
數(shù)據(jù)縮至1/5000,模型準確率卻翻倍,谷歌新“蒸餾法”火了 | ICLR&NeurIPS
“濃縮的數(shù)據(jù)集才是精華!”
博雯 發(fā)自 凹非寺
量子位 報道 | 公眾號 QbitAI
在煉丹過程中,為了減少訓練所需資源,MLer有時會將大型復雜的大模型“蒸餾”為較小的模型,同時還要保證與壓縮前相當?shù)慕Y果。
這就是知識蒸餾,一種模型壓縮/訓練方法。
不過隨著技術發(fā)展,大家也逐漸將蒸餾的對象擴展到了數(shù)據(jù)集上。
這不,谷歌最近就提出了兩種新的數(shù)據(jù)集蒸餾方法,在推特上引起了不小反響,熱度超過600:
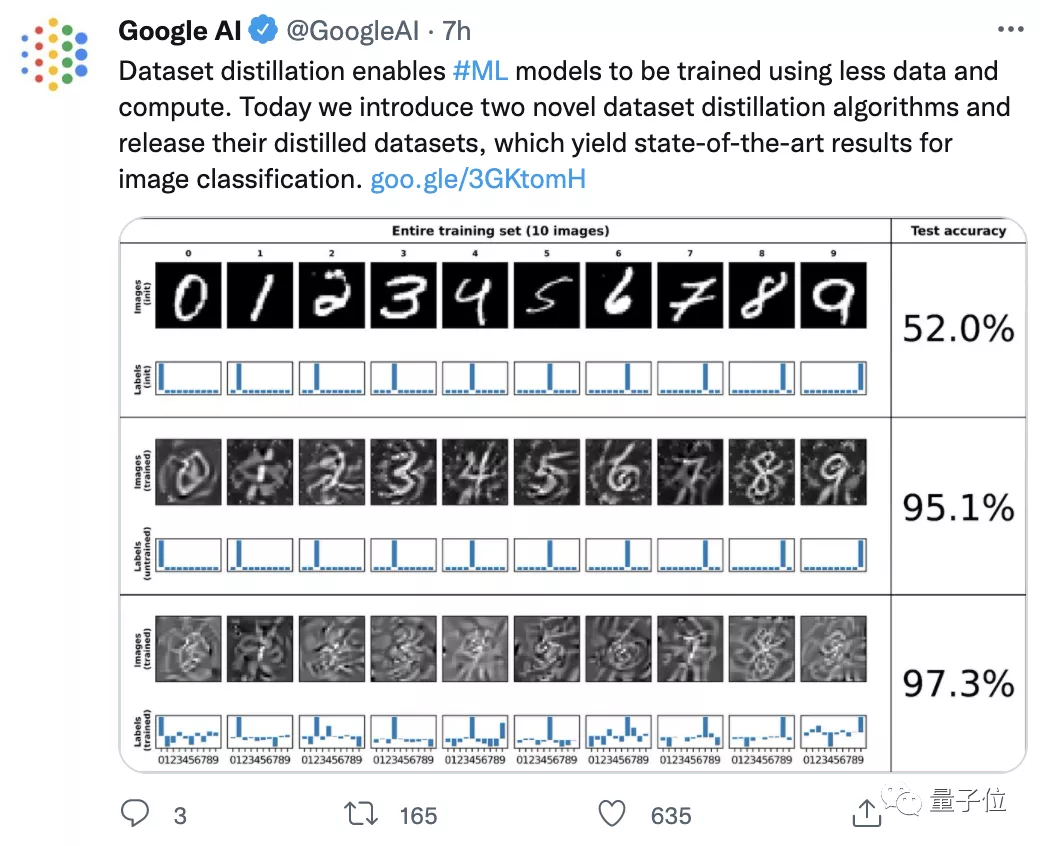
像這樣, 將50000張標注圖像的CIFAR-10數(shù)據(jù)集“蒸餾”縮小至1/5000大小,只基于10張合成數(shù)據(jù)點進行訓練,模型的準確率仍可近似51%:
△上:原始數(shù)據(jù)集 下:蒸餾后
而如果“蒸餾數(shù)據(jù)集”由500張圖像組成(占原數(shù)據(jù)集1%大小),其準確率可以達到80%。
兩種數(shù)據(jù)集蒸餾方法分別來自于ICLR 2021和NeurIPS 2021上的兩篇論文。


