型能力、探索下一代人工智能系統的路途上更進了一步。
結合歷史上計算形態的變化,隨著物聯網技術的爆發,在當下,盡管云計算模式已經在通信技術的加持下得到了進一步強化,但本地計算需求也在指數級持續涌現,將全部的計算和數據均交由集中式的云計算中心來處理并不符合實際。
就是說,發展既發揮云計算優勢、又調動端計算敏捷性的計算模式,才是當下的需求所在。
也正是在這樣端云協同的趨勢之下,大小模型的協同演進有了新的范式可依:云側有泛化模型,端側有個性化模型,兩個模型相互協作、學習、推理,實現端云雙向協同。
而這,正解決了我們在開頭提到的,大模型落地過程中面臨的性能與能耗平衡之困。
正如浙江大學上海高等研究院常務副院長吳飛教授所言,從大模型到終端可用的小模型,關鍵在于“取其精華、化繁為簡”,實現高精度壓縮;而在端云協同框架之下,小模型的實踐積累對于大模型而言,將是“集眾智者無畏于圣人”。
你覺得呢?
— 完 —
- 蘋果芯片主管也要跑路!庫克被曝出現健康問題2025-12-07
- 世界模型和具身大腦最新突破:90%生成數據,VLA性能暴漲300%|開源2025-12-02
- 谷歌新架構突破Transformer超長上下文瓶頸!Hinton靈魂拷問:后悔Open嗎?2025-12-05
- 90后華人副教授突破30年數學猜想!結論與生成式AI直接相關2025-11-26
相關閱讀