通過兩階段循環(huán)進行優(yōu)化
那么要如何才能“蒸餾”一個數(shù)據(jù)集呢?
其實,這相當于一個兩階段的優(yōu)化過程:
- “內部循環(huán)”,用于在學習數(shù)據(jù)上訓練模型
- “外部循環(huán)”,用于優(yōu)化學習數(shù)據(jù)在自然數(shù)據(jù)上的性能
通過內部循環(huán)可以得到一個核嶺回歸(KRR)函數(shù),然后再外部循環(huán)中計算原始圖像標注與核嶺回歸函數(shù)預測標注之間的均方誤差(MSE)。
這時,谷歌提出的兩種方法就分別有了不同的處理路線:
一、標注解釋?(LS)
這種方法直接解釋最小化KRR損失函數(shù)的支持標注集(support labels),并為每個支持圖像生成一個獨特的密集標注向量。
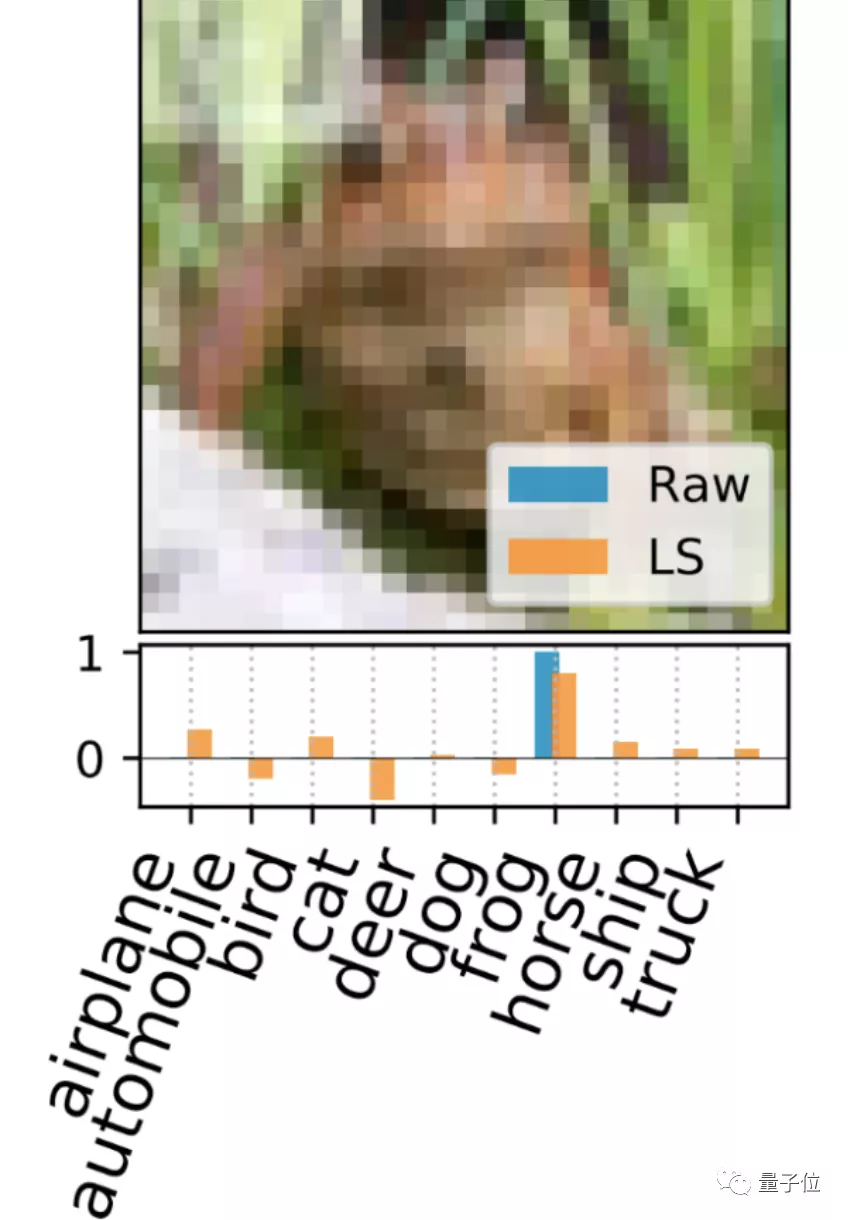
△藍:原始獨熱標注 橙:LS生成的密集標注
二、核歸納點?(KIP)
這種方法通過基于梯度的方法將KRR損失函數(shù)最小化,以此來優(yōu)化圖像和可能生成的數(shù)據(jù)。
以MNIST為例,下圖中的上、中、下三張圖分別為原始的MNIST數(shù)據(jù)集、固定標注的KIP蒸餾圖像、優(yōu)化標注的KIP蒸餾圖像。
可以看出,在于對數(shù)據(jù)集進行蒸餾時,優(yōu)化標注的效果最好:

對比已有的DC(Dataset Condensation)方法和DSP(Dataset Condensation with Differentiable Siamese Augmentation)方法可以看到:
如果使用每類別只有一張圖像,也就是最后只有10張圖像的蒸餾數(shù)據(jù)集,KIP方法的測試集準確率整體高于DC和DSP方法。
在CIFAR-10分類任務中,LS也優(yōu)于先前的方法,KIP甚至可以達到翻倍的效果。
對此,谷歌表示:
這證明了在某些情況下,我們的縮小100倍的“蒸餾數(shù)據(jù)集”要比原始數(shù)據(jù)集更好。
兩位華人作者
整個項目由蕭樂超(Lechao Xiao)、Zhourong Chen、Roman Novak三人合作完成。
其中蕭樂超為LS方法的論文作者之一,本科畢業(yè)于浙江大學的應用數(shù)學系,在美國伊利諾大學厄巴納-香檳分校(UIUC)取得博士學位,現(xiàn)在是谷歌大腦團隊的一名科學家。
他的主要研究方向是數(shù)學、機器學習和深度學習。

另一位華人科學家Zhourong Chen則是KIP方法的論文作者之一,本科畢業(yè)于中山大學,并在香港科技大學取得了計算機科學與工程系的博士學位,現(xiàn)是Google Research的一名軟件工程師。
論文:
[1]https://openreview.net/forum?id=l-PrrQrK0QR
[2]https://openreview.net/forum?id=hXWPpJedrVP
開源地址:
https://github.com/google-research/google-research/tree/master/kip
參考鏈接:
https://ai.googleblog.com/2021/12/training-machine-learning-models-more.html
- 有道智能學習燈發(fā)布,通過“桌面學習分析引擎”實現(xiàn)全球最快指尖查詞2022-04-08
- 科學證明:狗勾真的懂你有多累,聽到聲音0.25秒后就知道你是誰,對人比對狗更親近2022-04-14
- 在M1芯片上跑原生Linux:編譯速度比macOS還快40%2022-04-05
- 小學生們在B站講算法,網(wǎng)友:我只會阿巴阿巴2022-03-28










